CNN
神经网络的每个神经元相当于一个分类器,当检测到对应特征时,这个神经元的激活值就会变得非常大。
越靠前面的层检测的就是越基础的特征,后面的层根据前面层检测到的特征来检测更复杂的特征,如下图,第一个隐含层可以表示最基本的分类器,检测颜色,基本条纹如斜线等。而第二个隐含层就可以通过第一个隐含层检测的特征构建更复杂的分类器,检测各种颜色的条纹等。第三个隐含层就可以检测更复杂的特征如人,轮胎等等。

对于一般的神经网络,如果我们想进行RGB图像识别,第一层的一个神经元的参数就是((length*height*3))参数非常多。根据人对图像的理解,我们检测某个特征不需要检测整张图片,以及图片的放缩不会影响图像识别。因此提出了CNN的概念,来简化普通的神经网络。
DNN(深度神经网络)来进行图像识别的问题
-
某些模式或特征要远远小于整张图片,因此检测这些模式或特征只需要检测整张图的很小的一部分区域。不需要检测整张图像。如我们想检测鸟嘴,值需要检测鸟嘴的那一部分区域即可。

-
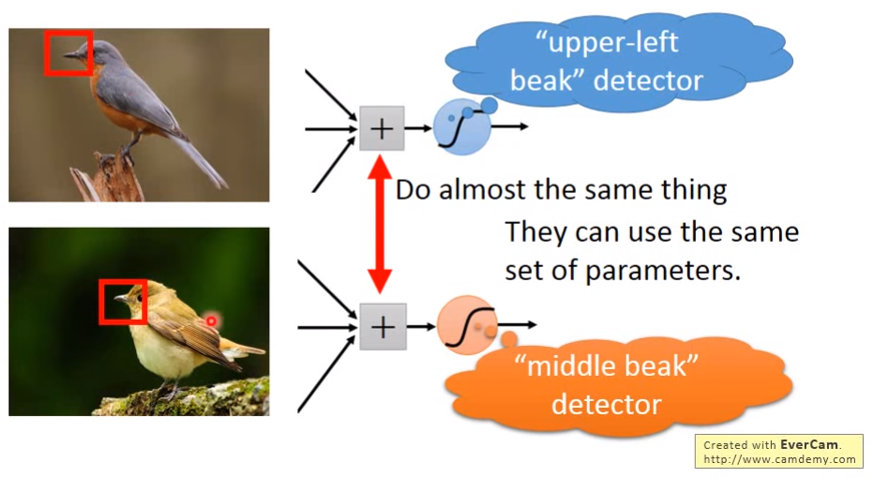
同样的模式或特征会出现在图像的不同的区域,我们不需要对每个不同区域的相同特征都训练一组参数得到一个分类器。如两张图片一个鸟嘴在左上方,一个在中间,我们想只通过一个分类器就能检测出这两个鸟嘴。
-
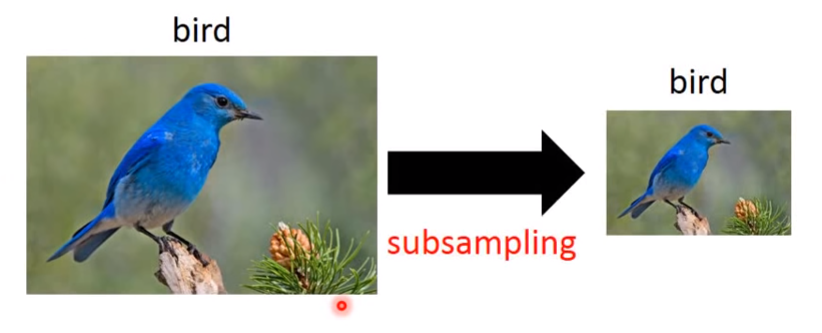
抽掉部分像素不会改变识别对象。即图片的缩放不会影响图片识别。下图为奇数行,偶数列像素抽掉。所以我们可以subsample像素来使图片更小。
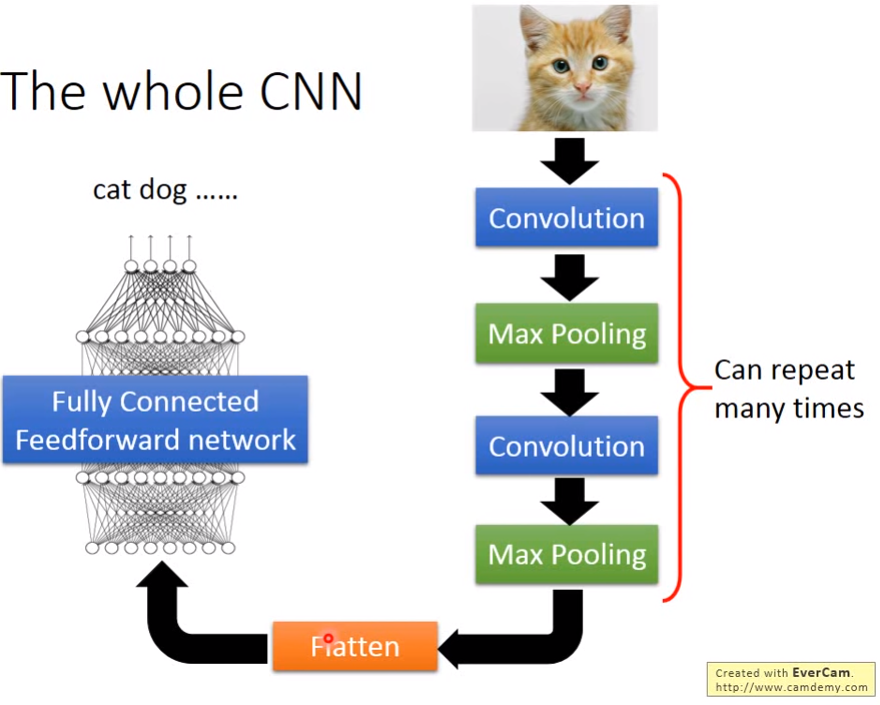
CNN架构
经过一系列卷积池化操作,在将特征拉直到全连接层,最后送到一般的分类器如神经网络,SVM进行分类。而卷积,池化操作分别解决了前面提出的三个问题。
- 通过卷积来解决检测远小于整张图片的模式或特征
- 通过卷积来解决相同模式或特征出现在图片不同位置
- 最大池化操作Subsampling像素而不会改变检测对象
卷积
对于卷积网上又很多很好的解释如 CNN(卷积神经网络)是什么?有何入门简介或文章吗? - 知乎
https://www.zhihu.com/question/52668301

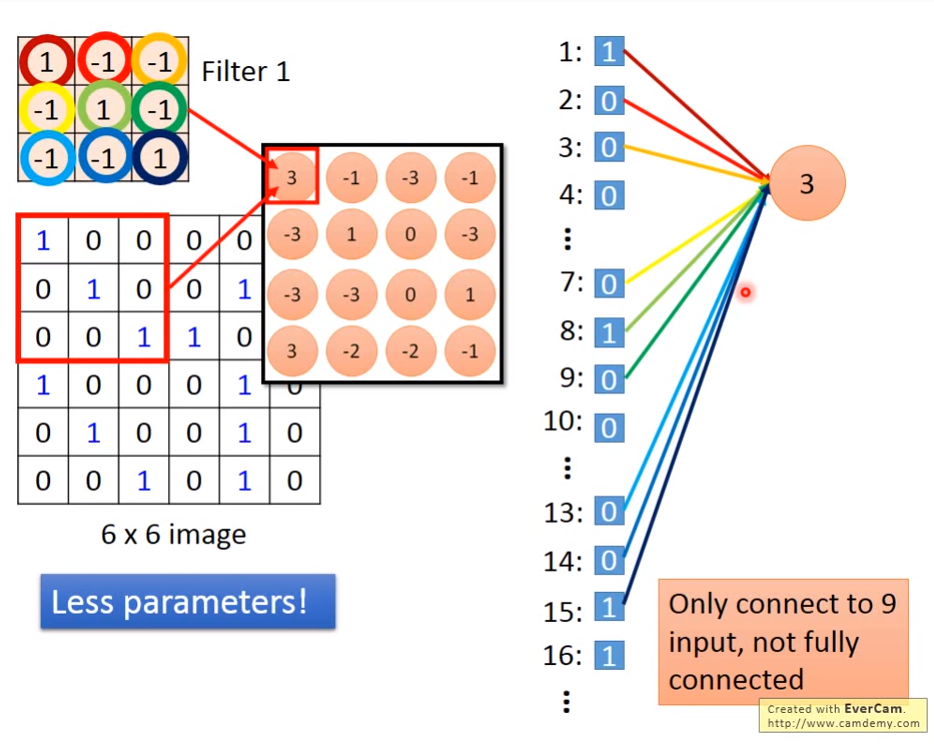
卷积其实跟全连接的神经网络求神经元十分类似,如下图我们求Feature Map的第一个神经元,用的是卷积核的9个参数。但如果在全连接的普通的神经网络中,需要36个参数(整张图片的像素数),今次卷积操作大大减少了参数。通过卷积的特性我们可以看到,卷积可以识别局部特征,因此卷积虽然减少了参数,但不会对图像识别产生影响。
最大池化
这里解释了池化的作用,如轻微的平移不变性,旋转不变性,与尺度不变性。当然池化的主要作用是尺度不变性,即放缩图片不会影响图片识别。平移不变性主要是卷积在起作用,而旋转不变性是小尺度的旋转不变性,大尺度的话可能会失效。(存疑,一些其他观点说CNN的型结构不具有应以不变性,是因为参数的原因,只有通过学习数据才能获得不变性,在全链接层才可能有平移不变的性质。)
还有quora上的一篇回答也探讨了CNN的不变性
https://www.quora.com/How-is-a-convolutional-neural-network-able-to-learn-invariant-features
cnn对图像具有平移不变性,那么利用 图像平移(shift)进行数据增强来训练cnn会有效果吗? - Hengkai Guo的回答 - 知乎
https://www.zhihu.com/question/301522740/answer/531606623
如何理解CNN中的池化? - 康乐的文章 - 知乎
https://zhuanlan.zhihu.com/p/35769417
卷积神经网络提取图像特征时具有旋转不变性吗? - 知乎
https://www.zhihu.com/question/30817011
最大池化操作,可以将Feature Map的大小变小,又因为之前说了SubSampling不会影响图像识别,因此变小Feature Map可以减少参数。
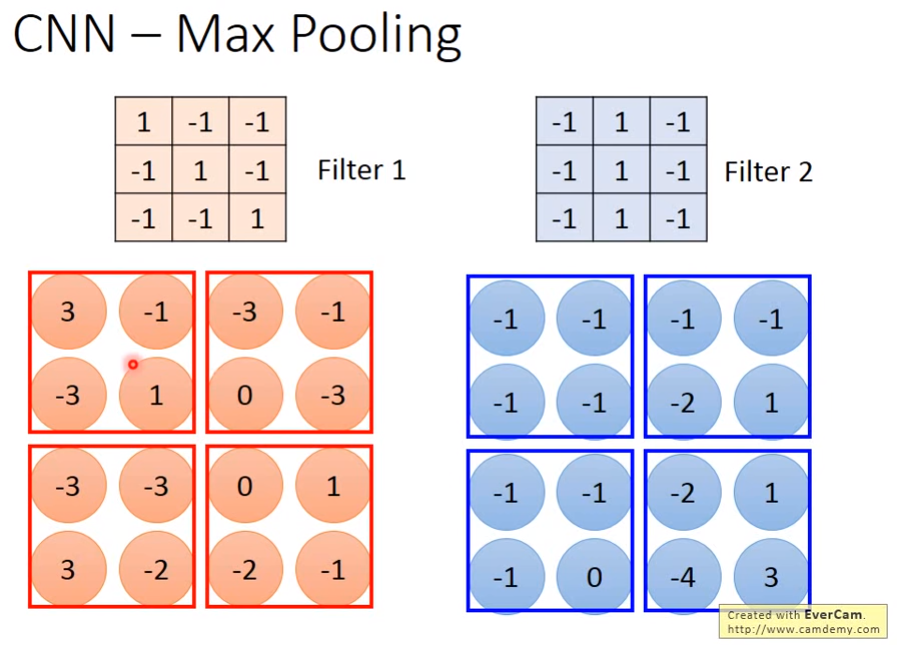
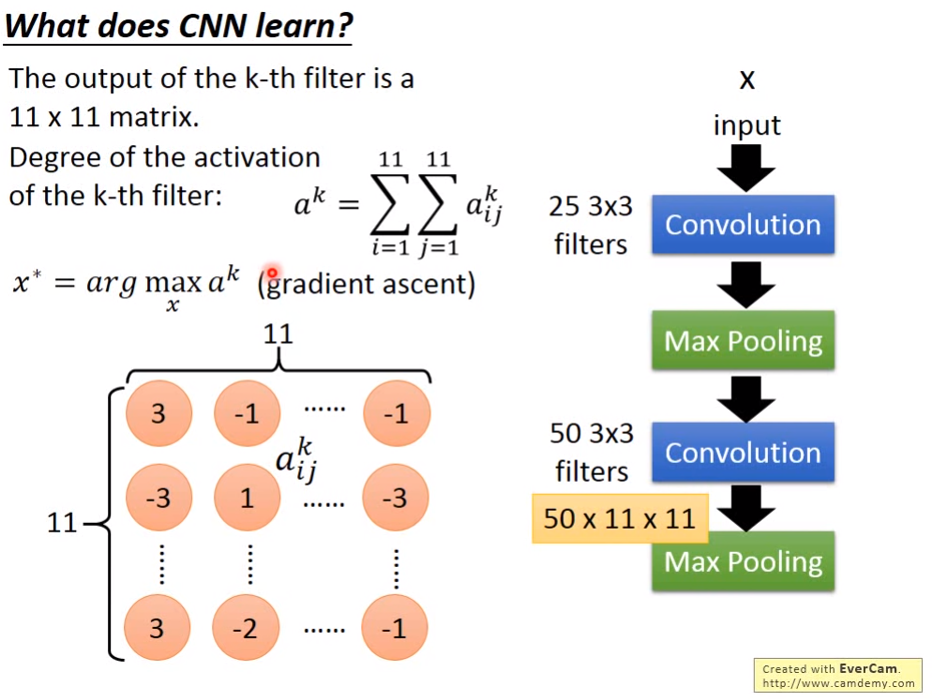
CNN学到了什么
输入X,通过某个卷积核的卷积操作求得FeatureMap,将FeatrueMap的所有值加起来,如果加起来的值非常大,则这个卷积核就是负责激活这种特征。确定参数后,我们可以通过反传播来反推出X,看看X是什么样子
但是结果可以表明,神经网络学到的东西和我们人类观察的东西是不一样的,下面每个类似噪声的图片就表是反推X得到的结果,比一个表示手写数字0,第二个表示手写数字1。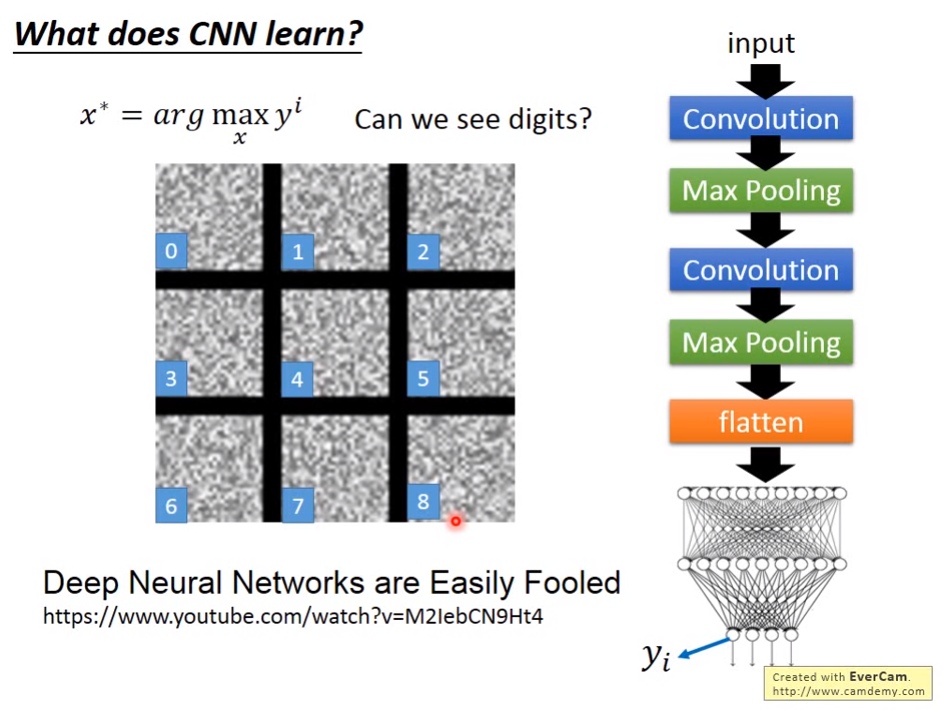
卷积神经网络的其应用
- 风格迁移
- 下围棋
- 语音识别
- 文本检测
参考
李宏毅 机器学习