背景知识
- RNN的应用场景:处理序列数据(一串前后依赖的 数据流)
- RNN的局限:较近的输入的影响较大,较远的输入的影响较小,因此它无法捕捉输入间隔较远的数据之间的联系
- RNN的改进:
- LSTM使网络可以记住之前输入的重要信息,只不是很重要的信息
- GRU(Gated Recurrent Unit)在LSTM的基础上做进一步的简化和调整,使其在训练数据集比较大的情况下可以节省很多时间
- 附:现在提倡用Attention结合Seq2Seq来处理序列信息(参考:https://zhuanlan.zhihu.com/p/35701746)
- 关于RNN的一篇很好的英文教程:The Unreasonable Effectiveness of Recurrent Neural Networks,
基本结构
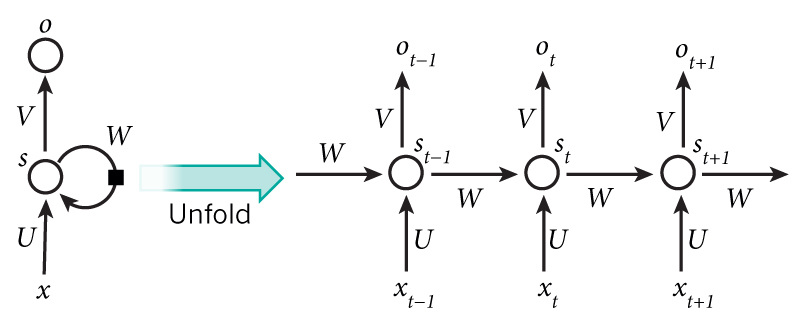
输入单元(Input units)的输入集标记为({x_0,x_1,...,x_t,x_{t+1},...}),而输出单元(Output units)的输出集则被标记为({y_0,y_1,...,y_t,y_{t+1},...}),隐藏单元(Hidden units)的输出集标记为({h_0,h_1,...,h_t,h_{t+1},...}):
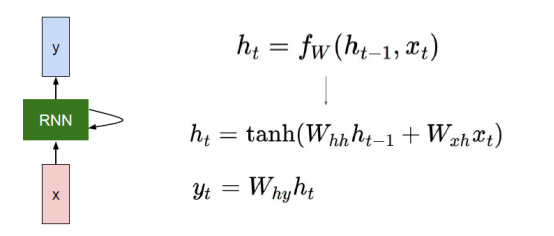
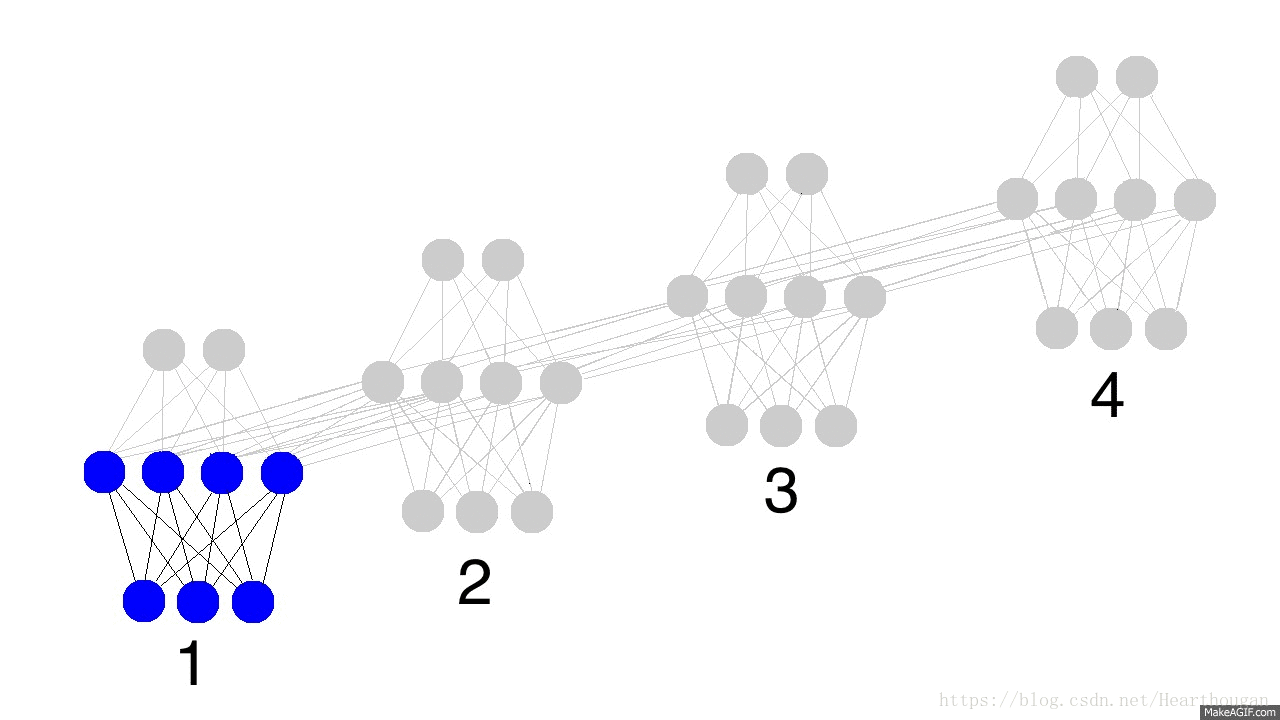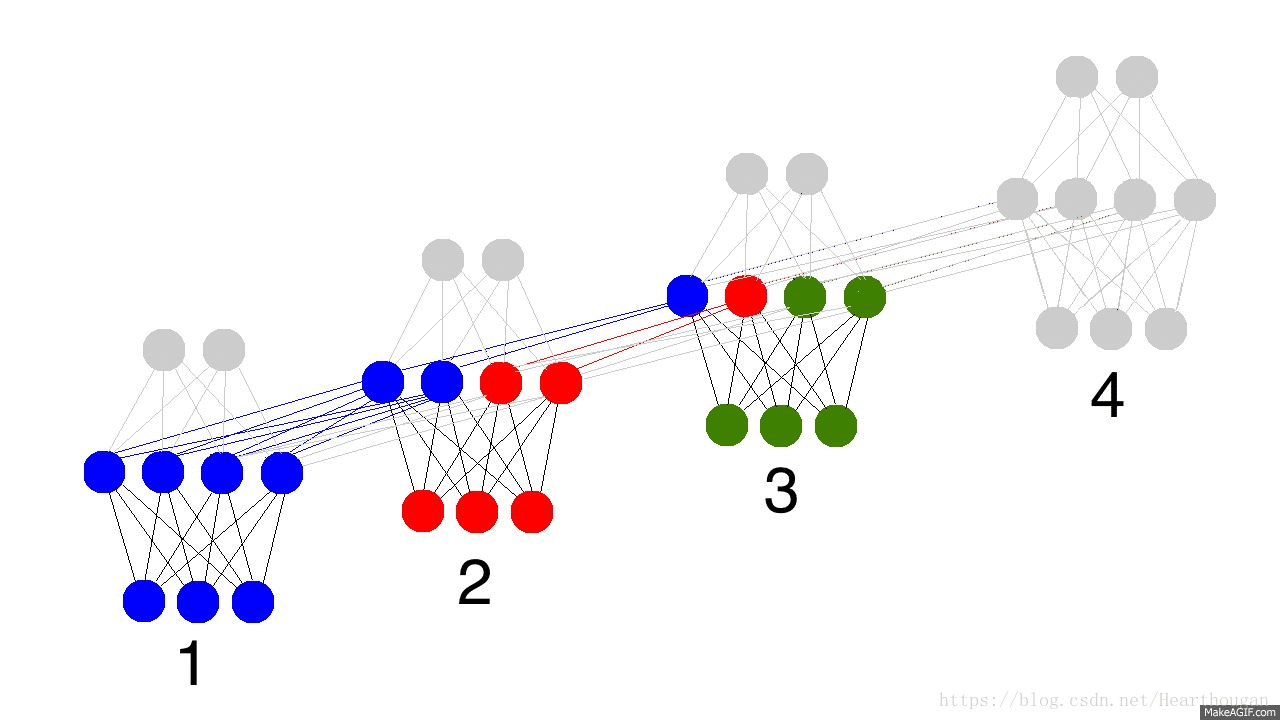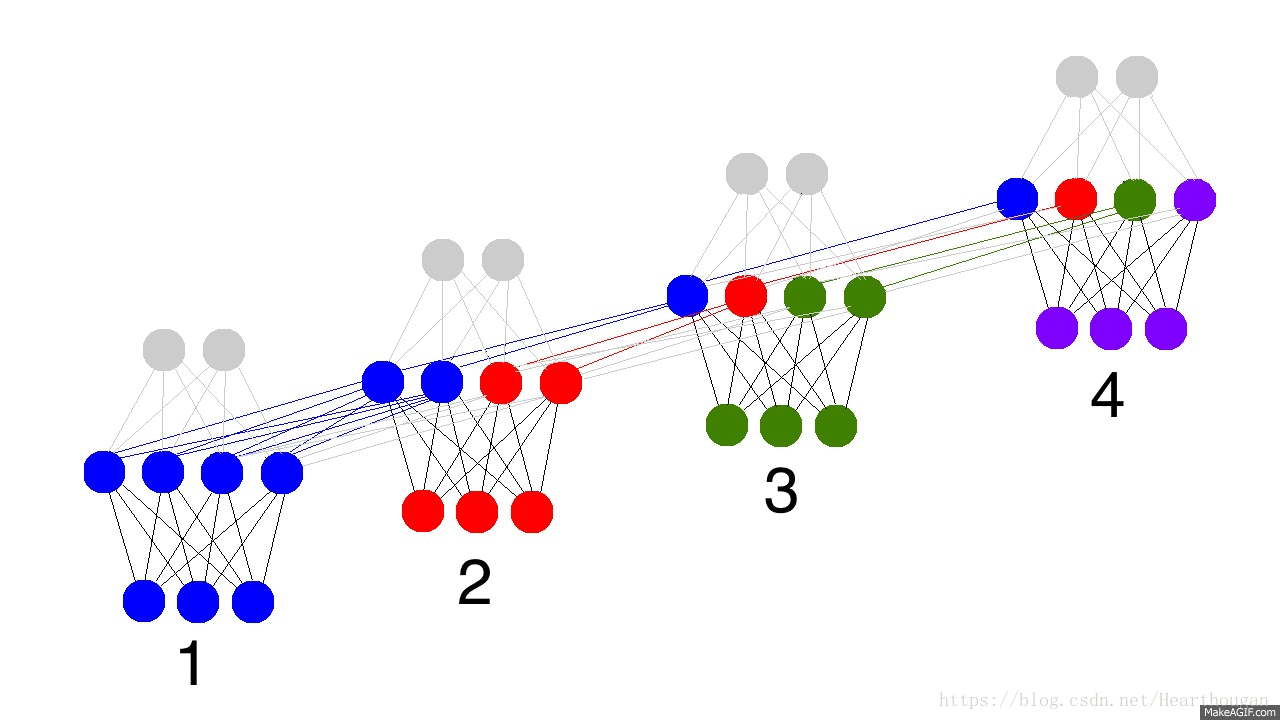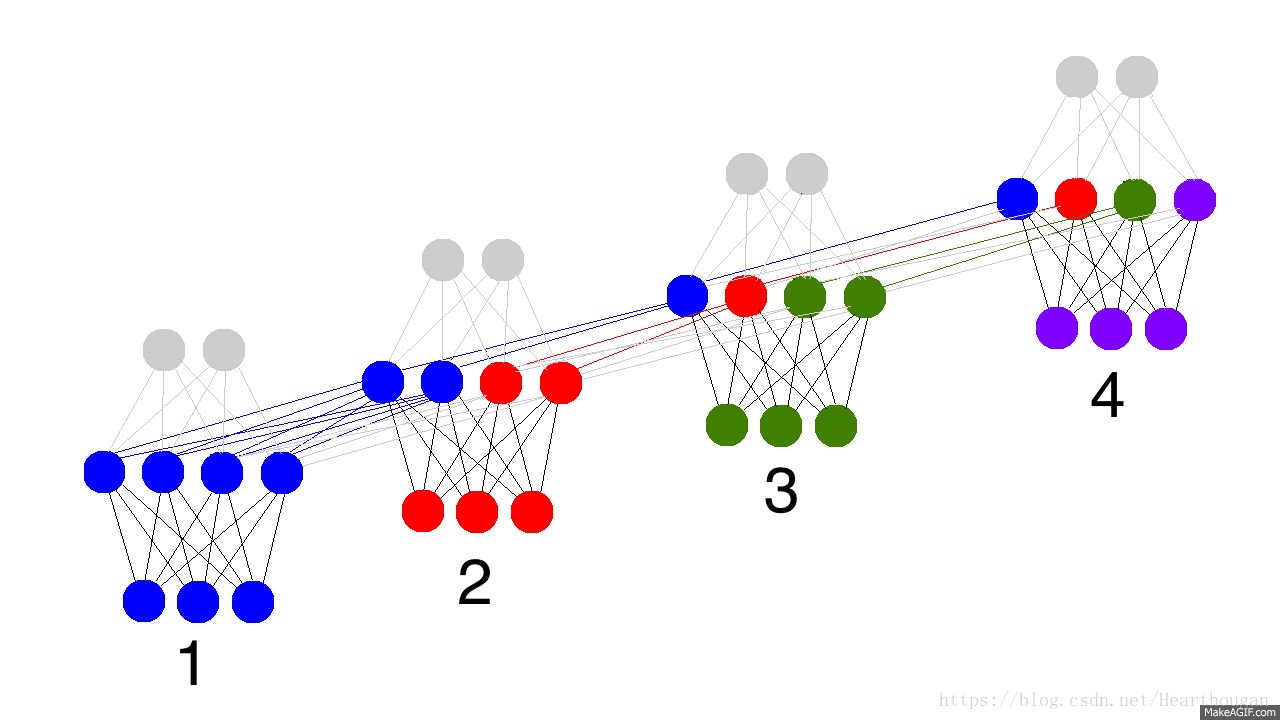
对前向传播过程的详细描述见:详细展示RNN的网络结构
反向传播
RNN反向传播所用的算法被称为:BPTT(BackPropagation Through Time),推导过程可参考:
实现方面可参考:
代码
- 相关文档:torch.nn.RNN
- 简短的例子:
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(2019)
# 超参设置
TIME_STEP = 10 # RNN时间步长
INPUT_SIZE = 1 # RNN输入尺寸
INIT_LR = 0.02 # 初始学习率
N_EPOCHS = 100 # 训练回数
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=INPUT_SIZE,
hidden_size=32, # RNN隐藏神经元个数
num_layers=1, # RNN隐藏层个数
)
self.out = nn.Linear(32, 1)
def forward(self, x, h):
# x (time_step, batch_size, input_size)
# h (n_layers, batch, hidden_size)
# out (time_step, batch_size, hidden_size)
out, h = self.rnn(x, h)
prediction = self.out(out)
return prediction, h
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=INIT_LR)
loss_func = nn.MSELoss()
h_state = None # 初始化隐藏层
plt.figure()
plt.ion()
for step in range(N_EPOCHS):
start, end = step * np.pi, (step + 1) * np.pi # 时间跨度
# 使用Sin函数预测Cos函数
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32, endpoint=False)
x_np = np.sin(steps)
y_np = np.cos(steps)
x = torch.from_numpy(x_np[:, np.newaxis, np.newaxis]) # 尺寸大小为(time_step, batch, input_size)
y = torch.from_numpy(y_np[:, np.newaxis, np.newaxis])
prediction, h_state = rnn(x, h_state) # RNN输出(预测结果,隐藏状态)
h_state = h_state.detach() # 这一行很重要,将每一次输出的中间状态传递下去(不带梯度)
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 绘制中间结果
plt.cla()
plt.plot(steps, y_np, 'r-')
plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
plt.draw()
plt.pause(0.1)
plt.ioff()
plt.show()
参考: