稍微了解有监督机器学习的人都会知道,我们先通过训练集训练出模型,然后在测试集上测试模型效果,最后在未知的数据集上部署算法。然而,我们的目标是希望算法在未知的数据集上有很好的分类效果(即最低的泛化误差),为什么训练误差最小的模型对控制泛化误差也会有效呢?这一节关于学习理论的知识就是让大家知其然也知其所以然。
学习理论
1.empirical risk minimization(经验风险最小化)
假设有m个样本的训练集,并且每个样本都是相互独立地从概率分布D中生成的。对于假设h,定义training error训练误差(或者叫empirical risk经验风险)为:h误分类样本占整个训练集的比重:
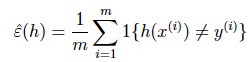
另外,定义generalization error泛化误差为:从生成训练集的概率分布D中生成新的样本,假设h误分类的概率
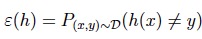
值得注意的是:假设训练集与新的样本都相互独立地由同一个分布D产生(IID独立同分布)是学习理论里重要的基础。 当我们选择模型参数时使用如下方法:

就是所谓的经验风险最小化(empirical risk minimization),经验风险最小化是一个非凸优化问题难以求解,而logistic回归与SVM可以看做这个问题的凸优化近似。
为了使得定义更加一般化(不仅限于线性分类器参数θ的选择),我们定义hypothesis class H为一个学习算法所考虑的所有分类器(函数h),则经验风险最小化变为:
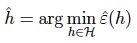
2.最小化经验风险与最小化泛化误差的关系
2.1 对于有限的H
这里将直接给出公式推导的结论,具体的步骤可参考cs229课程笔记。首先,根据union bound Lemma与Cherno bound Lemma可以推出:
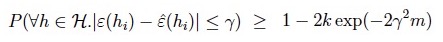
该式被称为uniform convergence,其中k为H中包含的模型假设数量。再将使得经验风险最小化的假设与使得泛化误差最小化的假设带入,可得:
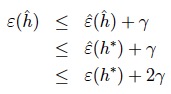
也就是说,在uniform convergence的前提下,通过最小化经验风险选出的模型的泛化误差与最小化泛化误差模型的分类准确度只差2γ。 由此,有定理:设H中包含的假设数量为k样本量为m,则至少在1-δ的概率下我们有:
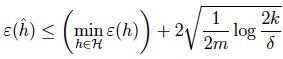
有了这个定理,就可以更全面地理解Andrew所说的bias与variance(与概率中的方差无关)
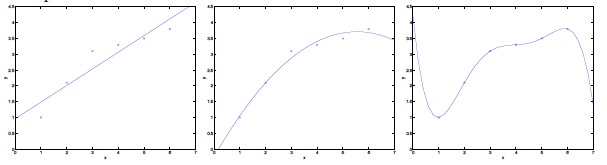
最左边的图对应着high bias,因为hypothesis class中可选的假设少,因此即使大大提升样本量也无法降低最小泛化误差,这种现象对应着欠拟合; 最右边的图对应着high variance,因为增大了hypothesis class(增加了参数),因此min ε(h)肯定会下降或者保持不变,但是k增大将导致γ也增大,尤其是当m很小时将有可能导致虽然经验风险很小但是泛化误差依然很大,这种现象对应着过拟合。 而最好的方案是在high bias与high variance之间做好折中,即对应着中间那副图。 最后还有一个用于求样本复杂度的推论:设H中包含的假设数量为k,则至少在1-δ的概率下,要使最小化经验风险的泛化误差与最小泛化误差的差值小于等于γ,需要确保样本量:
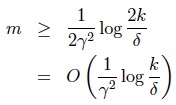
2.2 对于无限的H
在大多数情况下,H包含的假设都是无限的,因此有必要把上一小节的结论推广至无限的H中,但是证明步骤过于复杂因此Andrew也略过了证明过程。在介绍定理前需要先说一下 Vapnik-Chervonenkis dimension(VC维度):首先定义shatter:给定样本集S,H shatters S是指H可以划分出S上所有的标记。而H的VC维度VC(H)则定义为:能被H shatter的最大集合的样本量。举例来说,对下图集合中的三个点:

h(x) = 1{θ0 + θ1x1 + θ2x2 ≥0} 可以shatter这三个点: 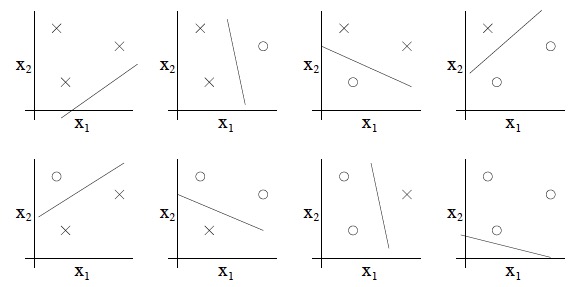
并且这个H无法shatter4个点的集合,因此VC(H)=3。 定理:对于给定的H,h∈H,d=VC(H),在至少1-δ的概率下,我们有: 
回忆一下,svm通过核函数可以使用无限维度的特征,那么是否会出现过拟合?Andrew给出的答案是不会:可以证明svm的VC维度是有上界的(即使特征向量的维度是无限的),因此variance不会过大。 推论:在至少1-δ的概率下,要使最小化经验风险的泛化误差与最小泛化误差的差值小于等于γ,则样本量m的复杂度为Oγδ(d)。 如果严格按照推论得到的公式来计算所需要的样本量,通常会发现根本无法取得如此大的样本量。但是Andrew提到一个粗略估计的方法:要使得算法学习得比较好,需要训练集的样本量m与VC(H)是线性关系;而对于大多数H,VC(H)又大致与模型参数的个数线性相关;联合起来就是,通常需要的训练集样本量应该大致与模型参数的个数为线性关系。 最后,Andrew还提到了自己的经验:做逻辑回归,训练集样本量为参数个数的10倍时,通常就可以拟合出不错的边界,即使只有不到十倍,也还可以接受。
模型选择
1.cross validation交叉验证
1.1 hold-out cross validation
- 随机地将样本集划分成训练集(通常是70%的样本量)与测试集(剩下的30%)
- 在训练集上对每个候选假设进行训练得到相应的模型
- 选出能使测试集上经验风险最小的模型为最优模型
- 对初始条件扰动不敏感的模型,还可以在整个样本集中重新训练模型(可选)
这种方法的优点是每个模型只需要训练一次,成本比较低;缺点是只利用了70%的样本进行训练。当样本数据很多时可以使用,当样本数据很稀有(比如只有20个)应考虑其他方法。
1.2 k-fold cross validation
- 随机地将样本集S划分成k个子集S1,...,Sk,每个子集的样本量为m/k(k通常取10)
- 训练与验证模型的方法为:

- 选出泛化误差估计值最小的模型,并在样本集S中重新训练模型
与hold-out cross validation相比,这种方法成本较高,对每个模型要训练k次;但是更充分地利用了样本进行模型的训练。对于样本量极其稀缺的情况,还有一种更极端的做法。
1.3 leave-one-out cross validation
步骤同k-fold cross validation,不过令fold的数量k等于样本量m。
2.特征选择
当特征数非常多时,很容易出现过拟合的现象,因此特征选择十分有必要。对于n个特征的模型,将会有2n种可能的特征子集,一些启发式的搜索过程可以被用来寻找好的特征子集:
2.1 forward search
- 初始化的特征空间F = ∅
- repeat { for i = 1,...,n if i ∉ F, 令Fi = F ∪ {i} 并通过交叉验证来评估Fi的效果 从上一步中选出效果最好的Fi作为新的F }
- 选出循环过程中,效果最好的特征子集
最外层的循环终止条件可以是遍历完所有的特征组合,或者特征空间的维数|F|达到了某个预设的值(比如:从1000个特征中选出100个)。
2.2 backward search
与forward search基本一致,只不过初始特征空间变为所有特征:F={1,...,n},终止条件变为F=∅,循环中每次从特征空间中删去一个特征。 以上两种方法又被称为wrapper model feature selection,不过这类方法的计算成本较高,如果完全遍历整个特征空间,则计算复杂度为O(n2)。
2.3 Filter feature selection
- 为每个特征xi计算一个评分S(i)来衡量其对分类标签y预测的信息贡献程度
- 选出评分S(i)最高的k个特征(可以通过交叉验证确定k的取值)
评分S(i)可选的一种计算方案是:xi与y的相关性。在实践中,最常用的相关性计算是mutual information(尤其是对离散型的特征): 
这个公式要求特征变量与类标签变量都是二元的,这个公式给出了“p(xi, y)与p(xi)p(y)有多么的不同”:如果xi与y是相互独立的,那么p(xi, y) = p(xi)p(y),MI(xi, y)=0,也就是说xi对y不贡献任何信息,因此评分应该小。 对于用朴素贝叶斯做文本分类,默认的特征空间大小是词汇表的大小n(通常非常大),而使用特征选择经常能够增加分类的准确性。
贝叶斯统计正则化
为了防止过拟合,特征选择做的事情是使得模型更加简单,而正则化则可以在保留所有参数的前提下防止过拟合: 以线性回归为例,我们之前的做法是通过极大化似然函数求得最优的模型 
其背后的逻辑是:存在一个最优的参数组合θ,而我们可以通过极大化似然函数来找到它。这是频率学派(frequentist)的观点。 而贝叶斯学派(Bayesian)则认为θ也是一个随机变量,为了进行预测,我们先假设一个θ的先验分布p(θ),给定一个样本集后,我们可以求得θ的后验分布: 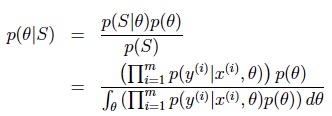
当给定一个新的样本x,我们要预测它的结果时,可以得到结果的分布为: 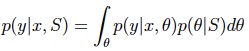
我们可以通过分布的期望给出预测: 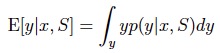
然而,要在很高的维度上求积分是一件困难的事,因此上面的步骤将变得难以计算。所以我们转而去求θ的后验分布中概率最大的θ,即MAP(maximum a posteriori): 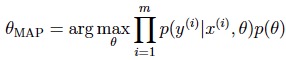
最后通过θMAP进行预测。 在实践中,θ的先验分布p(θ)通常被假设为θ ~ N(0, τ2 I),而使用贝叶斯MAP估计求θ与使用最大化似然函数的区别,表现在损失函数上就是前者比后者多了一个惩罚项: 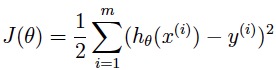
+ λ ||θ||2 (λ=1/τ2) 通过这样的正则化后,模型将更不容易过拟合,比如:贝叶斯逻辑回归也被证明是一个高效的文本分类算法,即使在文本分类中通常存在n >> m。
4.online learning
为了体现课程体系的完整性,因此将这块知识放到最后,并且只做了简单介绍。 之前我们学习的算法,都是先用一批样本训练好模型后再对新的数据进行预测,这称为batch learning; 而还有一种算法,是一边学习一边预测,即每新增一个数据就进行一次新的训练,并且马上给出预测,这称为online learning。 之前学到的每一种模型都可以做online learning,不过考虑到实时性,并不是每个模型都可以在短时间内被更新好且进行下一次预测,而感知机算法十分适合做online learning:
参数更新的方法为: 如果hθ(x) = y 则预测准确,参数不更新 否则,θ := θ + yx (其实这个式子和梯度下降的更新策略是一样的,只不过类标号改为了{1,-1}且学习速率α不会影响感知机的表现因此被去掉了) 最后,假设||x(i)|| ≤ D,且存在一个单位向量u(||u|| = 1)且y(i) (uTx(i)) ≥ γ(其实就是svm的模型,u能以几何间隔γ分隔所有数据),还可以证明感知机在线算法预测错误的总数量将小于等于(D/γ)2。