一直听闻Logistic Regression逻辑回归的大名,比如吴军博士在《数学之美》中提到,Google是利用逻辑回归预测搜索广告的点击率。因为自己一直对个性化广告感兴趣,于是疯狂google过逻辑回归的资料,但没有一个网页资料能很好地讲清到底逻辑回归是什么。幸好,在CS229第三节课介绍了逻辑回归,第四节课介绍了广义线性模型,综合起来总算让我对逻辑回归有了一定的理解。与课程的顺序相反,我认为应该先了解广义线性模型再来看逻辑回归,也许这也是为什么讲逻辑回归的网页资料总让人感觉云里雾里的原因吧。
Generalized Linear Model (GLM) 广义线性模型
这一段主要讲的是广义线性模型的定义和假设,为了看明白逻辑回归,大家要耐着性子看完。
1.The exponential family 指数分布族
因为广义线性模型是围绕指数分布族的,因此需要先介绍,用NG大神的话说就是,“虽然不是全部,但是我们见过的大多数分布都属于指数分布族,比如:Bernoulli伯努利分布、Gaussian高斯分布、multinomial多项分布、Poisson泊松分布、gamma分布、指数分布、Dirichlet分布……”
服从指数分布族的条件是概率分布可以写成如下形式: 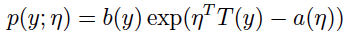
η 被称作natural parameter,它是指数分布族唯一的参数 T(y) 被称作sufficient statistic,很多情况下T(y)=y a(η) 被称作 log partition function T函数、a函数、b函数共同确定一种分布 接下来看一下为什么说正态分布(高斯分布)属于指数分布族: 正态分布(正态分布有两个参数μ均值与σ标准差,在做线性回归的时候,我们关心的是均值而标准差不影响模型的学习与参数θ的选择,因此这里将σ设为1便于计算) 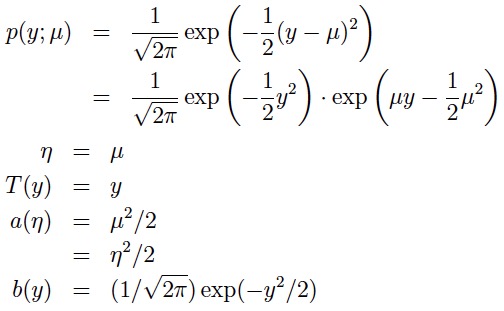
2.构成广义线性模型的三个假设
- p(y | x; θ) ∼ ExponentialFamily(η). 输出变量基于输入变量的条件概率分布服从指数分布族
- our goal is to predict the expected value of T(y) given x. 对于给定的输入变量x,学习的目标是预测T(y)的期望值,T(y)经常就是y
- The natural parameter η and the inputs x are related linearly: η = θT x. η和输入变量x的关联是线性的:η = θT x
这三个假设其实指明了如何从输入变量映射到输出变量与概率模型,举例来说:线性回归的条件概率分布为正态分布属于指数分布族(参考笔记一中线性回归的似然函数部分);我们的目标是预测T(y)的期望,由上面的计算我们知道T(y)=y,而y的期望值也就是正态分布的参数μ;由上面的计算我们知道μ=η,而η=θT x。因此,线性回归是广义线性回归的一个特例,它的模型是: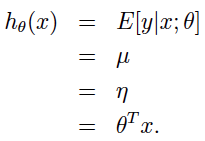
Logistic Regression 逻辑回归
1.模型
逻辑回归解决的是分类问题,并且是只分为两类。比如:用户是否会点击广告链接?用户是否会回访?抛一枚硬币正面是否会朝上?于是,从概率的观点出发,我们应该马上想到用伯努利分布来估计事件发生的概率。从广义线性模型的角度来构造逻辑回归模型: 1.1 伯努力分布属于指数分布族(参数Φ指的是y=1的概率,即事件发生的概率)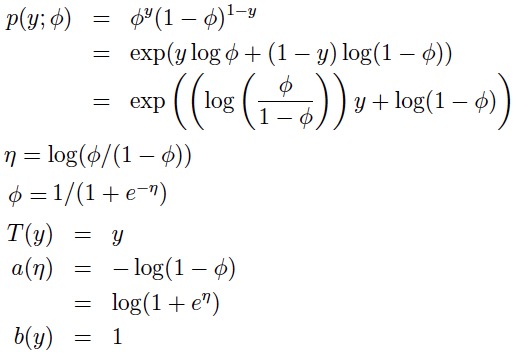
1.2 学习的目标是预测T(y)的期望值,而伯努利分布中T(y)=y,另外我们知道伯努利分布的期望就是参数Φ,即E(y)=Φ。 1.3 由η = log(Φ/(1 - Φ) 可以推出 Φ = 1/(1+e-η) (这就是所谓的logistic函数,也是逻辑回归名字的来由),再将η=θT x带入公式,最终我们得到逻辑回归的模型: 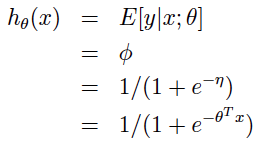
因为伯努利分布的参数Φ既是分布的期望,又代表事件发生的概率,因此逻辑回归模型的意义就是:在给定的输入变量组合的条件下,输出变量(二元变量)中一个事件发生的概率。比如:预测在用户是第一次来访(输入变量1),广告链接用的是热门文案(输入变量2)的条件下,广告链接被点击(输出变量)的概率为多少。 看到这里,相信大家应该能够明白:为什么逻辑函数要长成这样,为什么逻辑回归能起作用了吧。
2.策略
逻辑回归使用的策略是最大化对数似然函数,它的似然函数与对数似然函数分别为: 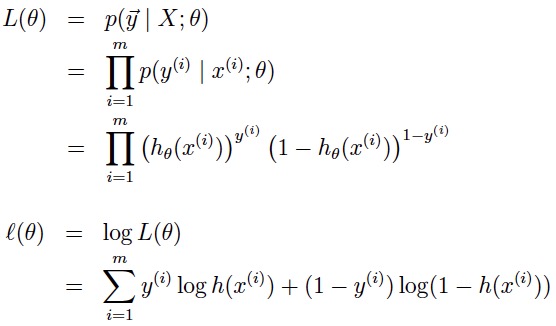
3.算法
3.1 gradient ascent 梯度上升 我们可以用梯度下降找到极小值的点,反过来也可以用梯度上升找到极大值的点: 首先补充一下计算中要用到的逻辑函数,与逻辑函数的导数: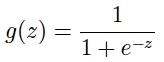
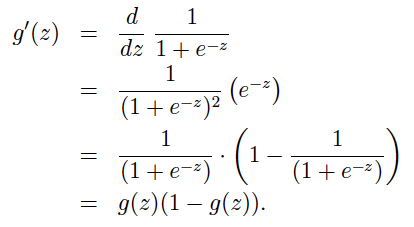
在此基础上我们对对数似然函数求导获得梯度 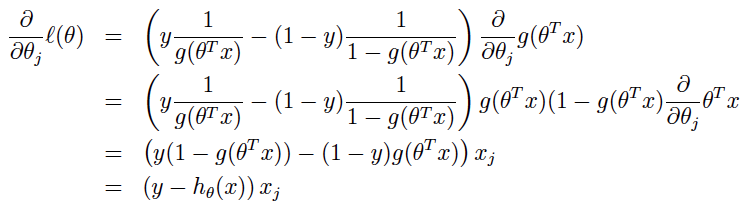
这个导数和线性回归中的导数如出一辙,但是要注意两者的模型hθ(x)是不一样的,所以最终采用随机梯度上升的迭代规则如下: 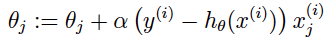
3.2 Newton’s method 牛顿方法 从高数中知道极值点就是导数为0的地方,所以最大化对数似然函数的另一个求法是求对数似然函数导数为0的点。而牛顿方法就是求得对数似然函数导数为0的点的方法: 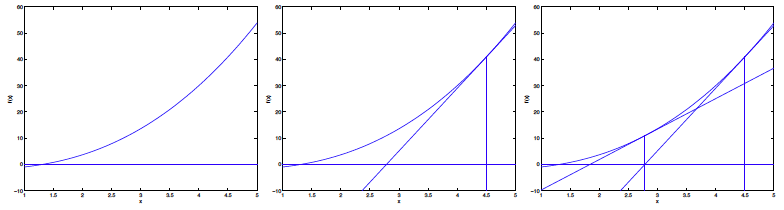
当参数θ只有一个时,牛顿方法的迭代规则: 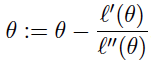
当参数θ不止一个时,牛顿方法的迭代规则: 
相较于批量梯度下降,牛顿方法通常来说有更快的收敛速度,只需要少得多的迭代次数就能得到很接近最小值的结果。但是当模型的参数很多时(参数个数为n)Hessian矩阵的计算成本将会很大,导致收敛速度变慢,但是当参数个数不多时,牛顿方法通常是比梯度下降快得多的。
总结
- 原来这么多主流的概率分布都属于指数分布族
- 记住构成广义线性模型的三个假设,其实也是构建模型的桥梁
- 理解逻辑回归模型是基于伯努利分布的概率模型,它的意义是:在给定的输入变量组合的条件下,输出变量(二元变量)其中一元发生的概率。也因此它适合用来预测广告点击率。
- 有梯度下降算法也有梯度上升算法,两者的区别只在+/-号上。此外,还可以使用牛顿方法,通过获得导数为0的点以确定模型的极大/极小值。