sed命令
stream editor,用程序的方式编辑文本。基本上是玩正则模式匹配。
用s命令替换
$ sed "s/my/Hao Chen's/g" pets.txt
-
单引号去除所有字符的特殊意义,双引号保留某些字符的特殊意义
-
默认是将处理过的内容输出,可以加-i参数直接修改原文件
$ sed -i "s/my/Hao Chen's/g" pets.txt -
在每行的最前面加东西
$ sed 's/^/#/g' pets.txt -
在每行的最后面加东西
$ sed 's/$/ --- /g' pets.txt -
正则表达式基本
^ 一行的开头 $ 一样的结尾 < 词首 > 词尾 . 任意单个字符 * 某个字符出现0次或多次 [] 集合,[^]取反 -
去除<>中的tags
$ sed 's/<[^>]*>//g' html.txt -
只替换第3到6行
$ sed "3,6s/my/your/g" pets.txt -
只替换第一个
$ sed 's/s/S/1' my.txt -
只替换第3个以后的
$ sed 's/s/S/3g' my.txt -
&可以作为被匹配的变量
$ sed 's/my/[&]/g' my.txt给my加上[]
多个匹配
- 分号分割
sed '1,3s/my/your/g; 3,$s/This/That/g' my.txt前3行一个操作,后面一个操作 - -e参数
sed -e '1,3s/my/your/g' -e '3,$s/This/That/g' my.txt
圆括号匹配
- 圆括号内匹配的字符串可以当变量使用1,2
$ sed 's/This is my ([^,&]*),.*is (.*)/1:2/g' my.txt
sed多行匹配
sed -e ":begin; /<<</,/>>>/ { />>>/! { $! { N; b begin }; }; s/<<<.*>>>/COMMENT/; };" test
:begin;标记开头
/<<</,/>>>/ 表示后面的命令只处理<<<和>>>之间的部分,
后面的/>>>/! 表示如果当前行没有匹配到结束标记/>>>/
$代表文本的最后一行,$!表示如果当前不是最后一行
N 将下一行内容追加到缓冲区,相当于"合并"成一行
b begin 表示跳回begin处重新开始执行命令
s/<<<.*>>>/COMMENT/; 终于匹配成功,将<<<到>>>之间的内容替换为COMMENT
sed的命令
- N命令:把偶数行的内容接到奇数行进行匹配,即两两合并,
分隔
$ sed 'N;s/ /,/' pets.txt连接两行,用逗号分隔 - a命令和i命令:插入和追加
# 第一行前插入一行
$ sed "1 i This is my monkey, my monkey's name is wukong" my.txt
#最后一行后追加一行
$ sed "$ a This is my monkey, my monkey's name is wukong" my.txt
#匹配到/fish/后追加一行
$ sed "/fish/a This is my monkey, my monkey's name is wukong" my.txt
- c命令:替换匹配行
$ sed "2 c This is my monkey, my monkey's name is wukong" my.txt
$ sed "/fish/c This is my monkey, my monkey's name is wukong" my.txt
- d命令:删除匹配行
$ sed '/fish/d' my.txt
$ sed '2d' my.txt
$ sed '2,$d' my.txt
- p命令:打印
# 默认会打印处理的信息
$ sed '/fish/p' my.txt
# -n参数只打印匹配的信息
$ sed -n '/fish/p' my.txt
# 打印从一个模式到另一个模式的信息
$ sed -n '/dog/,/fish/p' my.txt
#从第一行打印到匹配fish成功的那一行
$ sed -n '1,/fish/p' my.txt
知识点
-
pattern space
sed处理文本的伪代码 ``` 对文件中每行数据 { 将一行数据放入pattern_space 对每个pattern space执行sed命令 如果没有指定-n则输出处理后的pattern space } ``` -
Address
[address[,address]][!]{cmd}
address可以是一个数字,也可以是一个模式
# 可以使用相对位置
$ sed '/dog/,+3s/^/# /g pets.txt'
- 命令打包
可以用分号分隔,也可以用大括号嵌套
# 第3到6行删除This的行
$ sed '3,6 {/This/d}' pets.txt
# 第3到6行匹配了This,再匹配fish,则删除
$ sed '3,6 {/This/{/fish/d}}' pets.txt
# 从第一行到最后一行,如果匹配到This,则删除之;如果前面有空格,则去除空格
$ sed '1,${/This/d;s/^ *//g}' pets.txt
-
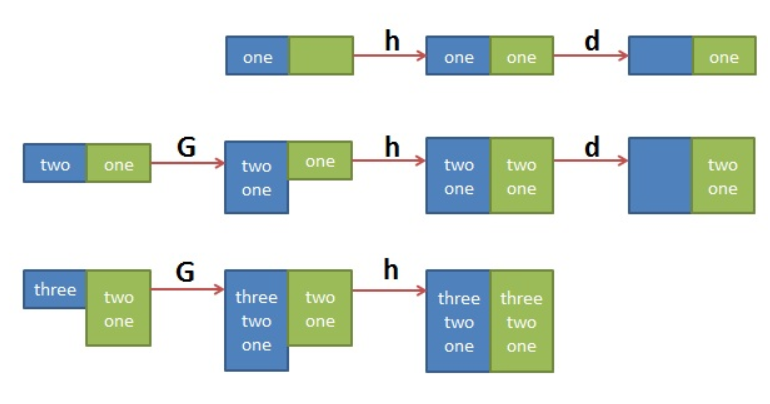
Hold Space不同行操作之间保持状态
g: hold space > pattern space中 G: hold space >> pattern space 之后附加 h: pattern space > hold space H: pattern space >> hold space 之后附加 x: 交换pattern space和hold space的内容
例如有如下文本
$ cat t.txt
one
two
three
$sed 'H;g' t.txt
one
one
two
one
two
three
分析
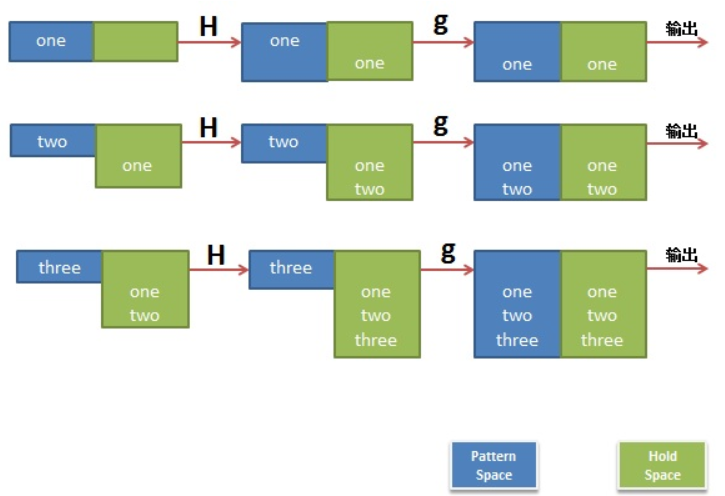
例子2(反序输出)
$ sed '1!G;h;$!d' t.txt
three
two
one
命令可以拆解为3个
- 1!G--只有第一行不执行G,将hold space附加到pattern space
- h--每一行都执行h,将pattern space覆盖hold space
- $!d--最后一行不执行d,其余都清空pattern space
分析