简介
Husky是一个大数据分布式开发框架,用C++开发,因为粗粒度(coarse-grained)平台(如Spark,Hadoop,Flink)MR耗时太大,然后细粒度(fine-grained)平台(GraphX等)编程难度较大,同时细粒度在数据平台之间转移会很耗时。Husky就是在粗粒度和细粒度之间做一个权衡,在PageRank上,他的性能是Spark的30+倍。
Husky主页:http://www.husky-project.com/
升级gcc到5.3
参见博客 http://www.cnblogs.com/loadofleaf/p/5667989.html
安装必要的基础库
1 apt-get update -y 2 apt-get install software-properties-common -y 3 apt-get install build-essential libgoogle-perftools-dev libboost-dev git -y
编译安装cmake 3.x
1 wget https://cmake.org/files/v3.6/cmake-3.6.0.tar.gz 2 tar xf cmake-3.6.0.tar.gz 3 cd cmake-3.6.0/ 4 ./bootstrap 5 make -j4 6 sudo make install
cmake 版本查看

编译安装boost1.58
查看博客 http://www.cnblogs.com/loadofleaf/p/5668109.html
编译安装zeromq4.1.5(Husky一定要zeromq4以上,3版本无法运行)
1 sh autogen.sh 2 ./configure 3 #cp /usr/bin/libtool . 4 make 5 sudo make install
6 sudo ldconfig
git cppzmp(Husky底层通信机制是采用zeromq的)
1 mkdir tmp 2 cd tmp 3 git clone https://github.com/zeromq/cppzmq 4 cd cppzmq 5 sudo cp zmq.hpp /usr/local/include 6 cd ../..
安装pssh(运行husky命令所需)
1 wget http://parallel-ssh.googlecode.com/files/pssh-2.3.1.tar.gz 2 tar zxvf pssh-2.3.1.tar.gz 3 cd pssh-2.3.1/ 4 sudo python setup.py install
编译安装husky
1 unzip husky-0.2.zip 2 cd husky/ 3 mkdir release 4 cd release 5 cmake .. 6 make -j4 Master 7 make -j4 PageRank 8 make -j4 SVM-DC 9 make -j4 Daemon
编译安装libhdfs
1 echo "deb https://dl.bintray.com/wangzw/deb trusty contrib" | sudo tee /etc/apt/sources.list.d/bintray-wangzw-deb.list 2 sudo apt-get install -y apt-transport-https 3 sudo apt-get update 4 sudo apt-get install libhdfs3 libhdfs3-dev
参考:https://github.com/Pivotal-Data-Attic/pivotalrd-libhdfs3/releases
运行
单机版:
./Master path/to/your/conf
./PageRank path/to/your/conf
多机版
./Master path/to/your/conf
./exe.sh pageRank path/to/your/conf
conf文件自动生成:(事先建好conf文件夹)
python scripts/gen_config.py
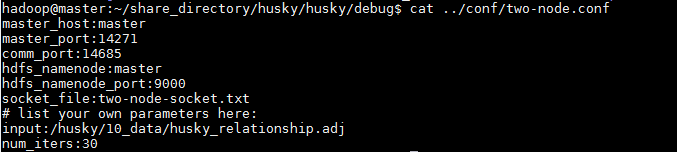
参数配置(在conf文件中)如(两台机器,最后两行为参数输入)
hadoop@master:~/share_directory/husky/husky$ cat conf/two-node.conf master_host:master master_port:14271 comm_port:14685 hdfs_namenode:master hdfs_namenode_port:9000 socket_file:two-node-socket.txt # list your own parameters here: input:/husky/1000_data/husky_relationship.adj num_iters:30
如果是要读取hdfs文件,要配置libhdfs,参见 http://www.cnblogs.com/loadofleaf/p/5694717.html(如果没有配置hdfs,默认读本地文件)
测试:
debug模式:
mkdir debug && cd debug && cmake .. -DCMAKE_BUILD_TYPE=Debug
数据文件(每一行为节点,该节点的邻居节点数,邻居点编号(多个))

conf文件
conf文件对应的socket文件(自动生成conf脚本里,会自动生成有conf文件和socket文件)

启动Master(每次启动应用,都要先启动Master)

exec.sh文件

节点列表(exec.sh文件里的变量)

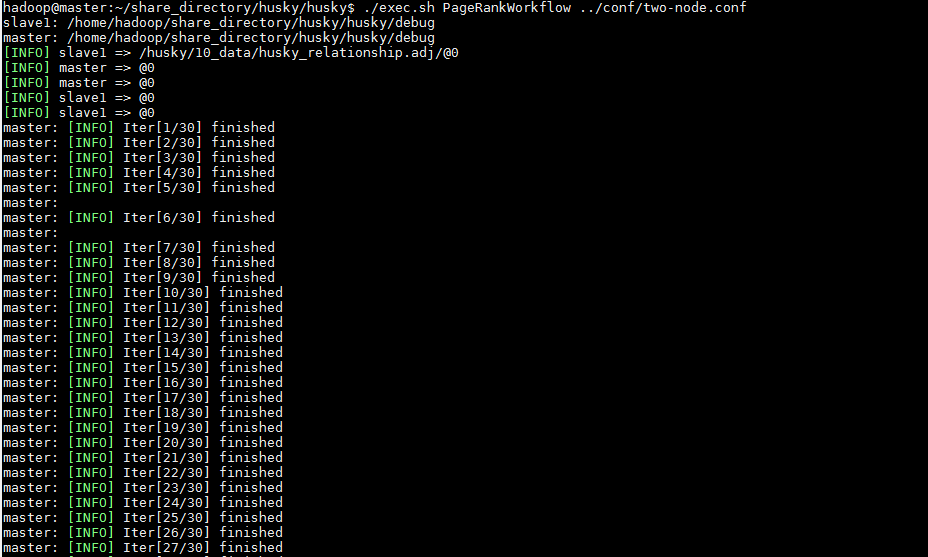
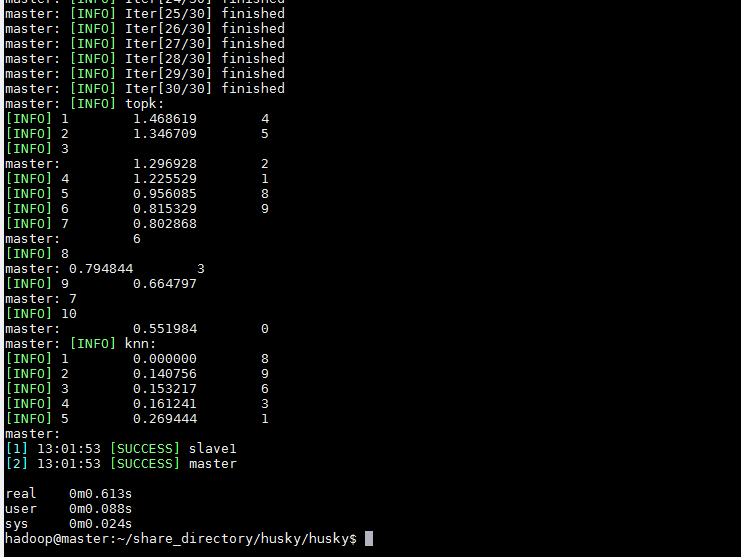
多机运行PageRankWorkflow(注:我的这个目录是NFS共享的,意思是每个slave也能直接用,相对路径也一样)