foregin的三种关系
分析步骤:
#1、先站在左表的角度去找
是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
#1、先站在左表的角度去找
是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
#2、再站在右表的角度去找
是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id)
是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id)
#3、总结:
#多对一:
如果只有步骤1成立,则是左表多对一右表
如果只有步骤2成立,则是右表多对一左表
#多对一:
如果只有步骤1成立,则是左表多对一右表
如果只有步骤2成立,则是右表多对一左表
#多对多
如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系
如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系
#一对一:
如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成uni
如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成uni
que即可
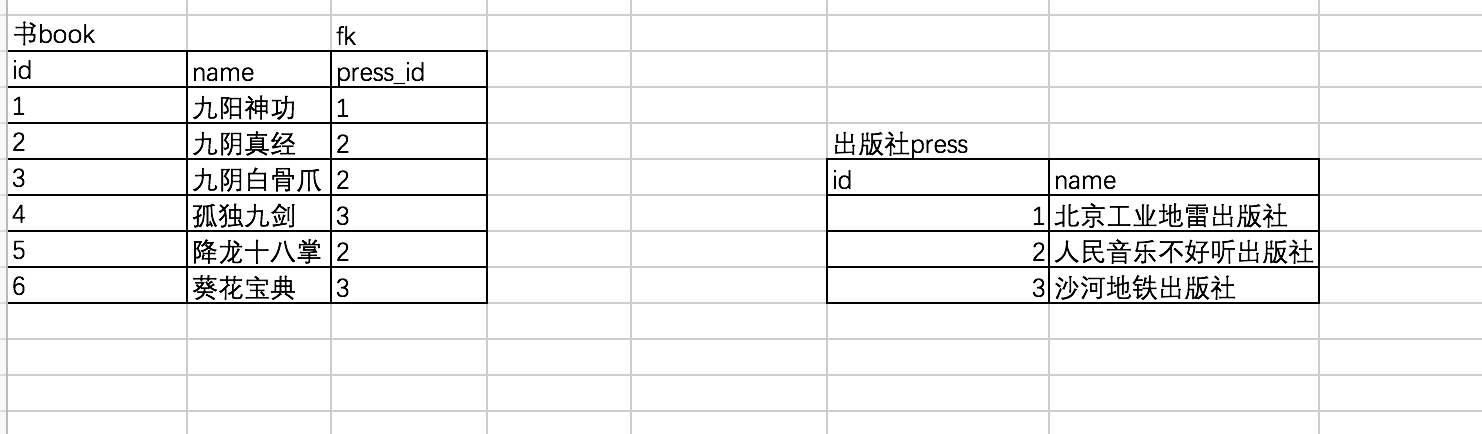
1)书和出版社
一对多(或多对一):一个出版社可以出版多本书。看图说话。
关联方式:foreign key
(2)作者和书籍的关系
多对多:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多。看图说话。
关联方式:foreign key+一张新的表

3)用户和博客
一对一:一个用户只能注册一个博客,即一对一的关系。看图说话
关联方式:foreign key+unique

简单的语法:
select 字段1,字段2 .....from 表名
where 条件
group by field 分组
having 筛选 必须加在分组后 并且使用函数
order by 排序
limit 限制条件
执行的优先级
from
where
group by
having
select
distinct
order by
limit
1,找到表:from
2,拿着where 指定的约束条件,去文件/表中取出一条条记录
3,将取出的一条条记录进行分组 group by ,如果没有group by 则视为整体
4,将分组的结果进行having过滤
5,执行select
6,去重
7将排序结果条件排序:order by
8,限制执行的显示条数
where约束:
比较运算: < > >= <= <> !=
between 80 and 100 在80到100之间 可以有not between and
in (80,90,100)值是10或20或30 not in是不在
like 'xiaomagepattern': pattern可以是%或者_。%小时任意多字符,_表示一个字符 谁要进行什么
逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
''是空字符串 不是null
分组查询:
where 之后
进行分类 小窍门:‘每’这个字后面的字段,就是我们分组的依据
可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数
聚合函数
max()最大值
min()最小值
avg()平均值
sum()求和 可以将不同的分类显示
count()总个数
group_concat() 求所有的
having过滤
HAVING与WHERE不一样的地方在于
#!!!执行优先级从高到低:where > group by > having
#1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。
#2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
#!!!执行优先级从高到低:where > group by > having
#1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。
#2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
升序降序;默认为升序asc 降序为desc order by;
limit限制查询的次数
limit 0,5 前者是从哪查询 后者是查询几条
多表的查询,终归是单表的操作
多表的连接查询
符合条件连接的查询
子查询
创建表的时候要在从表中创建dep_id,并且主表中的id 便是创建的dep_id;
多表的连接查询:
外连接语法:
select 字段列表
from 表1 inner|left|right join 表2;
on 表1.字段 = 表2.字段
1,交叉连接情况:不适合任何匹配条件(笛卡尔积)
2,内连接:只连接,匹配就行 inner 表里都有才能显示
3,4,外连接左右,优先显示左右的全部记录 如果在另一个中没有这个表的元素就会出现null
5,5) 全外连接:显示左右两个表全部记录(了解)
符合条件的查询
select employee.name,department.name from employee inner join department
on employee.dep_id = department.id
where age > 25; 和单表一样了
on employee.dep_id = department.id
where age > 25; 和单表一样了
select employee.id,employee.name,employee.age,department.name from employee,department
where employee.dep_id = department.id
and age > 25
order by age asc;
where employee.dep_id = department.id
and age > 25
order by age asc;
子查询:
:子查询是将一个查询语句嵌套在另一个查询语句中。
#2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
#3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
#4:还可以包含比较运算符:= 、 !=、> 、<等
#2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
#3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
#4:还可以包含比较运算符:= 、 !=、> 、<等
带in的关键字
#查询平均年龄在25岁以上的部门名
select id,name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25);
# 查看技术部员工姓名
select name from employee
where dep_id in
(select id from department where name='技术');
#查看不足1人的部门名
select name from department
where id not in
(select dep_id from employee group by dep_id);

带比较的运算符子查询:比较不是具体的值,而是内部的值
#比较运算符:=、!=、>、>=、<、<=、<>
#查询大于所有人平均年龄的员工名与年龄
mysql> select name,age from employee where age > (select avg(age) from employee);
+---------+------+
| name | age |
+---------+------+
| alex | 48 |
| wupeiqi | 38 |
+---------+------+
#查询大于所有人平均年龄的员工名与年龄
mysql> select name,age from employee where age > (select avg(age) from employee);
+---------+------+
| name | age |
+---------+------+
| alex | 48 |
| wupeiqi | 38 |
+---------+------+
#查询大于部门内平均年龄的员工名、年龄
思路:
(1)先对员工表(employee)中的人员分组(group by),查询出dep_id以及平均年龄。
(2)将查出的结果作为临时表,再对根据临时表的dep_id和employee的dep_id作为筛选条件将employee表和临时表进行内连接。
(3)最后再将employee员工的年龄是大于平均年龄的员工名字和年龄筛选。
思路:
(1)先对员工表(employee)中的人员分组(group by),查询出dep_id以及平均年龄。
(2)将查出的结果作为临时表,再对根据临时表的dep_id和employee的dep_id作为筛选条件将employee表和临时表进行内连接。
(3)最后再将employee员工的年龄是大于平均年龄的员工名字和年龄筛选。
mysql> select t1.name,t1.age from employee as t1
inner join
(select dep_id,avg(age) as avg_age from employee group by dep_id) as t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age;
+------+------+
| name | age |
+------+------+
| alex | 48 |
inner join
(select dep_id,avg(age) as avg_age from employee group by dep_id) as t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age;
+------+------+
| name | age |
+------+------+
| alex | 48 |