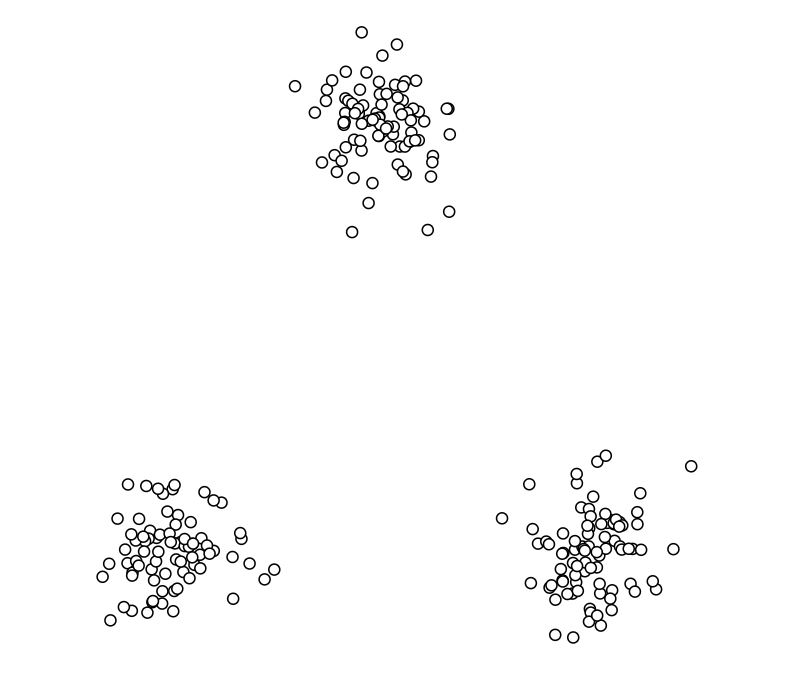
k-means是一种非监督 (从下图 0 当中我们可以看到训练数据并没有标签标注类别)的聚类算法:
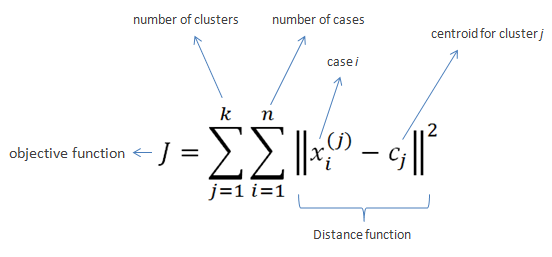
K-Means clustering intends to partition n objects into k clusters in which each object belongs to the cluster with the nearest mean. This method produces exactly k different clusters of greatest possible distinction. The best number of clusters k leading to the greatest separation (distance) is not known as a priori and must be computed from the data. The objective of K-Means clustering is to minimize total intra-cluster variance, or, the squared error function:
0.initial
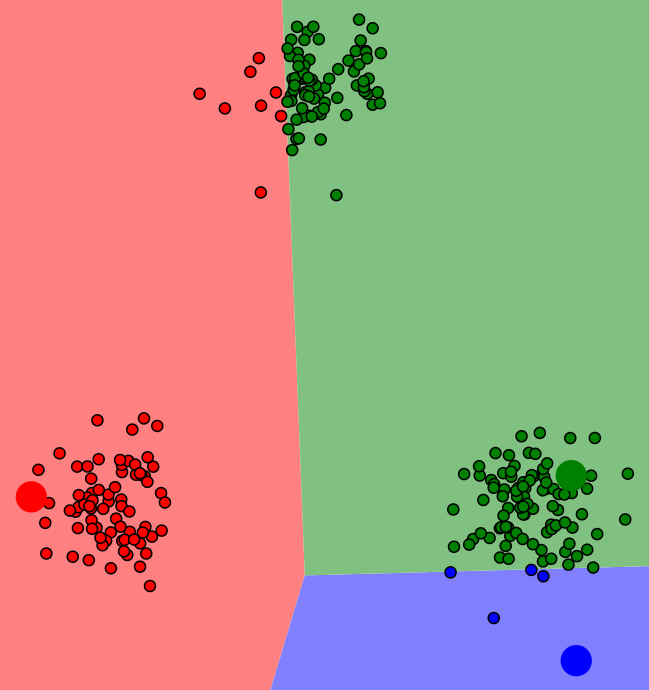
1.select centroids randomly

2.assign points
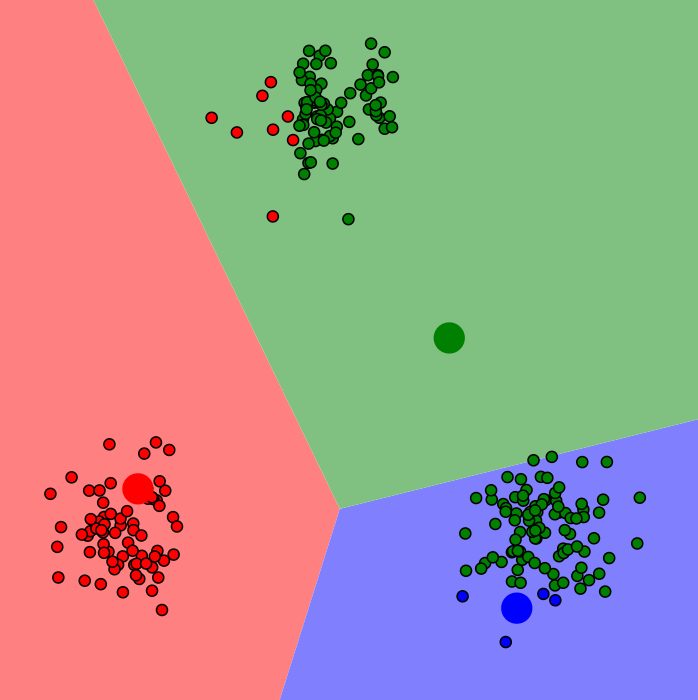
3.update centroids
4.reassign points
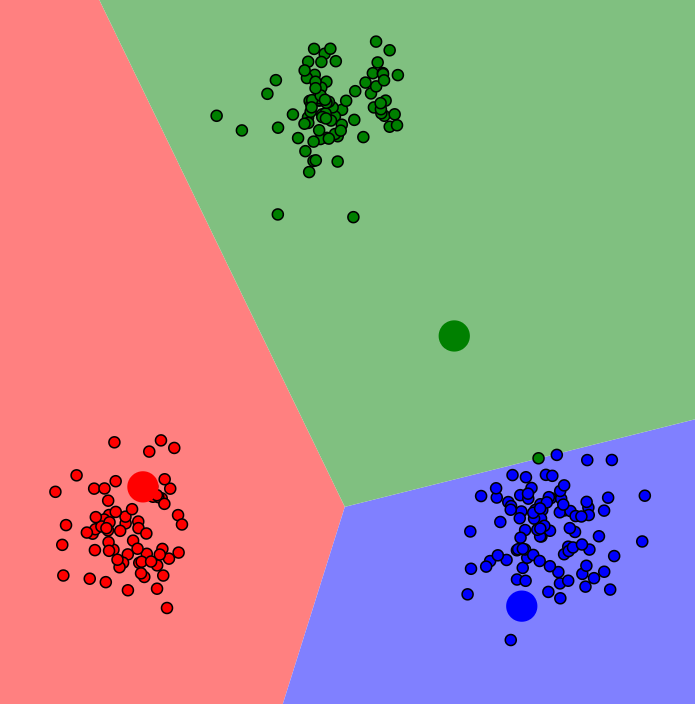
5.update centroids

6.reassign points

7.iteration
reference:
https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
https://www.saedsayad.com/clustering_kmeans.htm
转载请注明来源:https://www.cnblogs.com/lnas01/p/10347650.html