方法一:
推导式
dd="ewq4aewtaSDDSFDTFDSWQrtewtyufashas" print {i:dd.count(i) for i in dd}
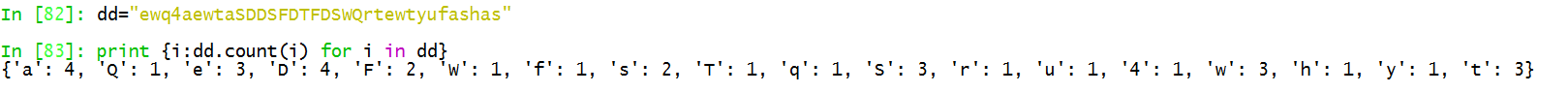
方法二:
counter
import collections dd="ewq4aewtaSDDSFDTFDSWQrtewtyufashas" obj = collections.Counter(dd) print obj

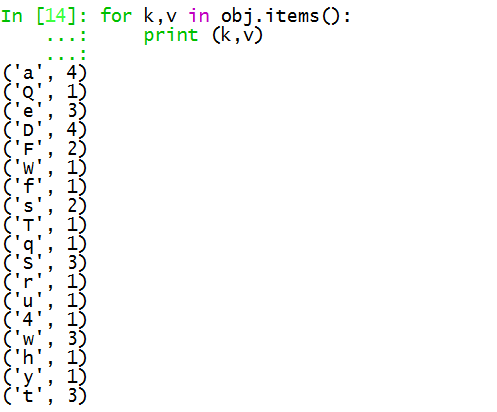
取值:
for k,v in obj.items(): print (k,v)
方法三:
和方法一类似
dd="ewq4aewtaSDDSFDTFDSWQrtewtyufashas" for i in set(dd): print(i,dd.count(i))

方法四:
dd = 'ewq4aewtaSDDSFDTFDSWQrtewtyufashas' d = {} for c in dd: d[c] = (d[c] + 1) if (c in d) else (1) print d

打印出排行前三的字符
dd="ewq4aewtaSDDSFDTFDSWQrtewtyufashas" obj = collections.Counter(dd) print obj.most_common(3)

python统计一个文档中 各个字符出现的次数
f = file("data.txt") s = f.read() # 这里的s采用文件的方式读取 global list_all global list_to_statistic def tran_s_to_list(s): list_all = [] l = len(s) # 得到长度,遍历 for x in xrange(0,l): # 当x不在list中,即第一次出现,追加到list中 if not s[x] in list_all: list_all.append(s[x]) return list_all def statistic(s, list_all, list_to_statistic): l = len(s) for x in xrange(0,l): 遍历字符串,找到每一个char在list中的index,在list_statistic相应位置加一 list_to_statistic[list_all.index(s[x])] = list_to_statistic[list_all.index(s[x])]+1 # print list_all.index(s[x]), # print list_all = tran_s_to_list(s) # 复制一个和list等长的数组list_statistic,并且全部赋值为0 list_to_statistic = list_all[ : ] for x in xrange( 0, len(list_all) ): list_to_statistic[x] = 0 statistic(s, list_all, list_to_statistic); # 打印 listlength = len(list_all) for x in xrange(0, listlength): print str(list_all[x])+"" + "---appers---"+str(list_to_statistic[x])+"---times"