作业一
(1)要求:
* 用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
* 每部电影的图片,采用多线程的方法爬取,图片名字为电影名
* 了解正则的使用方法
- 候选网站:豆瓣电影:https://movie.douban.com/top250
graph TD
A[浏览器发起请求获取当前页面源码数据] -->|获取lis| B(通过select)
B --> C{获取每一个li里面的数据}
C -->|正常获取| D[获得数据]
C -->|特殊情况判断| F[获取数据]
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/11/27
import requests
from bs4 import BeautifulSoup
import re,os
import threading
import pymysql
import urllib
class MySpider:
def startUp(self,url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
self.open = False
try:
self.con = pymysql.connect(host='localhost',port=3306,user='root',passwd='031804114.hao',database='movies',charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.open = True
try:
self.cursor.execute("drop table if exists movies")
except Exception as err:
# print(err)
pass
try:
sql = """create table movies(
rank varchar(32),
movie_name varchar(32),
direct varchar(64),
main_act varchar(128),
show_time varchar(64),
country varchar(128),
movie_type varchar(64),
score varchar(32),
count varchar(32),
quote varchar(128),
path varchar(64)
)character set =utf8;
"""
self.cursor.execute(sql)
print("表格创建成功")
except Exception as err:
print(err)
print("表格创建失败")
except Exception as err:
print(err)
self.no = 0
# self.page = 0
self.Threads = []
# page_text = requests.get(url=url,headers=headers).text
# soup = BeautifulSoup(page_text,'lxml')
# print(soup)
# li_list = soup.select("ol[class='grid_view'] li"c)
urls = []
for i in range(5):
url = 'https://movie.douban.com/top250?start=' + str(i*25) + '&filter='
req = urllib.request.Request(start_url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
# print(soup)
lis = soup.select("ol[class='grid_view'] li")
for li in lis:
# number = li.select('em')[0].text
# hd = li.select("div[class='hd'] a")[0]
# title = hd.select("span[class='title']")[0].text
# two = li.select("div[class='bd'] p")[0].text
# d= ''.join(two.split())
# director = d.split(":")[1]
# director = director[:-2]
if len(d.split(":"))==2:
# spl = d.split(":")[1]
# director_ = spl.split("...")[0]
# director = director_[:-1]
# personator = '...'
# other = spl.split("...")[1]
# time = other.split("/")[0]
# country = other.split("/")[1]
# type = other.split("/")[2]
# else:
# others = d.split(":")[2]
# pat = re.compile("d{4}")
# time = re.findall(pat,others)[0]
# country = others.split("/")[-2]
# type = others.split("/")[-1]
# personator = others.split("...")[0]
#
# print(number,title,len(d.split(":")),director,personator,time,country,type)
# i+=25
# next_page = re.sub(r'.*start=0','start=str(i)',start_url)
# start_url =next_page
rank = li.select("div[class='item'] div em")[0].text
movie_name = li.select("div[class='info'] div a span[class='title']")[0].text
print(movie_name)
dir_act = li.select("div[class='info'] div[class='bd'] p")[0].text
dir_act = ' '.join(dir_act.split())
try:
direct = re.search(':.*:',dir_act).group()[1:-3]
except:
direct = "奥利维·那卡什 Olivier Nakache / 艾力克·托兰达 Eric Toledano "
# print(direct)
# print(dir_act)
s = dir_act.split(':')
# print(s)
try:
main_act = re.search(r'(D)*',s[2]).group()
except:
main_act = "..."
# print(main_act)
pattern = re.compile('d+',re.S)
show_time = pattern.search(dir_act).group()
# print(show_time)
countryAndmovie_type = dir_act.split('/')
country = countryAndmovie_type[-2]
movie_type = countryAndmovie_type[-1]
score = li.select("div[class='info'] div[class='star'] span")[1].text
# print(score)
count = re.match(r'd+',li.select("div[class='info'] div[class='star'] span")[3].text).group()
# print(score,count,quote)
img_name = li.select("div[class='item'] div a img")[0]["alt"]
try:
quote = li.select("div[class='info'] p[class='quote'] span")[0].text
except:
quote = ""
# print(img_name)
img_src = li.select("div[class='item'] div a img[src]")[0]["src"]
path = 'movie_img\' + img_name + '.jpg'
# print(img_name,img_src,path)
print(rank,'2',movie_name,'3',direct,'4',main_act,'5',show_time,'6',country,'7',movie_type,'8',score,'9',count,'10',quote,'11',path)
try:
self.insertdb(rank,movie_name,direct,main_act,show_time,country,movie_type,score,count,quote,path)
self.no += 1
except Exception as err:
# print(err)
print("数据插入失败")
if url not in urls:
T = threading.Thread(target=self.download,args=(img_name,img_src))
T.setDaemon(False)
T.start()
self.Threads.append(T)
# print(len(li_list))
def download(self,img_name,img_src):
dir_path = 'movie_img'
if not os.path.exists(dir_path):
os.mkdir(dir_path)
# for img in os.listdir(movie_img):
# os.remove(os.path.join(movie_img,img))
file_path = dir_path + '/' + img_name + '.jpg'
with open(file_path,'wb') as fp:
data = urllib.request.urlopen(img_src)
data = data.read()
# print("正在下载:" + img_name)
fp.write(data)
# print(img_name+ "下载完成")
fp.close()
def insertdb(self,rank,movie_name,direct,main_act,show_time,country,movie_type,score,count,quote,path):
if self.open:
self.cursor.execute("insert into movies(rank,movie_name,direct,main_act,show_time,country,movie_type,score,count,quote,path)values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(rank,movie_name,direct,main_act,show_time,country,movie_type,score,count,quote,path))
else:
print("数据库未连接")
def closeUp(self):
if self.open:
self.con.commit()
self.con.close()
self.open = False
print("一共爬取了" ,self.no,"条数据")
url = 'https://movie.douban.com/top250'
myspider = MySpider()
myspider.startUp(url)
myspider.closeUp()
for t in myspider.Threads:
t.join()
print("End")

(2)心得体会
获取源码后的数据略有不全,只通过当前页面的源码获得想要的数据需要进行一些特别判断,其实可以在详情页面里面获取,当然会麻烦一些,一些判断条件比较难弄
作业二
(1)要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
graph TD
A[发起请求 ] -->|获取源码并解析 | B(获得部分数据)
B --> C(获得的每个大学的详情url)
C -->|拼接成完整的url| D[获取当前页面的源码数据并进行提取想要的数据]
C -->|等待剩余数据存到MySQL| F[和前面的数据一起存到MySQL]
spider
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/12/1
import scrapy
from bs4 import UnicodeDammit
import requests
from bs4 import BeautifulSoup
from ..items import RuankeItem
import os
class spider_r(scrapy.Spider):
name = 'spider_rk'
def start_requests(self):
url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
print(url)
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body,["utf-8",'gbk'])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
trs = selector.xpath("//div[@class='rk-table-box']/table/tbody/tr")
for tr in trs:
no= tr.xpath("./td[position()=1]/text()").extract_first().strip()
name = tr.xpath("./td[position()=2]/a/text()").extract_first()
next = tr.xpath("./td[position()=2]/a/@href").extract_first()
city = tr.xpath("./td[position()=3]/text()").extract_first().strip()
# print(no,name,city)
start_url = 'https://www.shanghairanking.cn/'+ next
# print(start_url)
html = requests.get(url=start_url)
dammit = UnicodeDammit(html.content,['utf-8','gbk'])
newdata = dammit.unicode_markup
soup = BeautifulSoup(newdata,'lxml')
try:
url = soup.select("div[class='univ-website'] a")[0].text
# print(url)
mFileq = soup.select("td[class='univ-logo'] img")[0]["src"]
File = str(no) + '.jpg'
logodata = requests.get(url=mFileq).content
path = r'D:anacondaexample
uankelogo'
if not os.path.exists(path):
os.mkdir(path)
file_path = path+'/'+ File
with open(file_path,'wb') as fp:
fp.write(logodata)
fp.close()
# print(File)
brief = soup.select("div[class='univ-introduce'] p")[0].text
# print(brief)
except Exception as err:
print(err)
item = RuankeItem()
item["sNo"] = no
item["schoolName"] = name
item["city"] = city
item["officalUrl"] = url
item["info"] = brief
item["mFile"] = File
yield item
except Exception as err:
print(err)
item
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class RuankeItem(scrapy.Item):
sNo = scrapy.Field()
schoolName = scrapy.Field()
city = scrapy.Field()
officalUrl = scrapy.Field()
info = scrapy.Field()
mFile = scrapy.Field()
pipelines
from itemadapter import ItemAdapter
import pymysql
class RuankePipeline:
def open_spider(self, spider):
print("建立连接")
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='031804114.hao', db='mydb',
charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
self.cursor.execute("drop table if exists ruanke")
sql = """create table ruanke(
sNo varchar(32) primary key,
schoolName varchar(32),
city varchar(32),
officalUrl varchar(64),
info text,
mFile varchar(32)
)character set = utf8
"""
self.cursor.execute(sql)
except Exception as err:
print(err)
print("表格创建失败")
self.open = True
self.count = 1
except Exception as err:
print(err)
self.open = False
print("数据库连接失败")
def process_item(self, item, spider):
print(item['sNo'], item['schoolName'], item['city'], item['officalUrl'], item['info'], item['mFile'])
if self.open:
try:
self.cursor.execute(
"insert into ruanke(sNo,schoolName,city,officalUrl,info,mFile) values(%s,%s,%s,%s,%s,%s)",
(item['sNo'], item['schoolName'], item['city'], item['officalUrl'], item['info'], item['mFile']))
self.count += 1
except:
print("数据插入失败")
else:
print("数据库未连接")
return item
def close_spider(self, spider):
if self.open:
self.con.commit()
self.con.close()
self.open = False
print('closed')
print("一共爬取了", self.count, "条")



(2)心得体会
获取网页源码信息后,用selector.xpath获取trs,再通过循环遍历每一个tr标签,获取部分信息后,再通过获取的
详情url,得到每个大学的url,发送get请求,通过beautifulsoup解析获取想要的数据,总的来说还可以,又熟悉了
一次scrapy框架,不过感觉还是selenium爬取网站信息好用
作业三
(1)要求:
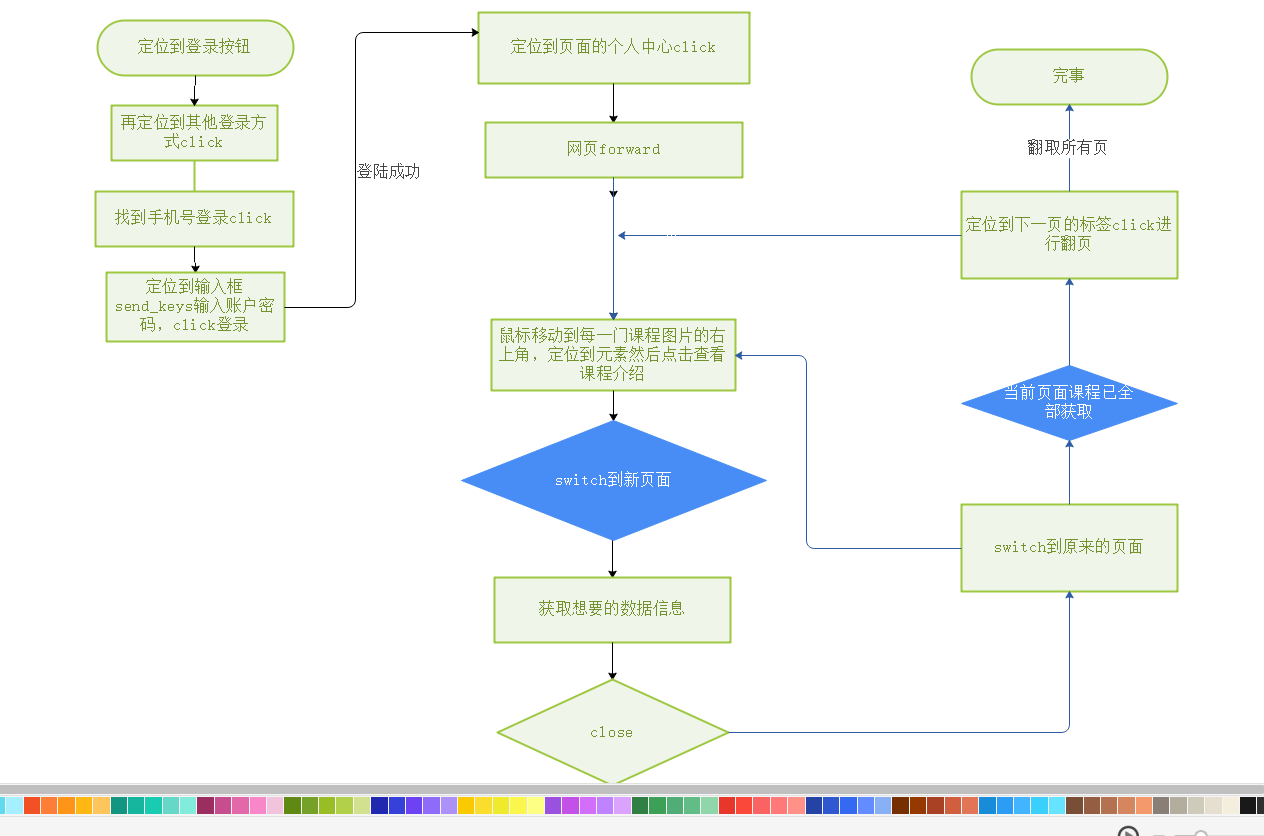
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
- 候选网站: 中国mooc网:https://www.icourse163.org
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/11/25
from selenium import webdriver
import time
import os
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.by import By
import pymysql
from selenium.webdriver.common.action_chains import ActionChains
from webdriver_manager.chrome import ChromeDriverManager
#声明并调用浏览器,实例化一个浏览器对象(传入浏览器驱动)
browser = webdriver.Chrome(ChromeDriverManager().install())
#定义存数据到MySQL
class down_mysql:
def __init__(self, i,course,college,teacher,team,count,process,brief):
self.id = i
self.course = course
self.college = college
self.teacher = teacher
self.team = team
self.count = count
self.process = process
self.brief = brief
self.connect = pymysql.connect(
host='localhost',
db = 'gupiao',
port = 3306,
user = 'root',
passwd = '031804114.hao',
charset = 'utf8',
use_unicode =False
)
self.cursor = self.connect.cursor()
# 保存数据到MySQL中
def save_mysql(self):
sql = "insert into selenium_mooc(id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) values (%s,%s,%s,%s,%s,%s,%s,%s)"
try:
self.cursor.execute(sql, (self.id, self.course, self.college,self.teacher,self.team,
self.count,self.process,self.brief))
self.connect.commit()
print('数据插入成功')
except:
print('数据插入错误')
# 新建对象,然后将数据传入类中
def mysql(i,course,college,teacher,team,count,process,brief):
down = down_mysql(i,course,college,teacher,team,count,process,brief)
down.save_mysql()
def main():
start_url = "https://www.icourse163.org/"
wait = ui.WebDriverWait(browser,10)
browser.get(start_url)
wait.until(lambda broswser:browser.find_element_by_xpath("//div[@id='g-container']/div[@id='j-indexNav-bar']/div/div/div/div/div[@class='web-nav-right-part']/div[@class='u-navLogin-loginBox']/div/div/div/a"))
print("you did it")
browser.find_element_by_xpath("//div[@id='g-container']/div[@id='j-indexNav-bar']/div/div/div/div/div[@class='web-nav-right-part']/div[@class='u-navLogin-loginBox']/div/div/div/a").click()
time.sleep(2)
browser.find_element_by_xpath("//div[@class='mooc-login-set']/div/div[@class='ux-login-set-scan-code_ft']/span").click()
time.sleep(2)
browser.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']/li[position()=2]").click()
time.sleep(2)
wait.until(lambda broswser:browser.find_element_by_xpath("//div[@class='ux-login-urs-phone-wrap f-pr']/div[@class='ux-login-set-container']/iframe"))
iframe=browser.find_element_by_xpath("//div[@class='ux-login-urs-phone-wrap f-pr']/div[@class='ux-login-set-container']/iframe")
# browser.switch_to.frame(browser.find_element_by_xpath('//iframe[contains(@src,"https://reg.icourse163.org/webzj/v1.0.1/pub/index_dl2_new.html?cd=%2F%2Fcmc.stu.126.net%2Fu%2Fcss%2Fcms%2F&cf=mooc_urs_login_css.css&MGID=1606315255717.7847&wdaId=UA1438236666413&pkid=cjJVGQM&product=imooc")]'))
print("qianhuan")
browser.switch_to.frame(iframe)
print("didi")
browser.find_element_by_id("phoneipt").clear()
browser.find_element_by_id("phoneipt").send_keys("13055720097")
time.sleep(3)
browser.find_element_by_xpath("//div[@class='u-input box']/input[@class='j-inputtext dlemail']").clear()
browser.find_element_by_xpath("//div[@class='u-input box']/input[@class='j-inputtext dlemail']").send_keys("*******")
time.sleep(3)
browser.find_element_by_xpath("//div[@class='f-cb loginbox']/a").click()
browser.switch_to.default_content()
time.sleep(6)
# browser.maximize_window()
# browser.find_element_by_xpath("//div[@class='u-navLogin-container']/div[@class='e-hover-source u-navLogin-course']/a").click()
a=wait.until(lambda broswser:browser.find_element_by_xpath("//div[@class='web-nav-right-part']/div[@class='ga-click u-navLogin-myCourse']/div[@class='u-navLogin-myCourse-t']/div[@class='ga-click u-navLogin-myCourse u-navLogin-center-container']/a"))
xiangqing = a.get_attribute("href")
print(xiangqing)
browser.find_element_by_xpath("//div[@class='web-nav-right-part']/div[@class='ga-click u-navLogin-myCourse']/div[@class='u-navLogin-myCourse-t']/div[@class='ga-click u-navLogin-myCourse u-navLogin-center-container']/a").click()
time.sleep(3)
#个人中心
browser.forward()
for a in range(3):
wait.until(lambda b2:browser.find_element_by_xpath("//div[@class='course-panel-wrapper']/div[@class='course-panel-body-wrapper']"))
one_page = browser.find_element_by_xpath("//div[@class='course-panel-wrapper']/div[@class='course-panel-body-wrapper']")
# print("找到第一页了")
i = 0
for one in one_page.find_elements_by_xpath("./div[@class='course-card-wrapper']"):
i+=1
sandian = one.find_element_by_xpath("./div[@class='menu-btn']")
action = ActionChains(browser)
action.move_to_element(sandian).perform()
time.sleep(1)
one.find_element_by_xpath("./div[@class='menu']/div[position()=1]/a").click()
time.sleep(1)
#处理点击连接出现新网页
windows = browser.window_handles
browser.switch_to.window(windows[1])#切到新页面
time.sleep(2)
wait.until(lambda browser2: browser2.find_element_by_xpath(
"//div[@class='f-fl course-title-wrapper']/span[position()=1]"))
name = browser.find_element_by_xpath("//div[@class='f-fl course-title-wrapper']/span[position()=1]")
course = name.text
Process = browser.find_element_by_xpath(
"//div[@class='course-enroll-info_course-info_term-info_term-time']/span[position()=2]")
process = Process.text
people = browser.find_element_by_xpath("//div[@class='course-enroll-info_course-enroll_price-enroll']/span")
count = people.text.split()[1]
jieshao = browser.find_element_by_xpath("//div[@class='course-heading-intro']/div[position()=1]")
brief = jieshao.text
college = browser.find_element_by_xpath("//div[@class='m-teachers']/a").get_attribute("data-label")
wait.until(lambda browser2: browser2.find_element_by_xpath(
"//div[@class='um-list-slider f-pr']/div[@class='um-list-slider_con']"))
teams = browser.find_element_by_xpath("//div[@class='um-list-slider f-pr']/div[@class='um-list-slider_con']")
T = teams.find_element_by_xpath("./div[position()=1]/div/div[@class='cnt f-fl']/h3")
teacher = T.text
team = ''
for each in teams.find_elements_by_xpath("./div"):
team_part = each.find_element_by_xpath("./div/div[@class='cnt f-fl']/h3")
part = team_part.text
team += part
print(course,team,count,process,brief)
mysql(i, course, college, teacher, team, count, process, brief)
browser.close()#关闭当前页面
time.sleep(1)
browser.switch_to.window(windows[0])#切回到原来界面
time.sleep(1)
# 点击下一页
wait.until(lambda browser:browser.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a"))
browser.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a").click()
if __name__ == '__main__':
main()
#处理点击连接出现新网页
# windows = browser.window_handles
# browser.switch_to.window(windows[1])
# time.sleep(2)

(2)心得体会
定位到登录按钮,再定位其他登录方式click,找到手机号登录click,
定位输入框send_keys输入账户密码,click登录,定位个人中心click
网页前进forward,鼠标移动到每一门课程图片的右上角,定位到元素
然后点击查看课程介绍,switch到新页面,获取想要的信息后,close
再switch到原来的界面,定位到下一页的标签click进行翻页,完事