作业一
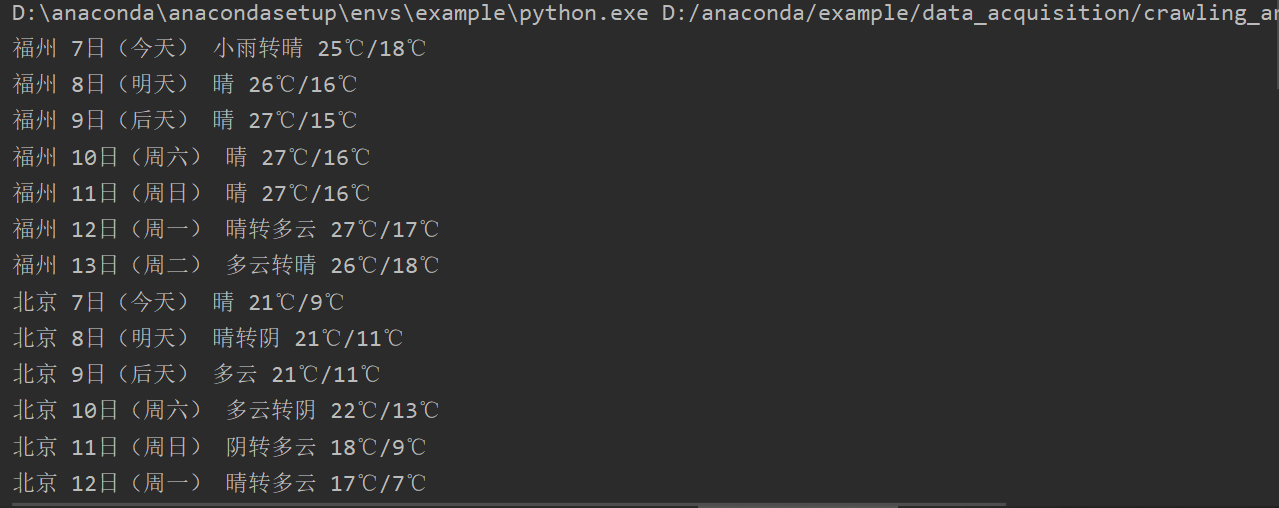
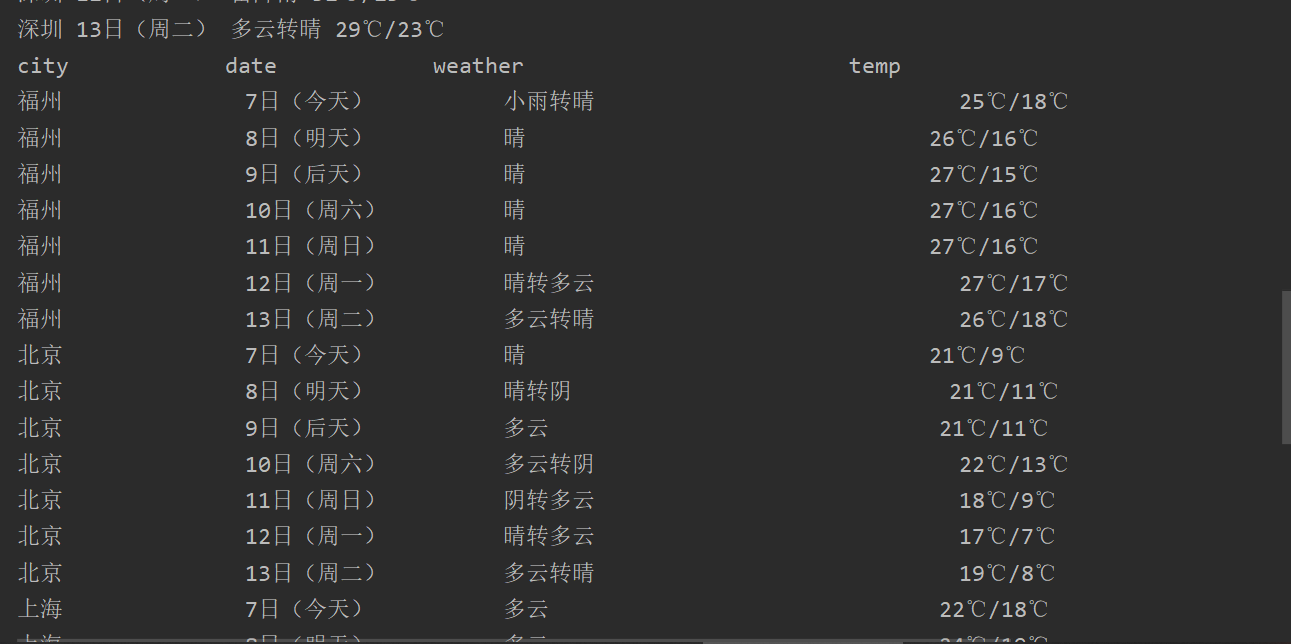
(1)、在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/9/30
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class weatherDB:
def openDB(self):
self.con = sqlite3.connect("weather.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table weathers (wcity varchar(16),wdate varchar(16),wweather varchar(64),wtemp varchar(32),constraint pk_weather primary key(wcity,wdate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wcity,wdate,wweather,wtemp) values(?,?,?,?)",
(city, date, weather, temp))
except:
print("err")
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class weatherforecast():
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
self.citycode = {"福州":"101230101","北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastcity(self, city):
if city not in self.citycode.keys():
print(city + "code not found")
return
url = "http://www.weather.com.cn/weather/" + self.citycode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, 'html.parser')
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date_ = li.select('h1')[0].text
weather_ = li.select('p[class="wea"]')[0].text
temp_ = li.select('p[class="tem"] span')[0].text + '℃/' + li.select("p[class='tem'] i")[0].text
print(city, date_, weather_, temp_)
self.db.insert(city, date_, weather_, temp_)
except:
print('err1')
except:
print('err2')
def precess(self, cities):
self.db = weatherDB()
self.db.openDB()
for city in cities:
self.forecastcity(city)
self.db.show()
self.db.closeDB()
ws = weatherforecast()
ws.precess(["福州","北京", '上海', '广州', '深圳'])
print('completed')
(2)、心得体会
对着书上的打的,新的就是存储到数据库里
作业二
(1)、用requests和BeautifulSoup库方法定向爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/9/30
import requests
from bs4 import BeautifulSoup
import re
def get_html(url):
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
# print("来了来了")
response = requests.get(url, headers=headers) # 请求访问网站
if response.status_code == 200:
html = response.text # 获取网页滴源码
return html #获取成功后返回
else:
print("获取网站信息失败!")
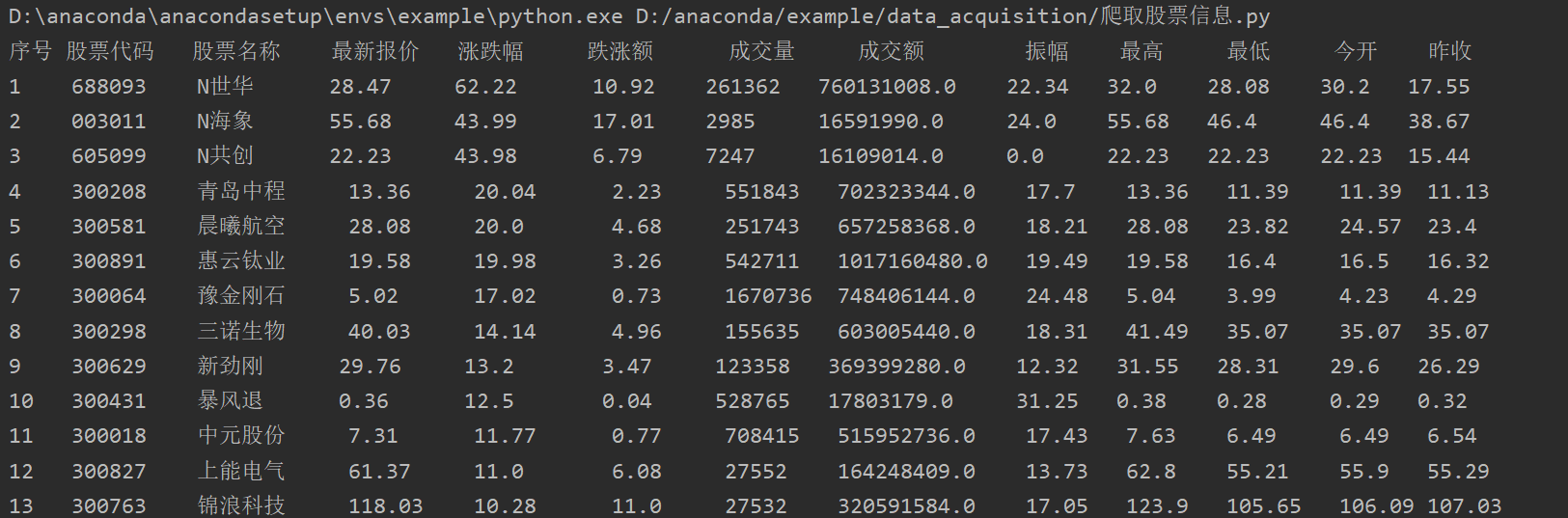
print("序号 股票代码 股票名称 最新报价 涨跌幅 跌涨额 成交量 成交额 振幅 最高 最低 今开 昨收")
for j in range(1,30):
url = 'http://64.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408828364991523157_1601811976313&pn=' + str(
j) + '&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f2,f3,f4,f5,f6,f7,f8,f9,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22&_=1601811976531'
html = get_html(url)
pat = re.compile("[{.*?}]") # 正则表达式
data2 = pat.findall(html)
datas = eval(data2[0])
i=0
for data in datas:
i+=1
print("{:<4} {:<9} {:<8} {:<9} {:<10} {:<8} {:<8} {:<14} {:<7} {:<7} {:<8} {:<6} {:<6}".format(i,data["f12"],data["f14"],data["f2"],data["f3"],data["f4"],data["f5"],data["f6"],data["f7"],data["f15"],data["f16"],data["f17"],data["f18"],chr(12288)))
(2)、心得体会
了解到了抓包,查看js,以及在分析得到的js数据格式,再利用正则进行提取所需要的,正则真的难,还有json的一些用法,还有翻页np=2
作业三
(1)、要求:根据自选3位数+学号后3位选取股票,获取印股票信息。抓包方法同作②。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/10/7
import requests
from bs4 import BeautifulSoup
import re
def get_html(url):
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
# print("来了来了")
response = requests.get(url, headers=headers) # 请求访问网站
if response.status_code == 200:
html = response.text # 获取网页滴源码
return html #获取成功后返回
else:
print("获取网站信息失败!")
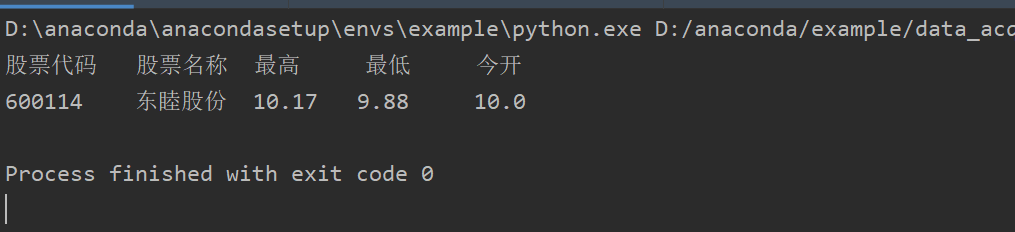
print("股票代码 股票名称 最高 最低 今开")
for j in range(1,30):
url = 'http://64.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408828364991523157_1601811976313&pn=' + str(
j) + '&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f2,f3,f4,f5,f6,f7,f8,f9,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22&_=1601811976531'
html = get_html(url)
pat = re.compile("[{.*?}]") # 正则表达式
data2 = pat.findall(html)
datas = eval(data2[0])
i=0
for data in datas:
i+=1
if str(data["f12"]).endswith("114"):
print("{:<10}{:<6}{:<8}{:<9}{:<8}".format(data["f12"],data["f14"],data["f15"],data["f16"],data["f17"]),chr(12288))
break
(2)心得体会
在作业二的基础上加一个筛选条件即可