总体来说可以分为以下几个过程:
- DNS解析
- TCP连接
- 发送http请求
- 服务器处理请求并返回HTTP报文
- 浏览器解析渲染页面
- 连接结束
一、DNS解析
1、请求一旦发起,浏览器首先要做的事情就是解析这个域名,一般来说,浏览器会首先查看本地硬盘的 hosts 文件,看看其中有没有和这个域名对应的规则,如果有的话就直接使用 hosts 文件里面的 ip 地址。
2、如果在本地的 hosts 文件没有能够找到对应的 ip 地址,浏览器会发出一个 DNS请求到本地DNS服务器 。本地DNS服务器一般都是你的网络接入服务器商提供,比如中国电信,中国移动。
3、查询你输入的网址的DNS请求到达本地DNS服务器之后,本地DNS服务器会首先查询它的缓存记录,如果缓存中有此条记录,就可以直接返回结果,此过程是递归的方式进行查询。如果没有,本地DNS服务器还要向DNS根服务器进行查询。
4、根DNS服务器没有记录具体的域名和IP地址的对应关系,而是告诉本地DNS服务器,你可以到域服务器上去继续查询,并给出域服务器的地址。这种过程是迭代的过程。
5、本地DNS服务器继续向域服务器发出请求,在这个例子中,请求的对象是.com域服务器。.com域服务器收到请求之后,也不会直接返回域名和IP地址的对应关系,而是告诉本地DNS服务器,你的域名的解析服务器的地址。
6、最后,本地DNS服务器向域名的解析服务器发出请求,这时就能收到一个域名和IP地址对应关系,本地DNS服务器不仅要把IP地址返回给用户电脑,还要把这个对应关系保存在缓存中,以备下次别的用户查询时,可以直接返回结果,加快网络访问。

上述图片是查找www.google.com的IP地址过程。首先在本地域名服务器中查询IP地址,如果没有找到的情况下,本地域名服务器会向根域名服务器发送一个请求,如果根域名服务器也不存在该域名时,本地域名会向com顶级域名服务器发送一个请求,依次类推下去。直到最后本地域名服务器得到google的IP地址并把它缓存到本地,供下次查询使用。从上述过程中,可以看出网址的解析是一个从右向左的过程: com -> google.com -> www.google.com。但是你是否发现少了点什么,根域名服务器的解析过程呢?事实上,真正的网址是www.google.com.,并不是我多打了一个.,这个.对应的就是根域名服务器,默认情况下所有的网址的最后一位都是.,既然是默认情况下,为了方便用户,通常都会省略,浏览器在请求DNS的时候会自动加上,所有网址真正的解析过程为: . -> .com -> google.com. -> www.google.com.。
二、TCP连接
拿到域名对应的IP地址之后,浏览器会以一个随机端口(1024<端口<65535)向服务器的WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。这个连接请求到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序,最终建立了TCP/IP的连接。

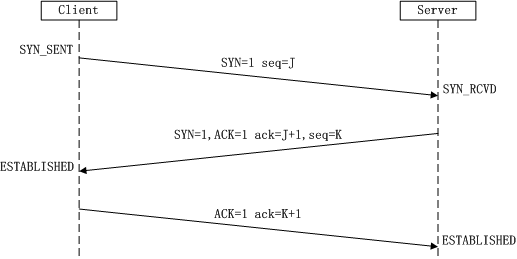
TCP的三次握手,发生在传输层,具体步骤如下:
第一次握手:客户端A将标志位SYN置为1,随机产生一个值为seq=J(J的取值范围为=1234567)的数据包到服务器,客户端A进入SYN_SENT状态,等待服务端B确认;
第二次握手:服务端B收到数据包后由标志位SYN=1知道客户端A请求建立连接,服务端B将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给客户端A以确认连接请求,服务端B进入SYN_RCVD状态。
第三次握手:客户端A收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给服务端B,服务端B检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,客户端A和服务端B进入ESTABLISHED状态,完成三次握手,随后客户端A与服务端B之间可以开始传输数据了。
为什么需要三次握手?
《计算机网络》第四版中讲“三次握手”的目的是“为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误”
书中的例子是这样的,“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。
假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”。主要目的防止server端一直等待,浪费资源。
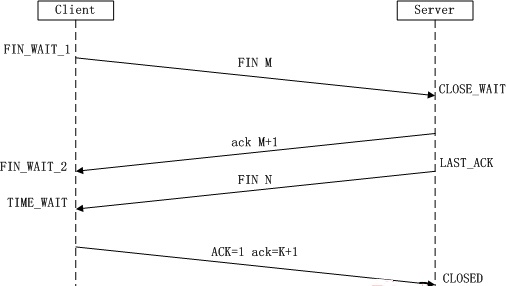
TCP的四次挥手:
第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
这是因为服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而关闭连接时,当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即close,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送。
三、发送http请求
建立了TCP连接之后,发起一个http请求。一个典型的 http request header 一般需要包括请求的方法,例如 GET 或者 POST 等,不常用的还有 PUT 和 DELETE 、HEAD、OPTION以及 TRACE 方法,一般的浏览器只能发起 GET 或者 POST 请求。
客户端向服务器发起http请求的时候,会有一些请求信息,请求信息包含三个部分:请求方法URI协议/版本、请求头(Request Header)、请求正文。
完整的HTTP请求例子:
GET/sample.jspHTTP/1.1 Accept:image/gif.image/jpeg,*/* Accept-Language:zh-cn Connection:Keep-Alive Host:localhost User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0) Accept-Encoding:gzip,deflate username=jinqiao&password=1234
四、服务器处理请求并返回HTTP报文
经过前面的重重步骤,我们终于将我们的http请求发送到了服务器这里,其实前面的重定向已经是到达服务器了,那么,服务器是如何处理我们的请求的呢?
后端从在固定的端口接收到TCP报文开始,它会对TCP连接进行处理,对HTTP协议进行解析,并按照报文格式进一步封装成HTTP Request对象,供上层使用。一些大一点的网站会将你的请求到反向代理服务器中,因为当网站访问量非常大,网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。此时,客户端不是直接通过HTTP协议访问某网站应用服务器,而是先请求到Nginx,Nginx再请求应用服务器,然后将结果返回给客户端,这里Nginx的作用是反向代理服务器。同时也带来了一个好处,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。通过Nginx的反向代理,我们到达了web服务器,服务端脚本处理我们的请求,访问我们的数据库,获取需要获取的内容等等。
服务器收到请求做了处理之后会把它的处理结果返回,也就是返回一个HTTP响应,HTTP响应与HTTP请求相似,HTTP响应也由3个部分构成,分别是:状态行、响应头(Response Header)、响应正文
一个完整的响应报文:
HTTP/1.1 200 OK Date: Sat, 31 Dec 2005 23:59:59 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 122 <html> <head> <title>http</title> </head> <body> <!-- body goes here --> </body> </html>
五、浏览器解析渲染页面
在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了,浏览器是如何把页面呈现在屏幕上的呢?不同浏览器可能解析的过程不太一样,这里我们只介绍webkit的渲染过程,下图对应的就是WebKit渲染的过程,这个过程包括:
解析html以构建dom树 -> 构建render树(渲染树) -> 布局render树 -> 绘制render树
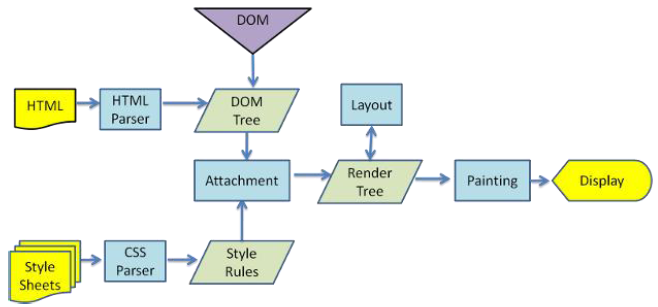
浏览器在解析html文件时,会”自上而下“加载,并在加载过程中进行解析渲染。在解析过程中,如果遇到请求外部资源时,如图片、外链的CSS、iconfont等,请求过程是异步的,并不会影响html文档进行加载。
解析过程中,浏览器首先会解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。
DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。
页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
当文档加载过程中遇到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程。因为JS有可能会修改DOM,最为经典的document.write,这意味着,在JS执行完成前,后续所有资源的下载可能是没有必要的,这是js阻塞后续资源下载的根本原因。所以我明平时的代码中,js是放在html文档末尾的。
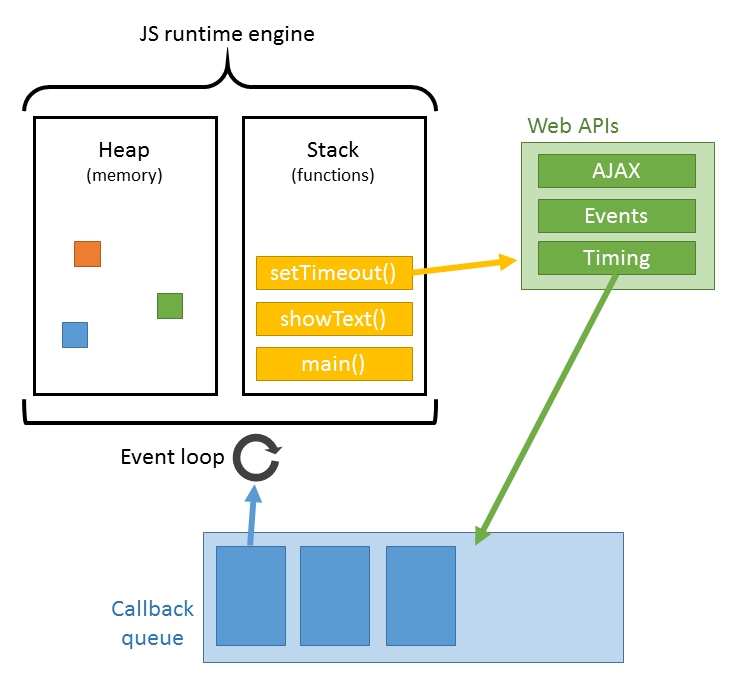
JS的解析是由浏览器中的JS解析引擎完成的,比如谷歌的是V8。JS是单线程运行,也就是说,在同一个时间内只能做一件事,所有的任务都需要排队,前一个任务结束,后一个任务才能开始。但是又存在某些任务比较耗时,如IO读写等,所以需要一种机制可以先执行排在后面的任务,这就是:同步任务(synchronous)和异步任务(asynchronous)。JS的执行机制就可以看做是一个主线程加上一个任务队列(task queue)。同步任务就是放在主线程上执行的任务,异步任务是放在任务队列中的任务。所有的同步任务在主线程上执行,形成一个执行栈;异步任务有了运行结果就会在任务队列中放置一个事件;脚本运行时先依次运行执行栈,然后会从任务队列里提取事件,运行任务队列中的任务,这个过程是不断重复的,所以又叫做事件循环(Event loop)。