特征选择是特征工程中的重要问题(另一个重要的问题是特征提取),坊间常说:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程尤其是特征选择在机器学习中占有相当重要的地位。
通常而言,特征选择是指选择获得相应模型和算法最好性能的特征集,工程上常用的方法有以下:
1. 计算每一个特征与响应变量的相关性:工程上常用的手段有计算皮尔逊系数和互信息系数,皮尔逊系数只能衡量线性相关性而互信息系数能够很好地度量各种相关性,但是计算相对复杂一些,好在很多toolkit里边都包含了这个工具(如sklearn的MINE),得到相关性之后就可以排序选择特征了;
2. 构建单个特征的模型,通过模型的准确性为特征排序,借此来选择特征,另外,记得JMLR'03上有一篇论文介绍了一种基于决策树的特征选择方法,本质上是等价的。当选择到了目标特征之后,再用来训练最终的模型;
3. 通过L1正则项来选择特征:L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性,但是要注意,L1没有选到的特征不代表不重要,原因是两个具有高相关性的特征可能只保留了一个,如果要确定哪个特征重要应再通过L2正则方法交叉检验。即:分别使用L1和L2拟合,如果两个特征在L2中系数相接近,在L1中一个系数为0一个不为0,那么其实这两个特征都应该保留,原因是L1对于强相关特征只会保留一个。
4. 训练能够对特征打分的预选模型:RandomForest和Logistic Regression等都能对模型的特征打分,通过打分获得相关性后再训练最终模型;
5. 通过特征组合后再来选择特征:如对用户id和用户特征最组合来获得较大的特征集再来选择特征,这种做法在推荐系统和广告系统中比较常见,这也是所谓亿级甚至十亿级特征的主要来源,原因是用户数据比较稀疏,组合特征能够同时兼顾全局模型和个性化模型,这个问题有机会可以展开讲。
6. 通过深度学习来进行特征选择:目前这种手段正在随着深度学习的流行而成为一种手段,尤其是在计算机视觉领域,原因是深度学习具有自动学习特征的能力,这也是深度学习又叫unsupervised feature learning的原因。从深度学习模型中选择某一神经层的特征后就可以用来进行最终目标模型的训练了。
整体上来说,特征选择是一个既有学术价值又有工程价值的问题,目前在研究领域也比较热,值得所有做机器学习的朋友重视。
通常而言,特征选择是指选择获得相应模型和算法最好性能的特征集,工程上常用的方法有以下:
1. 计算每一个特征与响应变量的相关性:工程上常用的手段有计算皮尔逊系数和互信息系数,皮尔逊系数只能衡量线性相关性而互信息系数能够很好地度量各种相关性,但是计算相对复杂一些,好在很多toolkit里边都包含了这个工具(如sklearn的MINE),得到相关性之后就可以排序选择特征了;
2. 构建单个特征的模型,通过模型的准确性为特征排序,借此来选择特征,另外,记得JMLR'03上有一篇论文介绍了一种基于决策树的特征选择方法,本质上是等价的。当选择到了目标特征之后,再用来训练最终的模型;
3. 通过L1正则项来选择特征:L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性,但是要注意,L1没有选到的特征不代表不重要,原因是两个具有高相关性的特征可能只保留了一个,如果要确定哪个特征重要应再通过L2正则方法交叉检验。即:分别使用L1和L2拟合,如果两个特征在L2中系数相接近,在L1中一个系数为0一个不为0,那么其实这两个特征都应该保留,原因是L1对于强相关特征只会保留一个。
4. 训练能够对特征打分的预选模型:RandomForest和Logistic Regression等都能对模型的特征打分,通过打分获得相关性后再训练最终模型;
5. 通过特征组合后再来选择特征:如对用户id和用户特征最组合来获得较大的特征集再来选择特征,这种做法在推荐系统和广告系统中比较常见,这也是所谓亿级甚至十亿级特征的主要来源,原因是用户数据比较稀疏,组合特征能够同时兼顾全局模型和个性化模型,这个问题有机会可以展开讲。
6. 通过深度学习来进行特征选择:目前这种手段正在随着深度学习的流行而成为一种手段,尤其是在计算机视觉领域,原因是深度学习具有自动学习特征的能力,这也是深度学习又叫unsupervised feature learning的原因。从深度学习模型中选择某一神经层的特征后就可以用来进行最终目标模型的训练了。
整体上来说,特征选择是一个既有学术价值又有工程价值的问题,目前在研究领域也比较热,值得所有做机器学习的朋友重视。
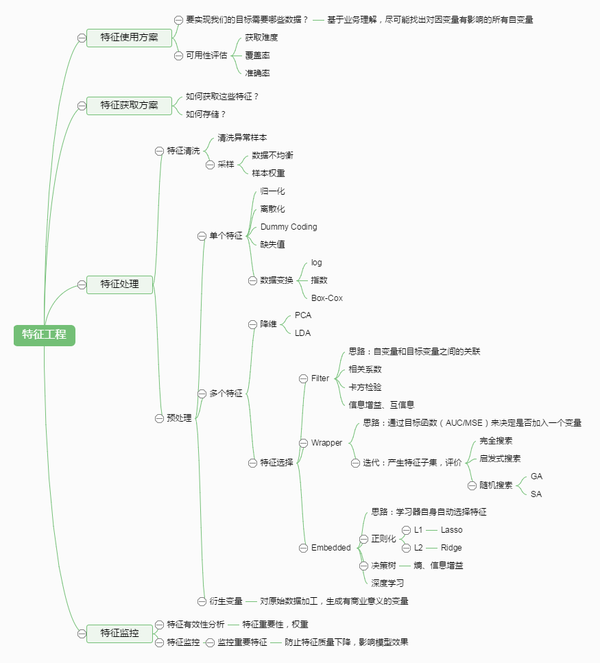
首先,追本溯源,为什么特征工程和特征选择值得讨论?在实际的数据分析和建模中,我们通常要面对两种情况:1 数据集中已有的特征变量不够多,或者已有的特征变量不足以充分表征数据的特点;2 我们拥有大量的特征,需要判断出哪些是相关特征,哪些是不相关特征。特征工程解决的是第一个问题,而特征选择解决的是第二个问题。
作者:城东
链接:特征工程到底是什么? - 城东的回答
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
目录
链接:特征工程到底是什么? - 城东的回答
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
目录
1 特征工程是什么?
2 数据预处理
2.1 无量纲化
2.1.1 标准化
2.1.2 区间缩放法
2.1.3 标准化与归一化的区别
2.2 对定量特征二值化
2.3 对定性特征哑编码
2.4 缺失值计算
2.5 数据变换
3 特征选择
3.1 Filter
3.1.1 方差选择法
3.1.2 相关系数法
3.1.3 卡方检验
3.1.4 互信息法
3.2 Wrapper
3.2.1 递归特征消除法
3.3 Embedded
3.3.1 基于惩罚项的特征选择法
3.3.2 基于树模型的特征选择法
4 降维
4.1 主成分分析法(PCA)
4.2 线性判别分析法(LDA)
5 总结
6 参考资料
作者:严林
链接:https://www.zhihu.com/question/28641663/answer/41653367
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/28641663/answer/41653367
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
https://www.zhihu.com/question/28641663 (转)