1.mrjob介绍
一个通过mapreduce编程接口(streamming)扩展出来的Python编程框架。
2.安装方法
pip install mrjob,略。初学,叙述的可能不是很细致,可以加我扣扣:2690382987,一起学习和交流~
3.代码运行方式
下面简介mrjob提供的3种代码运行方式:
1)本地测试,就是直接在本地运行代码;
2)在本地模拟hadoop运行;
3)在hadoop集群上运行。
本地测试:
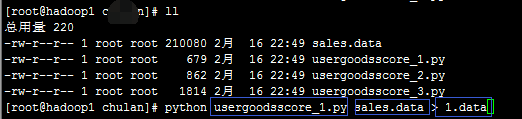
在脚本、数据所在的路径下(如果不在此路径下,就要把路径写完整):
python usergoodsscore_1.py sales.data > 1.data
第一个蓝框:mr的python脚本所在位置
第二个蓝框:数据所在的位置
第三个蓝框:输出结果存放的位置
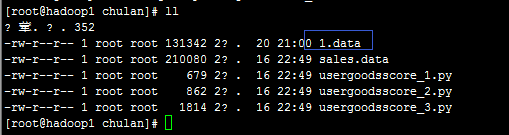
命令执行后在相应的路径下就多了1.data的文件:
在本地模拟hadoop运行:
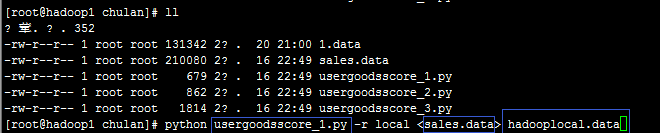
在脚本、数据所在的路径下(如果不在此路径下,就要把路径写完整):
python usergoodsscore_1.py -r local <sales.data> hadooplocal.data
第一个蓝框:mr的python脚本所在位置
第二个蓝框:数据所在的位置
第三个蓝框:输出结果存放的位置
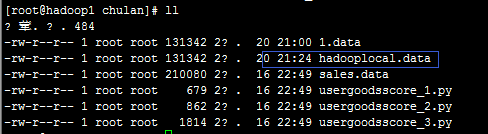
命令执行后在相应的路径下就多了hadooplocal.data的文件:
在hadoop集群上运行:
python usergoodsscore_1.py sales.data -r hadoop > hadoop1.data

参考资料:
http://www.cnblogs.com/orchid/archive/2013/04/14/3021211.html
http://www.cnblogs.com/joyeecheung/p/3760386.html
http://blog.rainy.im/2016/03/13/python-on-hadoop-mapreduce/