数据:本文采用的数据为搜狗新闻语料文本http://www.sogou.com/labs/resource/cs.php

首先逐个读入已下载的txt文件内容,正则表达出URL(新闻类别)和content(新闻内容)

具体代码如下:
SamplesGen.py
# -*- coding: utf-8 -*-
'''
该脚本用于将搜狗语料库新闻语料
转化为按照URL作为类别名、
content作为内容的txt文件存储
'''
import re
from common import listdir
'''字符数小于这个数目的content将不被保存'''
threh = 30
'''获取所有语料'''
list_name = []
listdir('SogouCS.reduced/',list_name)
'''对每个语料'''
for path in list_name:
print(path)
file = open(path, 'rb').read().decode("utf8")
'''
正则匹配出url和content
'''
patternURL = re.compile(r'<url>(.*?)</url>', re.S)
patternCtt = re.compile(r'<content>(.*?)</content>', re.S)
classes = patternURL.findall(file)
contents = patternCtt.findall(file)
'''
# 把所有内容小于30字符的文本全部过滤掉
'''
for i in range(contents.__len__())[::-1]:
if len(contents[i]) < threh:
contents.pop(i)
classes.pop(i)
'''
把URL进一步提取出来,只提取出一级url作为类别
'''
for i in range(classes.__len__()):
patternClass = re.compile(r'http://(.*?)/',re.S)
classi = patternClass.findall(classes[i])
classes[i] = classi[0]
'''
按照RUL作为类别保存到samples文件夹中
'''
for i in range(classes.__len__()):
file = 'samples/' + classes[i] + '.txt'
f = open(file,'a+',encoding='utf-8')
f.write(contents[i]+' ') #加 换行显示
1.字符数小于30的将不被content保存,在for循环中使用pop()方法删除。
2.将URL类别保存在samples文件夹中

1.将samples文件夹中分类好的数据读取
2.分词。处理此中文分词时使用结巴分词。先使用正则表达式粗略划分,然后基于trie树高速扫描,将每个句子构造有向无环图,使用动态规划查找最大概率路径,基于词频寻找最佳切分方案,最后对于未登录的单词(词表里没有的词语),采用HMM模型,维特比算法划分
3.去停用词。手动建立一个词表,将没有意义的词语去掉。
4.统计词频,生成词袋。用1.2.3处理完后,转化成词袋,生成词向量仅需要调用gensim提供的dictionary.doc2bow()方法即可生成。注意这里保存的是稀疏矩阵。具体格式为:
单个词向量:( 5 , 2 )
5是该单词在dictionary中的序号为5,2是在这篇文章中出现了两次。
一篇文章矩阵: [ (5 ,2) , (3 , 1) ]
在该文章中出现了5号单词两次,3号单词1次。
5.生成TF-IDF矩阵。根据该单词在当前文章中出现的频率和该单词在所有语料中出现的频率评估一个单词的重要性,当一个单词在这篇文章中出现的次数很多的时候,这个词语更加重要;但如果它在所有文章中出现的次数都很多,那么它就显得不那么重要。
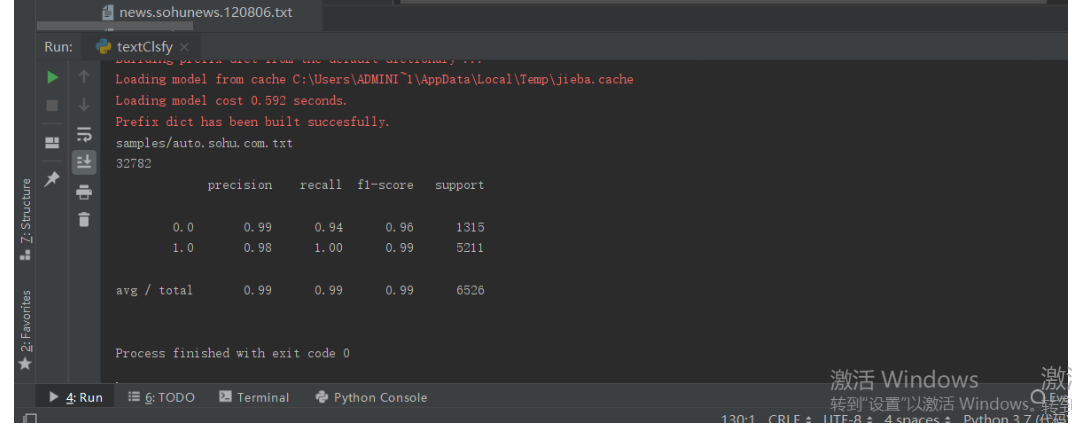
6.输入模型训练。统计各个类别的样本数目,将样本划分为训练集和测试集,采用梯度下降算法进行模型训练。 结果为:
代码为:
common.py(辅助函数脚本)
import os
'''生成原始语料文件夹下文件列表'''
def listdir(path, list_name):
for file in os.listdir(path):
file_path = os.path.join(path, file) #连接目录与文件名或目录
if os.path.isdir(file_path): #检验给出的路径是一个文件还是目录
listdir(file_path, list_name)
else:
list_name.append(file_path)
def get_stop_words():
path = "stop_words"
file = open(path, 'rb').read().decode('utf-8').split(' ')
return set(file)
def rm_stop_words(word_list):
word_list = list(word_list)
stop_words = get_stop_words()
# 这个很重要,注意每次pop之后总长度是变化的
for i in range(word_list.__len__())[::-1]:
# 去停用词
if word_list[i] in stop_words:
word_list.pop(i)
# 去数字
elif word_list[i].isdigit():
word_list.pop(i)
return word_list
def rm_word_freq_so_little(dictionary, freq_thred):
small_freq_ids = [tokenid for tokenid, docfreq in dictionary.dfs.items() if docfreq < freq_thred ]
dictionary.filter_tokens(small_freq_ids)
dictionary.compactify()
textClsfy.py
'''
本文档负责实际读取语料库文件
训练LR模型
过程中保存词典、语料和训练后的模型
'''
import numpy as np
from sklearn.linear_model.logistic import *
from gensim import corpora, models, similarities
import jieba
from sklearn.model_selection import train_test_split
import pickle
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from scipy.sparse import csr_matrix
from sklearn.metrics import classification_report
from common import listdir, rm_stop_words, rm_word_freq_so_little
if __name__ == '__main__':
freq_thred = 10 # 当一个单词在所有语料中出现次数小于这个阈值,那么该词语不应被计入词典中
# 字典
dictionary = corpora.Dictionary()
# 词袋
bow = []
labels_count = []
list_name = []
listdir('samples/', list_name)
count = 0
for path in list_name[0:2]:
print(path)
file = open(path, 'rb').read().decode('utf-8').split(' ')
class_count = 0
for text in file:
# 打标签
class_count = class_count + 1
content = text
# 分词
word_list = list(jieba.cut(content, cut_all=False))
# 去停用词
word_list = rm_stop_words(word_list)
dictionary.add_documents([word_list])
'''
转化成词袋
gensim包中的dic实际相当于一个map
doc2bow方法,对没有出现过的词语,在dic中增加该词语
如果dic中有该词语,则将该词语序号放到当前word_bow中并且统计该序号单词在该文本中出现了几次
'''
word_bow = dictionary.doc2bow(word_list)
bow.append(word_bow)
labels_count.append(class_count-1)
# with open('dictionary.pkl', 'wb') as f1:
# pickle.dump(dictionary, f1)
# 去除过少单词 ps:可能导致维数不同
rm_word_freq_so_little(dictionary,freq_thred)
# dictionary.save('dicsave.dict')
# corpora.MmCorpus.serialize('bowsave.mm', bow)
tfidf_model = models.TfidfModel(corpus=bow,dictionary=dictionary)
# with open('tfidf_model.pkl', 'wb') as f2:
# pickle.dump(tfidf_model, f2)
'''训练tf-idf模型'''
corpus_tfidf = [tfidf_model[doc] for doc in bow]
'''将gensim格式稀疏矩阵转换成可以输入scikit-learn模型格式矩阵'''
data = []
rows = []
cols = []
line_count = 0
for line in corpus_tfidf:
for elem in line:
rows.append(line_count)
cols.append(elem[0])
data.append(elem[1])
line_count += 1
print(line_count)
tfidf_matrix = csr_matrix((data,(rows,cols))).toarray()
count = 0
for ele in tfidf_matrix:
# print(ele)
# print(count)
count = count + 1
# cut label 1 mil label 0
'''生成labels'''
labels = np.zeros(sum(labels_count) + 1)
for i in range(labels_count[0]):
labels[i] = 1
'''分割训练集和测试集'''
rarray=np.random.random(size=line_count)
x_train = []
y_train = []
x_test = []
y_test = []
for i in range(line_count-1):
if rarray[i]<0.8:
x_train.append(tfidf_matrix[i,:])
y_train.append(labels[i])
else:
x_test.append(tfidf_matrix[i,:])
y_test.append(labels[i])
# x_train,x_test,y_train,y_test = train_test_split(tfidf_matrix,labels,test_size=0.3,random_state=0)
'''LR模型分类训练'''
classifier=LogisticRegression()
classifier.fit(x_train, y_train)
#
# with open('LR_model.pkl', 'wb') as f:
# pickle.dump(classifier, f)
print(classification_report(y_test,classifier.predict(x_test)))