DQL 查询表中的记录 select .... from .....
select 需要查询的信息(列名1,列名2,.......列名n) / * from 表名 [where 条件];
完善下:
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
limit
分页限定
-
-
ifnull表达式 ifnull(表达式1,表达式2)
表达式1: 代表那个字段需要判断是否为null
表达式2:如果该字段值为null 后面的进行替换
-
起别名操作
语法 as 也可以省略不写 表名 as 新的名字
查询出来的字段信息 as 新名字
当你查询同一张表,并且进行多次查询的时候可以使用起别名来实现
注意:
查询
-
select * from 表名;
select * from student;
-
查询指定列的数据:如果有多个列,中间用逗号隔开。
select 列名1,列名2,列名3,...... from 表名
select age,name from student;
-
查询时指定列的别名
-
使用关键字 as
-
使用别名的好处:显示的时候指定新的名字,并不修改表的原有结构。
-
对指定列进行别名操作: select 列名1 as 新名字,列名2 as 新名字,..... from 表名;
-
对表和列同时进行别名操作: select 列名1 as 新名字,列名2 as 新名字,..... from 表名 as 新表名;
如:对学生表进行操作:查询学生表的姓名和年龄;
select
s.age as 年龄,
s.name as 姓名
from
student as s;
-- as关键字可以省略不写。
-
使用关键字 distinct 去掉重复的记录
-
语法格式: select distinct 字段名 from 表名;
-- 查询学生表中的学生都来自于哪些地方法?
select distinct address from student;
查询的结果值可以参与数学运算
-
查询出来的列和其他列可以进行数学运算
-
语法: select 列名1+、-、/、* 列名2,..... from 表名;
-
注意: 能够参与数学运算的是前提是列的数据类型是数值型. 整数和小数
-- 查询学生表学生的数学成绩和历史成绩的和
select s.math+s.history as 综合 from student as s;
-- as 可以省略
-
查询的时候,有时候只想获取符合条件的结果值,并不是获取表中的所有记录
-
语法: select 字段列表 from 表名 where 条件表达式;
-
结果值:符合条件的记录就会被返回,如果条件不符合就不返回(过滤掉)
-
| 在SQL中,不等于有两种表示方式,!= 、<> | |
|---|---|
| between..... and | 表示的是一个区间范围 如 between A and B [A,B] |
| in(具体的取值) | 里面放的是一个个数值,如果有多个,中间用逗号隔开 |
| like | 模糊查询,根据关键字查询,一般搭配"%" |
| is null | 查询某一列为null的值,注意在sql 不能这样表达“字段名= null” |
| is not null |
操作:
-- 比较运算符的操作
-- 查询数学成绩50分以上的学生
select * from student as s where s.math <> 100;
-- BETWEEN AND
-- 查询数学成绩在70-100分之间的
select * from student as s where s.math BETWEEN 70 and 100;
-- in(某几个散列值)
-- 查询历史成绩为80分和100分的学生
select * from student as s where s.history in(80,100);
-- 模糊查询 like 搭配使用 %
-- 查询学生地址中含有"阳"的学生
select * from student as s where s.address like '%阳%';
-- 查询本班同学中含有小的学生信息
SELECT * from student as s where s.username like '%刘%';
-- 查询生日为空的学生有哪些
select * from student as s where s.birthday is not null;
备注:在模糊查询时,通配符 有两种表示方式:% _
% 匹配任意多个字符
两者都需要注意书写的位置:
一般我们使用【%】作为模糊查询的通配符
与:&& ---> and
或: || ---> or
非: !
在sql建议使用单词来表示逻辑运算 and or
-- 逻辑运算符 与或非
-- 查询历史成绩为80分和100分的同学 or
select * from student as s where s.history = 80 or s.history = 100;
-- 查询本班同学成绩在70分以上的 and
SELECT * from student as s where s.math > 70 and s.history > 70;
-- 取非 !
SELECT * from student as s where ! (s.math > 70 and s.history > 70);
-
单列排序
通过 order by语句来实现排序,只是将查询出来的结果值进行排序,并不影响查询的结果,不进行条件过滤,影响的是显示的方式(从大到小还是从小到大)
升序:asc 默认就是升序
降序:desc
单列排序:根据表中的某个字段、某列进行排序
语法: select 字段列表 from 表名 where 条件 order by 字段名 asc、desc;
--对查询出来的同学信息根据历史成绩降序排序
select * from student as s order by s.history desc;
-
-
同时对表中的多个字段进行排序,如果前面的字段值相同,再根据后面的字段再次排序
-
语法: select 字段列表 from 表名 where 条件 order by 字段1 desc|asc,字段名2 desc|asc;
-
-
-- 根据数学成绩进行升序排序,当数学成绩相同再根据历史成绩降序排序
select * from student as s order by s.math asc,s.history desc;
-
-
常用的聚合函数
-
求一个最大值 max
-
求一个最小值 min
-
求一下平均数 avg
-
求一下总和 sum
-
-
- 分组查询 group by
select
字段列表
from
表名列表
where
分组之前的条件
group by
分组字段
having
分组之后的条件
limit
分页限定条件
语法: select 字段列表 from 表名 group by 分组字段 having 分组之后的条件
例如:
-- 将查询出来的结果值内容,再按照性别进行分组,分组2组。文综和是多少
-- 年龄大于18岁的
/*
1.我想要什么样的结果值
2. sql中需要有哪些条件
3. 在sql都需要涉及到几张表
*/
SELECT
s.gender,sum(s.history+s.geo+s.political) as 文综和 -- 查询出来需要展示的结果值
from
student as s
WHERE
s.age > 18
GROUP BY
s.gender
-- 统计成年人男女各多少个?
SELECT
s.gender, count(s.gender) as 个数
FROM
student as s
WHERE
s.age >= 18
GROUP BY
s.gender
-
-
-
where语句:将查询结果分组前的符合条件返回数据,不符合条件的过滤掉,即先过滤再分组。where后面不能使用聚合函数。
-
having语句:在分组之后过滤数据,即先分组再过滤。having后面可以使用聚合函数
-
-
-
分页查询
-
使用关键字 limit,它是mysql中的方言操作
-
作用:对查询的结果值进行分页展示,每次显示多少条记录
-
语法: select 字段列表 from 表名 where 条件 group by 分组字段 having 分组之后条件 order by 升降序 limit 分页限定条件
-
分页限定条件 -----> 起始值 展示的记录数 limit offset,length
-
1 -- 查询学生表中的数据,从第一条开始,每页显示2条,第一次只能看到前两条
2 SELECT
3 s.username as 姓名,s.age as 年龄,s.gender as 性别
4 FROM
5 student as s
6 LIMIT
7 0,2
8
9 -- 查询学生表中的数据,从第4条,展示3条
10 SELECT
11 *
12 FROM
13 student
14 LIMIT
15 3,3
16 -- 分页 转换分页查询的起始值和页码数,每页展示的个数确定的
17 -- 0,15 第一页
18 -- 15,15 第二页
19 -- 30,15 第三页
20
21 -- 查询第28页的数据 15条记录
22 -- 页码数已知的 pageNum 起始值是未知的 beginNum ,记录数为num
23 -- totalNum 总记录数 根据记录数进行分页
24 -- beginNum = (pageNum - 1) * num
25 LIMIT
26 (pageNum - 1) * num;
27 -- 如果你查询的记录值是从第一条开始的,这个0可以省略
28 SELECT
29 *
30 FROM
31 student as s
32 LIMIT
33 5;
34 -- 如果你查询的是最后几条,有几条显示几条,不会报分页错误
35 -- 查询从第三条开始,查询5条
36 SELECT
37 *
38 FROM
39 student as s
40 LIMIT
41 2,5;
-
图形化界面工具 Navicat
-
备份
选中数据库右键 ----> 转储sql文件----> 结构和数据 --->指定磁盘中sql文件存储的位置。
-
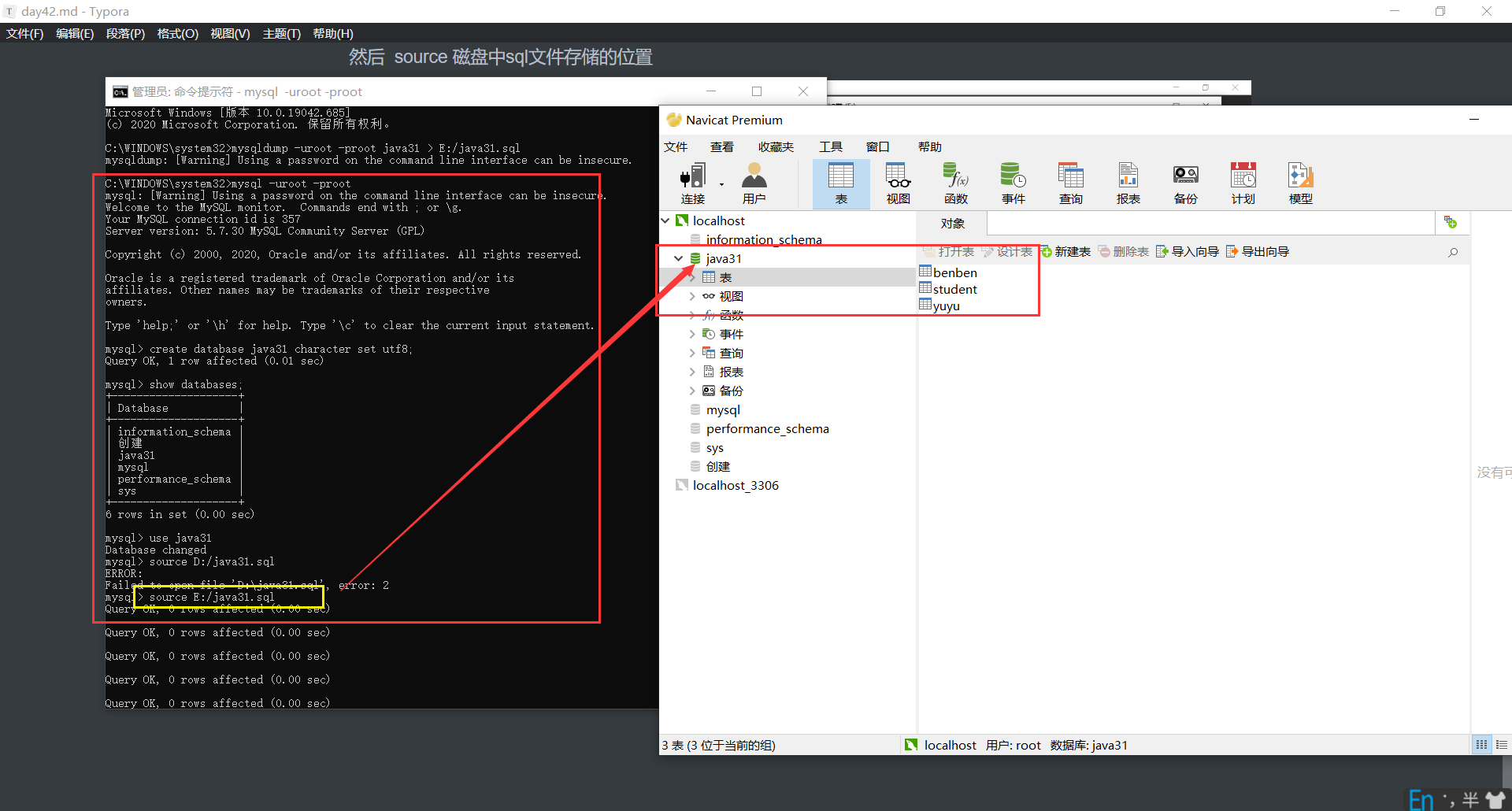
还原
先通过Navicat创建一个数据库(需要和sql文件中的数据库保持同名) --->右键运行sql文件----->浏览磁盘中存储的sql文件,点击运行,最后------>刷新。
-
-
dos指令操作
-
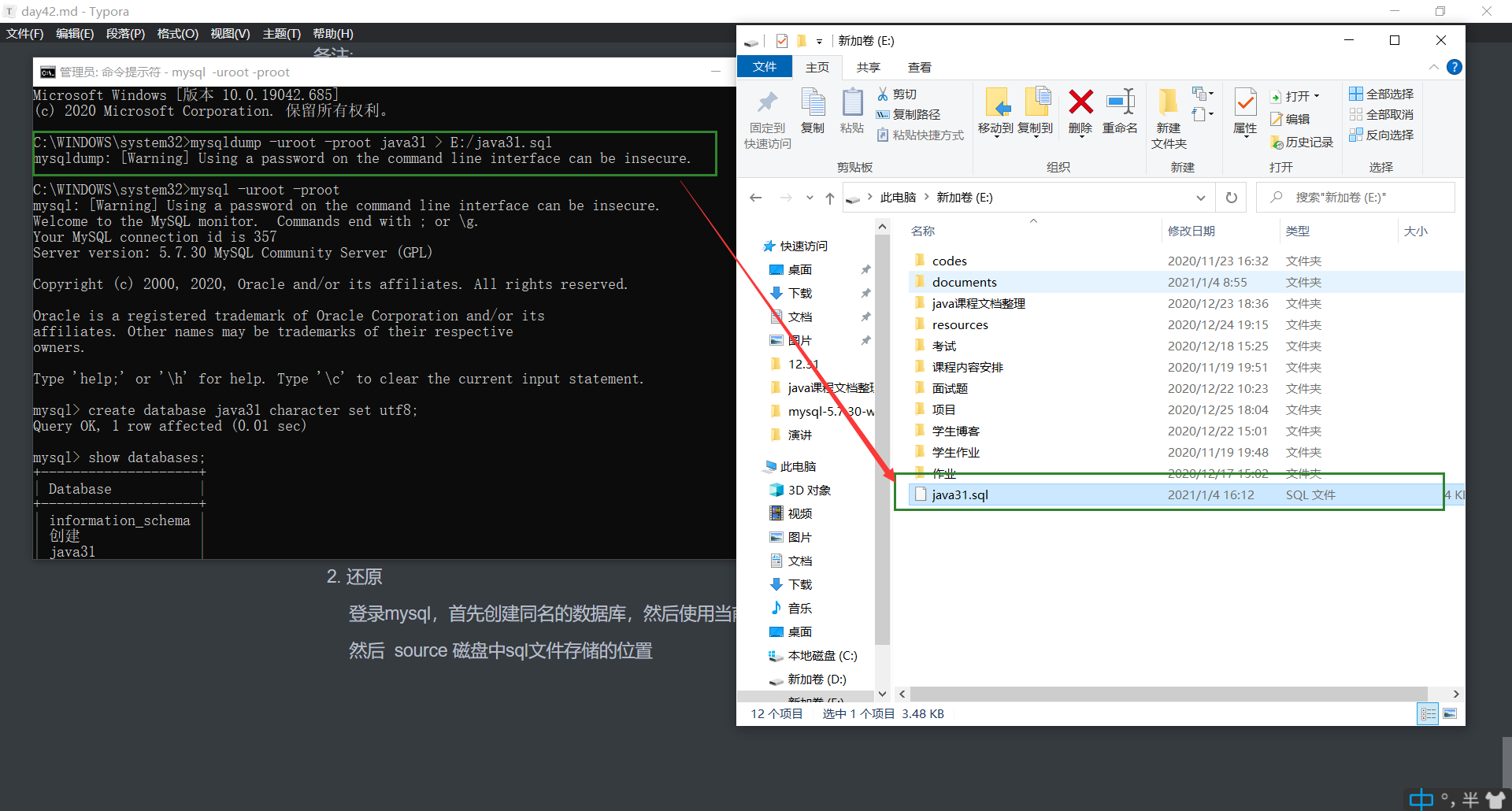
备份
在不登录的情况下使用 mysqldump -u登录名 -p登录密码 备份数据库名 > 存储磁盘的位置(绝对路径)
-
还原
-
登录mysql,首先创建同名的数据库,然后使用当前创建的数据库 use 创建数据库名
然后 source 磁盘中sql文件存储的位置
还原:
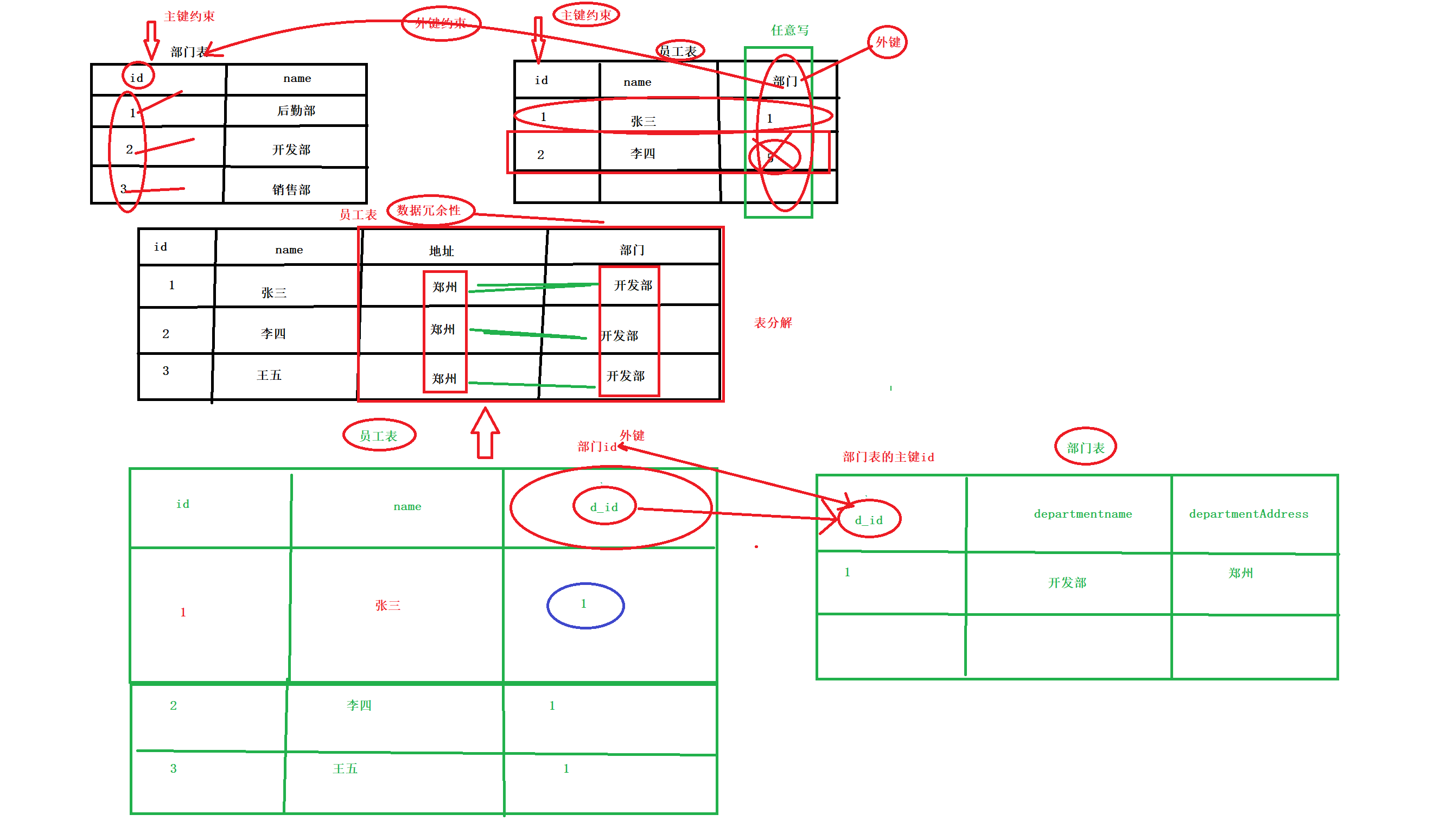
数据库表的约束
-
对表中的数据进行限定,保证数据的有效性、完整性和正确性。一个表一旦添加了约束,那么不正确的数据将无法添加进来,所以一般约束在创建表设定字段的时候添加上
-
主键约束
-
主键:一般是用来唯一标识数据库表中的某一条记录,不能为空
-
通常情况下,一般会给表添加一个id字段,用作唯一标识,设置为主键,主键一般是提供给数据库操作使用的(查询,修改,删除等等),主键不能重复,也不能为空。
比如: 一个人的身份证号、一个人手机号,一个学生的学号,一个员工工号
-
语法: 使用关键字 primary key
-
操作:
-- 查询
SELECT * FROM user;
-- 非法数据插入 唯一 不重复
INSERT INTO user values(7,'0008','123123','小花','12312312313','女',19);
-- 非法数据插入 null值插入 非空
INSERT INTO user values(null,'0008','123123','小花','12312312313','女',19);
-- 删除主键 sql语句
alter table user drop PRIMARY key;
-- 添加主键
alter table user add PRIMARY KEY(id);
如果希望在添加表记录时,不设定表中主键值,系统会自动给主键添加自增值
-- 非法数据插入 null值插入
INSERT INTO user values(null,'0010','123123','小周','12312312313','男',25);
alter table user auto_increment = 起始值;
- 唯一约束
概念:字段值唯一,不允许重复
关键字: unique
语法: 字段名 字段数据类型 unique
-- 插入数据
insert into role values(null,'CEO');
insert into role values(null,'manager');
insert into role values(null,'CTO');
-- 查询角色表
SELECT * from role;
insert into role values(null,null);
-
非空约束
-
概念:记录中的某个字段不能为null
-
-
-- 创建一张部门表
create table department (
id int PRIMARY KEY auto_increment, -- id 主键自增
departmentname VARCHAR(10) not null -- 部门不能为空
)
insert into department values(null,'总裁办');
insert into department values(null,'财务部');
insert into department values(null,'人事部');
insert into department values(null,'研发部');
insert into department values(null,'销售部');
-- 查询该表数据
SELECT * from department;
insert into department values(null,null);
-
概念:当没有给字段赋值,系统会赋上一个指定的默认值
-
语法: 字段名 字段数据类型 default 默认值
-
-
-- 创建一张表 employee 员工表
create table employee (
id int PRIMARY key auto_increment,
username VARCHAR(10) not null,
gender VARCHAR(1) DEFAULT '男',
age int
)
insert into employee(id,username,age) values(null,'小孙',20);
-- 查询员工表
SELECT * from employee;
insert into employee(id,username,gender,age) values(null,'小丽','女',20);
如果给表中的 某个字段既添加了非空约束又添加了唯一约束,那么该字段是不是主键呢?