关于Requests代理,你必须知道的
说到代理,写过爬虫的小伙伴一定都不陌生。但是你的代理真的生效了么?
代理主要分为以下几类:
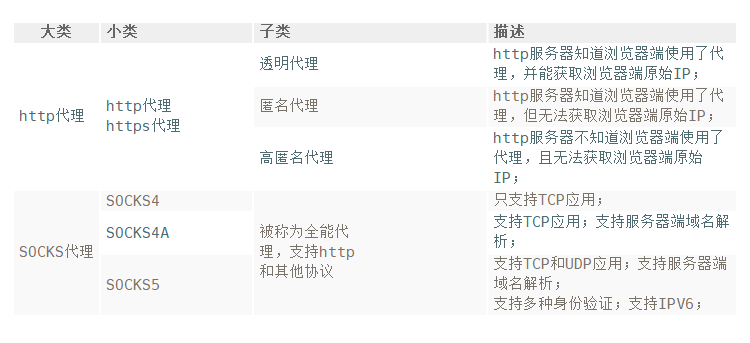
如果是爬虫的话,最常见的选择是高匿代理。
Requests 设置代理非常方便,只需传递一个 proxies 参数即可。如官方示例:
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('http://example.org', proxies=proxies)
留意一个地方,proxies 字典中有两个 key :https 和 http,为什么要写两个 key,如果只有一个可以么?
试试就知道了
准备验证函数
这个函数会使用代理去访问两个 IP 验证网站,一个是 https,一个是 http。
import requests
from bs4 import BeautifulSoup
def validate(proxies):
https_url = 'https://ip.cn'
http_url = 'http://ip111.cn/'
headers = {'User-Agent': 'curl/7.29.0'}
https_r = requests.get(https_url, headers=headers, proxies=proxies, timeout=10)
http_r = requests.get(http_url, headers=headers, proxies=proxies, timeout=10)
soup = BeautifulSoup(http_r.content, 'html.parser')
result = soup.find(class_='card-body').get_text().strip().split('''
''')[0]
print(f"当前使用代理:{proxies.values()}")
print(f"访问https网站使用代理:{https_r.json()}")
print(f"访问http网站使用代理:{result}")
测试
-
Case 1
proxies = { 'http': '222.189.244.56:48304', 'https': '222.189.244.56:48304' } validate(proxies)输出
当前使用代理:dict_values(['222.189.244.56:48304', '222.189.244.56:48304']) 访问https网站使用代理:{'ip': '222.189.244.56', 'country': '江苏省扬州市', 'city': '电信'} 访问http网站使用代理:222.189.244.56 China / Nanjing结果: 访问两个网站均使用了代理
-
Case 2
proxies = { 'http': '222.189.244.56:48304' } validate(proxies)输出
当前使用代理:dict_values(['222.189.244.56:48304']) 访问https网站使用代理:{'ip': '118.24.234.46', 'country': '重庆市', 'city': '腾讯'} 访问http网站使用代理:222.189.244.56 China / Nanjing结果: 只有http请求使用了代理
-
Case 3
proxies = { 'https': '222.189.244.56:48304' } validate(proxies)输出
当前使用代理:dict_values(['222.189.244.56:48304']) 访问https网站使用代理:{'ip': '222.189.244.56', 'country': '江苏省扬州市', 'city': '电信'} 访问http网站使用代理:118.24.234.46 China / Nanning结果: 只有https请求使用了代理
其他测试
通过 wireshark 抓包发现,当协议不匹配时,根本不会向代理服务器发起请求。
通过 postman 测试,结果与 Requests 一致,协议不同的情况下,不会走代理。
猜测可能是一种约定或者规则,类似 PAC ?(如果你知道答案,请告诉我)
寻找答案
从源码入手试试?在requests.ultis 中找到了这个函数:
def select_proxy(url, proxies):
"""Select a proxy for the url, if applicable.
:param url: The url being for the request
:param proxies: A dictionary of schemes or schemes and hosts to proxy URLs
"""
proxies = proxies or {}
urlparts = urlparse(url)
if urlparts.hostname is None:
return proxies.get(urlparts.scheme, proxies.get('all'))
proxy_keys = [
urlparts.scheme + '://' + urlparts.hostname,
urlparts.scheme,
'all://' + urlparts.hostname,
'all',
]
proxy = None
for proxy_key in proxy_keys:
if proxy_key in proxies:
proxy = proxies[proxy_key]
break
return proxy
答案揭晓了,Requests 会根据目标 url 的协议按照一定顺序来为它选择代理。就拿上面的 Case 2 来说:
proxies = {
'http': '222.189.244.56:48304'
}
请求http://ip111.cn/时,按照以下顺序在 proxies 字典中为这个链接选用代理:
- 协议+域名 :
http://222.189.244.56 - 协议:
http - all + 域名:
all://222.189.244.56 - all:
all
在第 2 步匹配到222.189.244.56:48304,然后就使用这个代理去访问目标地址。
而在请求https://ip.cn时,按照上面顺序匹配不到任何内容,就使用本地的 ip 去访问目标地址了。
这样也就能说明上面 3 个例子了。
扩展
官方示例中的代理包含协议,而我们测试的例子中没有但同样能够成功访问。这又是为什么呢?
# 官方的
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
# 我们的
proxies = {
'http': '222.189.244.56:48304',
'https': '222.189.244.56:48304'
}
答案同样可以在源码里找到,请看下面这两个函数:
requests.apdpters
def get_connection(self, url, proxies=None):
"""Returns a urllib3 connection for the given URL. This should not be
called from user code, and is only exposed for use when subclassing the
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
:param url: The URL to connect to.
:param proxies: (optional) A Requests-style dictionary of proxies used on this request.
:rtype: urllib3.ConnectionPool
"""
proxy = select_proxy(url, proxies)
if proxy:
proxy = prepend_scheme_if_needed(proxy, 'http')
proxy_url = parse_url(proxy)
if not proxy_url.host:
raise InvalidProxyURL("Please check proxy URL. It is malformed"
" and could be missing the host.")
proxy_manager = self.proxy_manager_for(proxy)
conn = proxy_manager.connection_from_url(url)
else:
# Only scheme should be lower case
parsed = urlparse(url)
url = parsed.geturl()
conn = self.poolmanager.connection_from_url(url)
return conn
看这一行代码:proxy = prepend_scheme_if_needed(proxy, 'http'),找到这个函数的定义:
def prepend_scheme_if_needed(url, new_scheme):
"""Given a URL that may or may not have a scheme, prepend the given scheme.
Does not replace a present scheme with the one provided as an argument.
:rtype: str
"""
scheme, netloc, path, params, query, fragment = urlparse(url, new_scheme)
# urlparse is a finicky beast, and sometimes decides that there isn't a
# netloc present. Assume that it's being over-cautious, and switch netloc
# and path if urlparse decided there was no netloc.
if not netloc:
netloc, path = path, netloc
return urlunparse((scheme, netloc, path, params, query, fragment))
从注释中可以找到答案:
如果代理提供了协议,不做改变;如果代理没有协议的话,就为代理加上http协议。
结论
- Requests 会按照目标url的协议来为它配置代理。基于此你可以为不同的协议甚至不同域名设置不同的代理,如果想为所有请求使用同一个代理,那直接使用 all 作为 key 来设置即可。
- 代理地址如果没有指明协议,则默认使用 http 请求。