http://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://www.jianshu.com/p/9dc9f41f0b29
机器学习面试100题: https://blog.csdn.net/T7SFOKzorD1JAYMSFk4/article/details/78960039
https://www.julyedu.com/question/topic_list/26
RNN 是包含循环的网络,允许信息的持久化。

当相关信息和当前预测位置之间的间隔不断增大时,RNN 缺乏学习到如此远的信息的能力。
RNN前向传导公式:
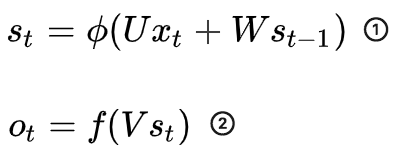
其中:![]()
链式法则:

$s_t = phi(Ux_t + Ws_{t-1} ) = phi(W'_{(w)}, s_{{t-1}(w)}) = phi(U'_{(u)}, s_{{t-1}(u)})$
$frac{partial{s_t}}{partial{w}} = frac{partial{s_t}}{partial{s_{t-1}}} frac{partial{s_{t-1}}}{partial{w}} + frac{partial{s_t}}{partial{w'}}$
上面的$W'_{(w)} = w$。反向传播计算时,都是实际数值代入计算。
对于 求偏导不存在依赖问题;但是对于
求偏导的时候,由于时间序列,存在长期依赖的情况(t时刻的隐层状态依赖于之前的每一个状态及输入),($s_t$与$s_{t-1}$),链式法则,导致rnn梯度消失或梯度爆炸。
假设初始状态 为0,
有三段时间序列时,由 ① 带入②可得到
各个状态和输出
状态:
输出:
状态:
输出:
状态:
输出:
现在只对 时刻的
求偏导,由链式法则得到:
③
④
⑤
可以简写成:
⑥
观察③④⑤式,可知,对于 求偏导不存在依赖问题;但是对于
求偏导的时候,由于时间序列长度,存在长期依赖的情况(主要是中间隐层状态偏导连乘导致)。【公式4,5中间一项少了一步】
https://zhuanlan.zhihu.com/p/53405950 【见该回答】
http://blog.sina.com.cn/s/blog_4c9dc2a10102xa00.html
https://www.zhihu.com/question/44895610 【见第二个回答】
LSTM避免梯度消失的原因: https://weberna.github.io/blog/2017/11/15/LSTM-Vanishing-Gradients.html#fn:3
![]()
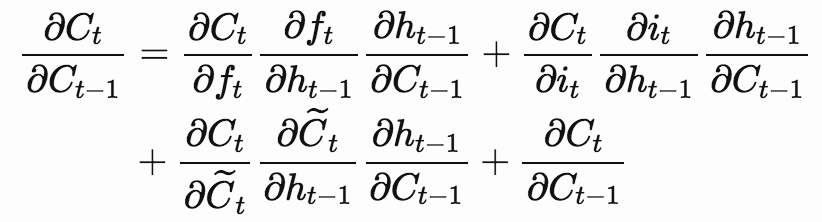
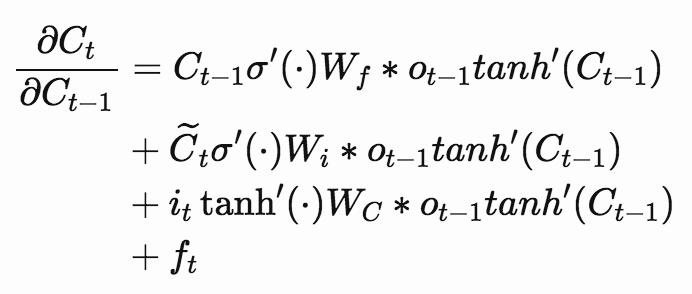
通过调整$f_t$的值来避免梯度消失或梯度爆炸
Long Short Term 网络(LSTM)是一种 RNN 特殊的类型,可以学习长期依赖信息。
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
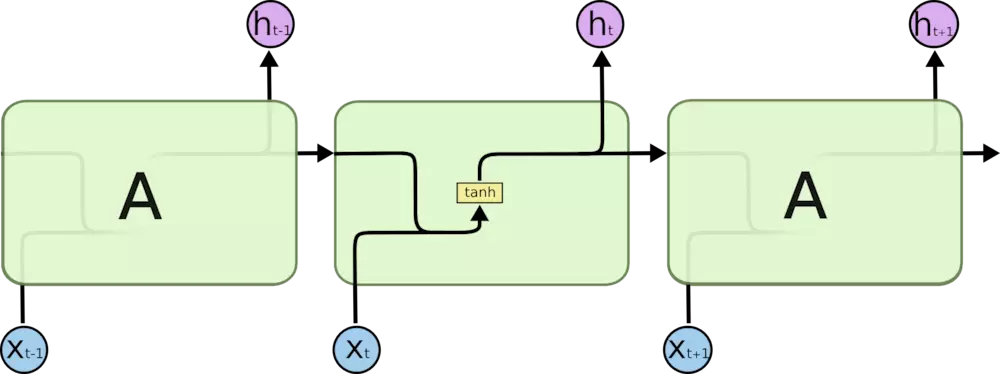
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
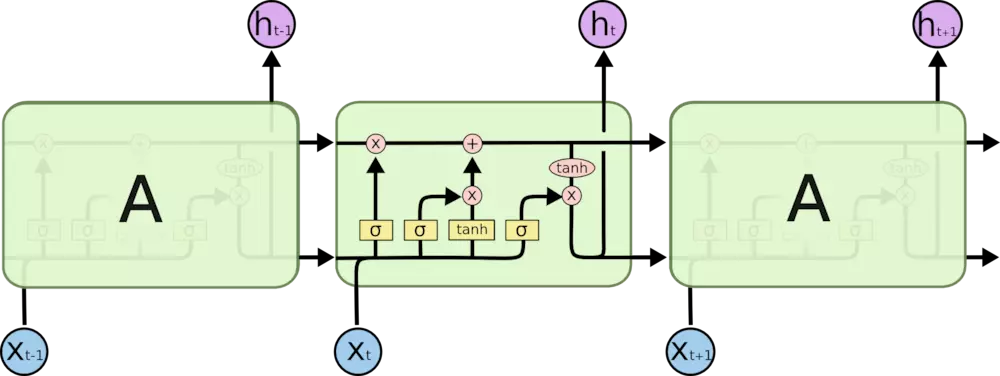
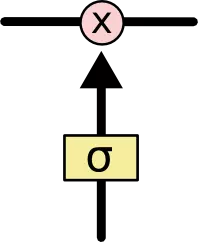
上图中相应图标的含义:

LSTM 的关键就是记忆单元,水平线在图上方贯穿运行。
记忆单元类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择性通过的方法。他们包含一个 sigmoid 神经网络层和一个按位的乘法操作。
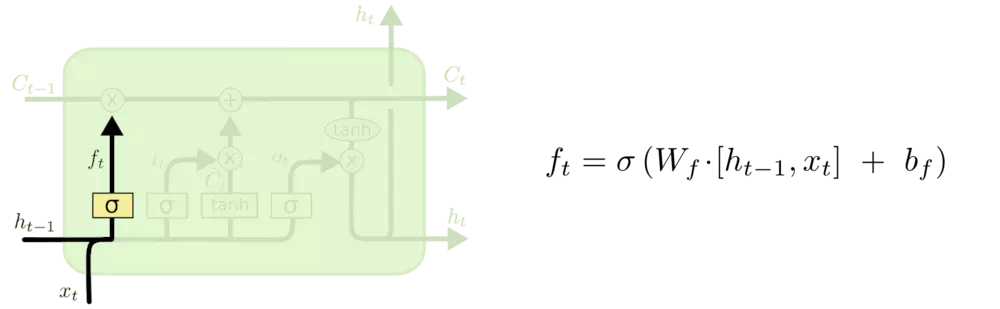
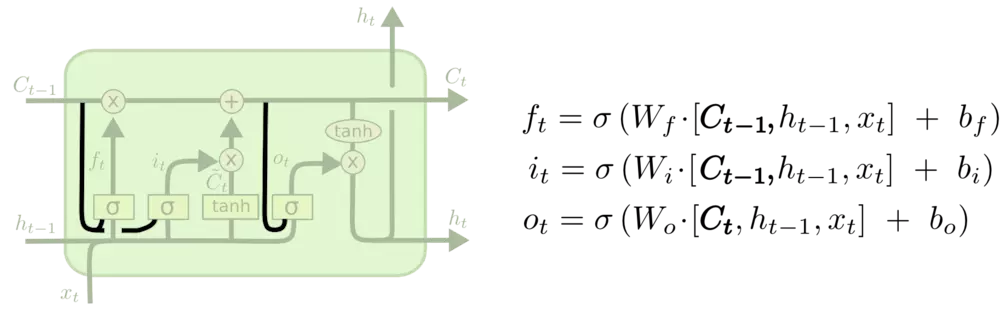
LSTM中结构分析:
输入门$i_t$, 遗忘门$f_t$, 输出门$o_t$:输入门控制当前计算的新状态以多大程度更新到记忆单元中;遗忘门控制前一步记忆单元中的信息有多大程度被遗忘掉,输出门控制当前的输出有多大程度上取决于当前的记忆单元。
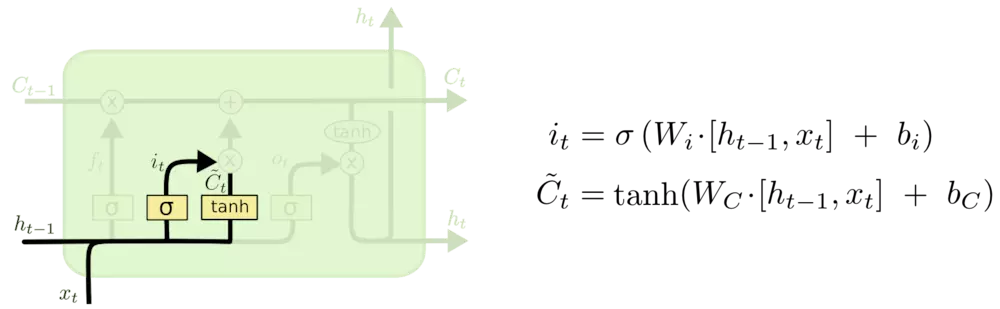
更新细胞状态:

输出信息:
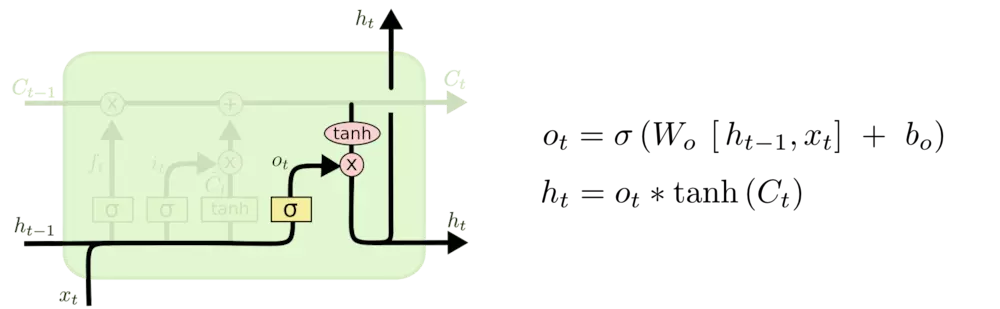
LSTM各模块使用的激活函数:
sigmoid函数的输出在0~1之间,符合门控的物理定义,且当输入较大或较小时,其输出会非常接近0或1,从而保证该门开或关。
tanh函数,用在了状态和输出上,是对数据的处理,其输出在-1~1之间,与大多数场景下特征分布是0中心的吻合,此外,tanh函数在输入为0附近相比sigmoid函数有更大的梯度,通常使模型收敛更快。用其他激活函数或许也可以【
参见A Critical Review of Recurrent Neural Networks for Sequence Learning的section4.1】
LSTM变体:
1、让门层接受记忆单元的输入
2、取消输入门,用遗忘门的补替代。

3、Gated Recurrent Unit (GRU):

与LSTM对比:
1、GRU只有两个门:reset gate $r_t$ 和 update gate $z_t$
2、如果reset gate为1,而update gate为0的话,则GRU完全退化为一个传统RNN
3、在实践中,一般认为LSTM和GRU之间并没有明显的优胜者。因为GRU具有较少的参数,所以训练速度快,而且所需要的样本也比较少。而LSTM具有较多的参数,比较适合具有大量样本的情况,可能会获得较优的模型。在Andrew的课程中表示,如果只能选择一个模型,那么LSTM是大家的default RNN。
LSTM输入输出:https://mp.weixin.qq.com/s/aV9Rj-CnJZRXRm0rDOK6gg
1、input_shape=(13, 5), 在NLP中可以理解为一个句子是 13个词,所以LSTM神经网络在时间上展开是 13个框, 每个词对应的词向量是 5 维,即每个时刻的输入$X_t$是 5 维的向量.
2、keras中的model.add(LSTM(10))中, 10 代表LSTM的hidden state $h_t$ 是 10维,
sequence to sequence模型: https://zhuanlan.zhihu.com/p/25366912
RNN Encoder-Decoder结构,包含两部分,一个负责对输入的信息进行Encoding,将输入转换为向量形式。然后由Decoder对这个向量进行解码,还原为输出序列。
而RNN Encoder-Decoder结构就是编码器与解码器都是使用RNN算法,一般为LSTM。
LSTM的优势在于处理序列,它可以将上文包含的信息保存在隐藏状态(细胞状态)中,这样就提高了算法对于上下文的理解能力。
Encoder与Decoder各自可以算是单独的模型,一般是一层或多层的LSTM。
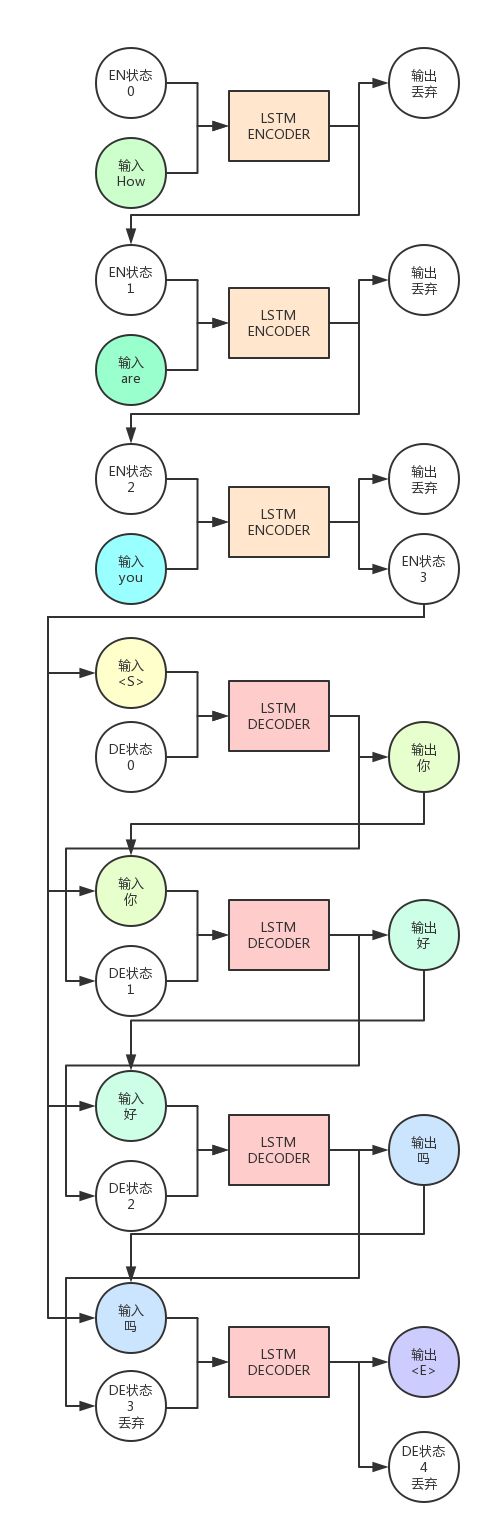
上图中,LSTM Encoder是一个LSTM神经元,Decoder是另一个,Encoder自身运行了`3`次,Decoder运行了`4`次。
可以看出,Encoder的输出会被抛弃,我们只需要保留隐藏状态(即图中EN状态)作为下一次ENCODER的状态输入。
Encoder的最后一轮输出状态会与Decoder的输入组合在一起,共同作为Decoder的输入。
而Decoder的输出会被保留,当做下一次的的输入。注意,这是在说预测时时的情况,一般在训练时一般会用真正正确的输出序列内容,而预测时会用上一轮Decoder的输出。
给Decoder的第一个输入是`<S>`,这是我们指定的一个特殊字符,它用来告诉Decoder,你该开始输出信息了。
而最末尾的`<E>`也是我们指定的特殊字符,它告诉我们,句子已经要结束了,不用再运行了。
Trick:
虽然LSTM能避免梯度消失问题,但是不能对抗梯度爆炸问题(Exploding Gradient)。
为了对抗梯度爆炸,一般会对梯度进行裁剪。
梯度裁剪的方法一般有两种,一种是当梯度的某个维度绝对值大于某个上限的时候,就剪裁为上限。
另一种是梯度的L2范数大于上限后,让梯度除以范数,避免过大。