SQL常见操作回顾
以下学习内容为巩固提升,为后面做案例打下铺垫
回顾知识点
最常用SQL:
select ... from ... where ... insert into ... values... update ... set ...
五大子句
执行顺序:From->where->group by->having->select->order by->limit
where条件
导入:并不是每次都从磁盘中读取全部数据,并且还慢,如何做按要求取部分数据?
where原理
1:用来判断数据:筛选数据,where子句返回结果:0或者1,0代表false,1代表true,所以SQL语句是从1开始的 2:where是唯一一个是直接从磁盘获取数据的时候就开始判断的条件,从磁盘取出一条记录,开始进行where判断:判断的结果如果成立就保存到内存中,如果失败则直接放弃
SQL语法
语法:
SELECT field1, field2,...fieldN FROM table_name1, table_name2...
[WHERE condition1 [AND [OR]] condition2.....
理解:
- 查询语句中你可以使用一个或者多个表,表之间使用逗号, 分割,并使用WHERE语句来设定查询条件。
- 你可以在 WHERE 子句中指定任何条件。
- 你可以使用 AND 或者 OR 指定一个或多个条件。
- WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
- WHERE 子句类似于程序语言中的 if 条件,根据 MySQL 表中的字段值来读取指定的数据。
注意:
1:常见运算符: >,<,<=,>=,=<>,like模糊,between and区域之间,in/not in 2:逻辑运算符 &&(and),||(or),|(not)
运算符的优先级(了解)
运算符由上到下优先级依次由低到高。

案例demo
业务需求:
找出id为1,3,5的学生 1:使用逻辑判断 select * from my_student where id=1 || id=3 || id=5 2:落在集合中in(1,3,5) select * from my_student where id in(1,3,5)
找出身高在180到190之间的学生 select * from my_student where height>=180 and height<=190; select * from my_student where between 180 and 190; between本身是闭区间;between左边的值必须小于或者等于右边的值。
小结及课堂纪要
group by 分组
观察:
xxxxxxxxxx
select sum(p.quantity),avg(p.quantity),max(p.quantity),min(p.quantity),count(*) from itcast.shopproduct p;
导入:实际业务中,我们不只要对一组数据集做整体处理或者统计,很多时候我们希望数据集内部相互比较,如今年去去年GDP增长了8%,求学多年,我们都是被择优录取,即总分最高的录取……这都是相互比较,前者年份之间相互比较,后者每个人的总成绩相互比较,这个比较的最小个体或维度,即为分组。
概述原理
根据一个或多个列对结果集进行分组,最终得到一个分组汇总表。
1:根据某个字段进行分组(相同的放一组,不同的放不同的组) 2:是为了统计数据(按组统计),按分组字段进行数据统计
执行过程:
1,当 FROM test Group BY name该句执行后,我们想象生成了虚拟表3,如下所图所示,生成过程是这样的:group by name,那么找name那一列,具有相同name值的行,合并成一行,如对于name值为aa的,那么<1 aa 2>与<2 aa 3>两行合并成1行,所有的id值和number值写到一个单元格里面。接下来就要针对虚拟表3执行Select语句了。
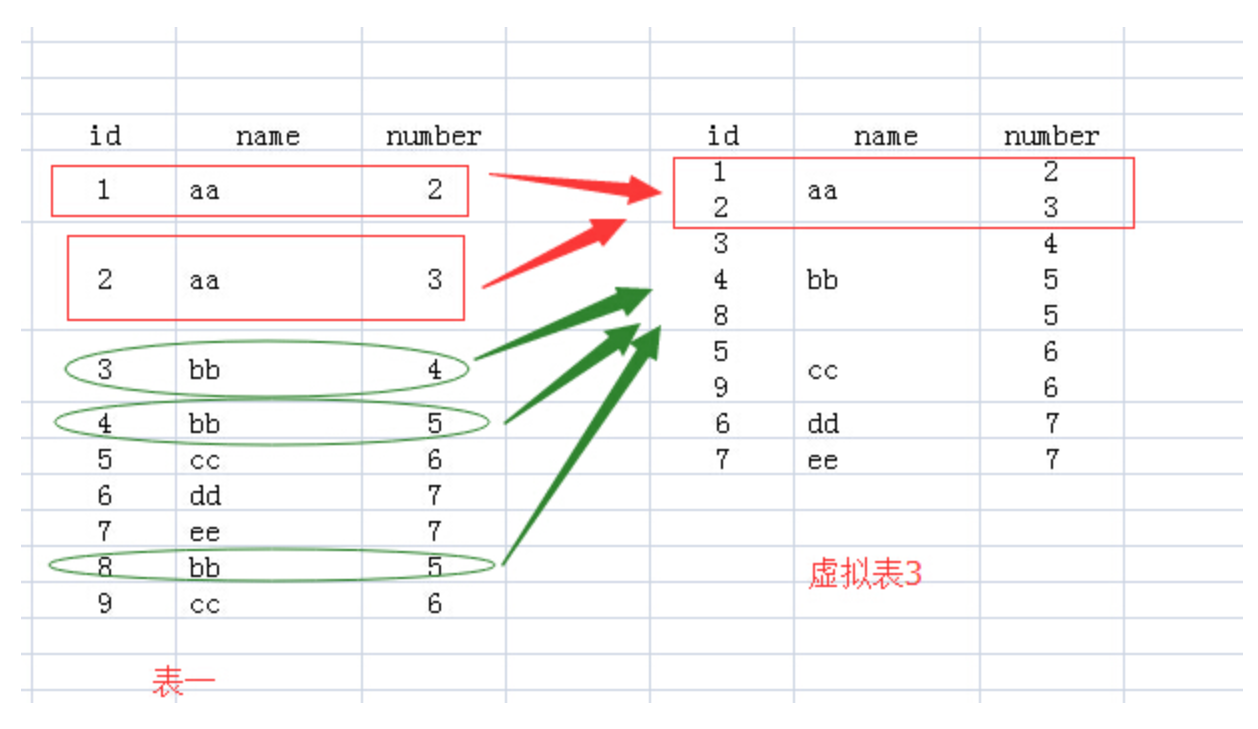
2,那么对于id和number里面的单元格有多个数据的情况怎么办呢?
答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如count(id),sum(number),而每个聚合函数的输入就是每一个多数据的单元格。
即 select name, count(id),sum(number) FROM test Group BY name;
同时也可看出,SELECT子句中的输出列名必须为分组依据列或聚合函数。(非严格模式除外)
SQL统计函数
1:count(): 统计分组后的记录数: 每一组有多少记录 2:Max() 统计每组中最大的值。(求出字符串按照从左到右按照字典序排序输出) 3:Min() 统计最小值 4:Avg() 统计平均值 5:Sum() 统计和
补充:DISTINCT:去重
分组后默认组内取第一条
xxxxxxxxxx
select s.s_sex,s.s_age,s.s_name from student s GROUP BY s.s_sex;
【组内取第一条】分组后默认排序取第一条,不规范写法,mysql升级后已修改为:sql_mode=only_full_group_by
严格模式下,非聚合字段,都应该放在group by后。
分组后会组间排序
【组间排序】默认是升序,group by 字段[asc/desc]; --对分组后的结果合并之后的整个结果进行了排序。
多个字段分组排序
主分组,次分组,以改变统计维度,或颗粒度。
xxxxxxxxxx
select s.s_sex,s.s_age,count(*) from student s GROUP BY s.s_sex ASC ,s.s_age desc;
加WHERE排除
【分组前排除】
在GROUP BY子句之后使用WHERE子句
分组查询可以在形成组和计算列函数之前,具有消除非限定行的标准 WHERE 子句
xxxxxxxxxx
select s.prod_class,GROUP_CONCAT(s.sales_num) from prod_sales s where s.sales_num>90 group by s.prod_class;
加HAVING 过滤
【对分组结果进行过滤 】
1,在GROUP BY子句之后使用HAVING子句,对满足条件的组返回结果。
2,HAVING子句可包含一个或多个用AND和OR连接的谓词。
xxxxxxxxxx
select s.prod_class,GROUP_CONCAT(s.prod_id),count(*) as nums
from prod_sales s
where CHAR_LENGTH(s.prod_id)>=5
group by s.prod_class
having nums>3 ;
group_concat(字段)
【查看组内所有的组员信息】完成对分组的结果中的某个字段进行字符串连接(保留该组所有的某个字段,例如学生表中的学生姓名)
xxxxxxxxxx
select s.s_sex,GROUP_CONCAT(s.s_name) as names,count(*) from student s group by s.s_sex;
WITH ROLLUP子句
【回溯统计】任何一个分组后都会有一个小组,最后都需要向上级分组进行汇报统计。可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)
单字段回溯
补充:Coalease coalesce 来设置一个可以取代 NUll 的名称,coalesce(a,b,c)找出一个不为null来替代null.
ifnull(a,b)--如果a为Null ,返回b.
xxxxxxxxxx
select COALESCE(s.s_sex,'总数') as s_sex,count(*) from student s GROUP BY s.s_sex desc with rollup;
xxxxxxxxxx
select s.prod_class,sum(s.sales_num),avg(s.sales_num),count(*) from prod_sales s group by s.prod_class with ROLLUP;
xxxxxxxxxx
-- 函数 查资料,自己验证
select ifnull(null,0);
select COALESCE(null,0);
select COALESCE(null,null ,null,0);
多字段回溯
分析第一层分组会有此回溯,第二次分组要看到第一次分组的组数,组数是多少,回溯就是多少,然后加上第一层回溯就行了。
xxxxxxxxxx
select COALESCE(s.shop_id,'总计') as shop_id,coalesce(s.product_id,'小计')as product_id,sum(s.quantity)
from itcast.shopproduct s
group by s.shop_id,s.product_id with rollup;
组内排序
【重要且复杂,下次课讲】
小结及课堂纪要
having 筛选
导入:还说择优录取的例子。是不是只要高于临界点的学生,低于的就不要了?也就是往往分组统计之后之后,我们只要符合条件的数据。那么SQL怎么筛选出我们想要的数据呢?
作用:对统计的数据进一步筛选
理解:1,通常与GROUP BY语句联合使用,用来过滤由GROUP BY语句返回的记录集。 2, HAVING语句的存在弥补了WHERE关键字不能与聚合函数联合使用的不足。
xxxxxxxxxx
select s.prod_class,GROUP_CONCAT(s.prod_id),count(*) as nums from prod_sales s
where CHAR_LENGTH(s.prod_id)>=5 group by s.prod_class having nums>3 ;
where与having区别--- 补充一详细讲
小结及课堂纪要
order by 排序
导入:还是择优录取。一个地区总要分出个状元,榜眼,探花吧?很多时候也要比出个高矮胖瘦吧?这就是排序,那么SQL怎么对输出结果进行一个排序呢?
含义
使用 ORDER BY 子句将查询数据排序后再返回数据。
理解:
1:默认是升序,order by 字段 [asc/desc]
2: 分组后就取一条记录,分组是为了统计
xxxxxxxxxx
select * from itcast.shopproduct p group by p.shop_id;
3:排序,取出所有的记录,排序是为了展示
xxxxxxxxxx
select * from itcast.shopproduct p order by p.shop_id;
4:排序可以进行多字段排序 先根据某个字段进行排序,然后排序好的内容,再按照某个字段再次进行排序
xxxxxxxxxx
select * from itcast.shopproduct p order by p.shop_id ,p.quantity desc;
注意:
排序跟使用的字符集有关。同事需要关注字段的数据类型。
补充:
拼音排序方法:把字段进行转码为gbk字符集。(因为GBK内码编码时本身就采用了拼音排序的方法(常用一级汉字3755个采用拼音排序,二级汉字就不是了,但考虑到人名等都是常用汉字,因此只是针对一级汉字能正确排序也够用了)。)
xxxxxxxxxx
select * from student s order by convert(s.s_name using gbk) ;
小结及课堂纪要
limit 限制结果集
导入:还是择优录取。高考成绩一般只对状元,榜眼,探花进行奖励吧?还有比如数据太多,我们分段查询,每页只要20条,此时就是结果集进行了一限制。那么SQL又是怎么对输出结果进行限制的呢?
含义:
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。
语法:SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset ;
解释:1,LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。初始记录行的偏移量是 0(而不是 1,index序列)。
2, 为了与 PostgreSQL 兼容,MySQL 也支持句法: LIMIT # OFFSET #。(用的比较少 #表 数字)
limit有两种使用方式
1:只用来限制长度(数据量);limit数据量.取前几条。
应用:limit 实现topN查询
xxxxxxxxxx
-- 取出销量最大的那条信息
select * from itcast.shopproduct p order by p.quantity desc limit 1;
select * from itcast.shopproduct p where p.quantity =(select max(p.quantity) from itcast.shopproduct p);
要是取出销量最好的前三条数据:(只有limit实现)
xxxxxxxxxx
select * from itcast.shopproduct p order by p.quantity desc limit 3;
2:限制起始位置,限制数量 : limit 起始位置,长度; 查询商品,前两个,记录数总0开始编号,索引为0;
xxxxxxxxxx
select * from itcast.shopproduct p limit 0,5;-- 等效 limit 5
select * from itcast.shopproduct p limit 2,5;-- 从第三条开始取,3-7行
select * from itcast.shopproduct p limit 5 OFFSET 2;-- 取5行偏移2行
应用:limit 实现分页
一、背景
查询返回的记录太多了,查看起来很不方便,怎么样能够实现分页查询呢? 二、分页原理
所谓分页显示,就是将数据库中的结果集,一段一段显示出来需要的条件 1、 怎么分段,当前在第几段(每页有几条,当前在第几页)
xxxxxxxxxx
前10条记录:SELECT * FROM table LIMIT 0,10;
第11至20条记录:SELECT * FROM table LIMIT 10,10;
第21至30条记录: SELECT * FROM table LIMIT 20,10;
2、公式:(当前页数-1)*每页条数,每页条数
xxxxxxxxxx
SELECT * FROM table LIMIT(PageNo - 1)*PageSize,PageSize;
注意:
1,limit子句必须放在整个查询语句的最后!
2,记录数索引从0开始。
小结及课堂纪要
补充一:where与having区别
sql中表示条件的主要用where、having 、on来引导。on回以后讲,学过的五大子句里where与having有什么区别呢?
xxxxxxxxxx
“Where”是一个约束声明,在查询数据库的结果返回之前对数据库中的查询条件进行约束,即在结果返回之前起作用,且where后面不能使用“聚合函数”;
“Having”是一个过滤声明,所谓过滤是在查询数据库的结果返回之后进行过滤,即在结果返回之后起作用,并且having后面可以使用“聚合函数”。
都是条件表达式,都是对数据进行筛选过滤。where是在判断数据从磁盘 读入内存或from子查询嵌套的时候,而having 主要是 判断分组统计之后的所有条件,所以having是在对 select查询的字段中或聚合条件 中进行的操作。即 where 只筛选from数据集,having主要对group by 进行过滤。
所以聚合函数是比较where和having的关键,所以先说下聚合函数。所谓聚合函数,是对一组值进行计算并且返回单一值的函数,在sql中常见于下面几个字眼:sum---求和,count---计数,max、min---最大小值,avg---平均值等。
1,where 只筛选from数据集,能返回True / False 就行。having必须从输出字段里筛选;
-- 观察且思考
select * from student s where s.id>3;
select s.id,s.stu_id,s.class_id,s.class_name from student s where s.id>3;
select s.stu_id,s.class_id,s.class_name from student s where s.main_class_flag='Y';
select s.stu_id,s.class_id,s.class_name from student s where 1=1;
select s.stu_id,s.class_id,s.class_name from student s where 1=0;
select * from products p1 join (select * from prod_sales p2 where p2.sales_num>100)p on p1.p_type=p.prod_class where p1.p_view>30;
select * from student s having s.id>3;
select s.id,s.stu_id,s.class_id,s.class_name from student s having s.id>3;
select s.stu_id,s.class_id,s.class_name from student s having s.main_class_flag='Y';
select s.stu_id,s.class_id,s.class_name from student s having 1=1;
select s.stu_id,s.class_id,s.class_name from student s having 1=0;
select * from products p1 join (select * from prod_sales p2 where p2.sales_num>100)p on p1.p_type=p.prod_class having p1.p_view>30;
结论:where筛选只有一种情况having不能替代,那就是having必须从输出字段里筛选,而where都可以。
原因:where是从from后的虚拟表筛选数据,条件为True,select就输出该行。having是从select输出虚拟表中,再次筛选,条件为True,select就最终输出该行。
2,有group by ,聚合条件必须是having,其他参考第一条。
xxxxxxxxxx
select s.stu_id,count(*) from student s group by s.stu_id having count(*)>1;
select s.stu_id,count(*) as num from student s group by s.stu_id having num>1;
select s.stu_id,max(s.class_id) from student s group by s.stu_id having count(*)>2;
select s.stu_id,s.main_class_flag,max(s.class_id) from student s group by s.stu_id,main_class_flag having s.main_class_flag='Y' ;
select s.stu_id,s.main_class_flag,max(s.class_id) from student s group by s.stu_id having s.main_class_flag='Y' ;-- 不准,非严格模式
select s.stu_id,max(s.class_id) from student s group by s.stu_id,main_class_flag having s.main_class_flag='Y' ;
select s.stu_id,max(s.class_id) from student s group by s.stu_id having s.main_class_flag='Y' ;-- select没有输出
select s.stu_id,count(*) from student s where count(*)>1 group by s.stu_id ;-- Invalid use of group function
select s.stu_id,count(*) as num from student s where num>1 group by s.stu_id ;-- Unknown column 'num' in 'where clause'
select s.stu_id,max(s.class_id) from student s where count(*)>2 group by s.stu_id ;-- Invalid use of group function
select s.stu_id,s.main_class_flag,max(s.class_id) from student s where s.main_class_flag='Y' group by s.stu_id,main_class_flag ;
select s.stu_id,s.main_class_flag,max(s.class_id) from student s where s.main_class_flag='Y' group by s.stu_id ;
select s.stu_id,max(s.class_id) from student s where s.main_class_flag='Y' group by s.stu_id,main_class_flag ;
select s.stu_id,max(s.class_id) from student s where s.main_class_flag='Y' group by s.stu_id ;
本质原因:SQL内部逻辑执行顺序,决定了条件加载的时机。
执行顺序:From->where->group by->having->select->order by->limit
最终总结:where 约束from数据集里的存在的字段,和逻辑条件; 而having 筛选select输出字段,和聚合函数这样的“伪字段”,以及逻辑条件。
小结及课堂纪要
补充二: Select语句执行顺序
导入:计算机是按流程来处理数据,或进行计算的。我们只有掌握了语句的内部执行顺序,我们才能更好的人机交互,写出更好的程序。那么计算机在执行Select语句时的顺序到底是什么样的呢?
复杂SQL语句的执行顺序
xxxxxxxxxx
select Bedrooms,count(*) from house_price where Bedrooms>=2 group by Bathrooms having count(*)>20 order by Bedrooms desc limit 1;
对于上述的复杂语句,我们需要知道执行顺序:
From->where->group by->having->select->order by->limit
【延伸】
原文链接:http://www.360doc.com/showweb/0/0/882415188.aspx
select查询语句的执行顺序,可以看出首先执行FROM子句,最后执行ORDER BY
执行顺序:
(1) FROM
(2) ON
(3) JOIN
(4) WHERE
(5) GROUP BY
(6) WITH {CUBE | ROLLUP}
(7) HAVING
(8)SELECT
(9) DISTINCT
(10) ORDER BY
(11) LIMIT
以上逻辑顺序简介
以上每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。只有最后一步生成的表才会返回给调用者。
xxxxxxxxxx
FROM:对FROM子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表VT1,选择相对小的表做基础表。
ON:对VT1应用ON筛选器,只有那些使为真才被插入到VT2。
OUTER (JOIN): 如果指定了OUTER JOIN(相对于CROSS JOIN或INNER JOIN),保留表中未找到匹配的行将作为外部行添加到VT2,生成TV3。
WHERE:对VT3应用WHERE筛选器,只有使为true的行才插入VT4。
GROUP BY:按GROUP BY子句中的列对VT4中的行进行分组,生成VT5。
CUTE|ROLLUP:把超组插入VT5,生成VT6。
HAVING:对VT6应用HAVING筛选器,只有使为true的组插入到VT7。
SELECT:处理SELECT列表,产生VT8。
DISTINCT:将重复的行从VT8中删除,得到VT9。
ORDER BY:将VT9中的行按ORDER BY子句中的列列表顺序,生成一个游标(VC10)。
LIMIT(TOP):从VC10的开始处选择指定数量或比例的行,生成表VT11,并返回给调用者。
小结及课堂纪要
as用法
导入:现实中我们可能会用到别名,也无非就是为了简化操作或记忆。同样数据库也是一样,当表名或字段名太长时,我们也会起个别名。那SQL会怎么做呢?
as 别名关键字。as 可理解为:用作、当成,作为;一般是重命名列名或者表名。(主要为了查询方便,AS可以不写,写上去规范一点)
(1)如:表text, 列 column_1,column_2 你可以写成
xxxxxxxxxx
select column_1 as 列1,column_2 as 列2 from text as 表;
-- 选择 column_1 作为 列1,column_2 作为 列2 从 text 当成 表
(2)子查询必须起别名。即使外层查询没有用到,也必须给子查询起一个别名,否则无法执行。
xxxxxxxxxx
select * from (select s.p_id,s.p_name from products_sales s) union (select p.p_id,p.p_name from products p);--1248 - Every derived table must have its own alias
出现了 Every derived table must have its own alias 错误 分析:alias是别名的意思,整个错误:每一张派生表必须有自己的名字,也就是说没有给派生表起名。
xxxxxxxxxx
select * from ((select s.p_id,s.p_name from products_sales s) union (select p.p_id,p.p_name from products p))a;
(3)别名是一种临时命名空间,像他语言的临时变量,出了作用域就失效了。
xxxxxxxxxx
select * from itcast.shopproduct p where p.quantity =(select max(p.quantity) from itcast.shopproduct p);
(4)as可以作为连接语句的操作符。
xxxxxxxxxx
sql:create table tablename as select * from tablename2;
解释:上面语句的意思就是先获取到tablename表中的所有记录,之后创建一张tablename表,结构和tablename2表相同,记录为后面语句的查询结果。
为表起别名意义:
①提高语句的简洁度 ②区分多个重名的字段
别名注意事项:
1,as可以省略,为了规范和可读性更高,一般不建议省略;
2,如果为表起了别名,则查询的字段就不能使用原来的表名去限定;
3,子查询和自关联必须起别名。
小结及课堂纪要
聚合函数使用
导入:数据分析要统计数据,就要用到统计函数,在SQL中一般叫聚合函数。那到底有哪些聚合函数呢?
导入house_price.csv
avg() 计算价格的平均值
x
select avg(Price) as avg_price from house_price
注:avg(Neighborhood) 对字符串进行avg操作返回0,这里的0其实代表无法计算,返回默认的0
如果列中出现"NULL",则跳过对应的行数据,计算其他非空行的数据的均值
count() 计算数据的总量
select count(*) from house_price
以上计算的是所有数据,包含空的行和null行
select count(price) from house_price
以上计算的是price列中非空的行数
统计Bedrooms中不同的取值
x
select DISTINCT Bedrooms from house_price
统计Price中不同的取值的个数
x
select count(DISTINCT Price) from house_price
找出house_price中Bedrooms不同取值的每个取值的个数
x
select Bedrooms,count(*) from house_price group by Bedrooms;
x
MySQL 版本>5.6的问题
--[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated column 'information_schema.PROFILING.SEQ' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
--- 问题原因 sql_mode=only_full_group_by
-- 解决方案
SET sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
sum(字段/表达式) 求和
找出house_price中不同取值(例如:取值为2,则为两室,为3则为3室)的Bedrooms的每个取值的房屋总价格**
x
select Bedrooms,sum(price) from house_price group by Bedrooms;
取别名后,可以以别名进行分组
x
select Bedrooms as br,sum(price) from house_price group by br;
找出house_price中不同取值的Bedrooms的房屋中每个取值对应的行数大于20个的房屋及其对应的总价格
x
select Bedrooms,sum(price) from house_price group by Bedrooms having count(*)>20;
找出house_price中不同取值的Bedrooms的房屋中每个取值对应的行数大于20个的房屋及其对应的总价格,并将数据按照总价格的升序排序
x
select Bedrooms,sum(price) from house_price group by Bedrooms having count(*)>20 order by sum(Price);
sum(表达式)
观察如下sql,你可以得出什么结论?
x
select count(*) from prod_sales p;
select count(p.sales_num) from prod_sales p;
select count(p.sales_num>200) from prod_sales p;
select count(*) from prod_sales p where p.sales_num>200;
select count(p.sales_num) from prod_sales p where p.sales_num>200;
select sum(p.sales_num>200) from prod_sales p;
select count(case when p.sales_num>200 then 1 else 0 end) from prod_sales p ;
select count(case when p.sales_num>200 then 1 else null end) from prod_sales p ;
select count(case when p.sales_num>200 then 1 end) from prod_sales p ;
select sum(case when p.sales_num>200 then 1 else 0 end) from prod_sales p ;
select sum(case when p.sales_num>200 then 1 else null end) from prod_sales p ;
select sum(case when p.sales_num>200 then 1 end) from prod_sales p ;
select sum(case when p.sales_num>200 then 10 else 0 end) from prod_sales p ;-- 对返回值求和
max()与min() 求最值
求各个房间数的最大最小房价
x
select a.Bedrooms ,max(a.Price),min(a.Price) from house_prices a GROUP BY a.Bedrooms;
小结及课堂纪要
聚合函数与null值:
SQL中AVG、COUNT、SUM、MAX 、min等函数对NULL值处理
观察:
x
-- part2 count() sum()
select count(*) from prod_sales p where p.sales_num>20000;
select count(p.prod_id) from prod_sales p where p.sales_num>20000;
select p.prod_class,count(*) from prod_sales p where p.sales_num>20000 GROUP BY p.prod_class;
select sum(p.sales_num>20000) from prod_sales p;
select sum(p.sales_num) from prod_sales p where p.sales_num>20000;
select p.prod_class,sum(p.sales_num) from prod_sales p where p.sales_num>20000 GROUP BY p.prod_class;
x
一、AVG()
求平均值
注意AVE()忽略NULL值,而不是将其作为“0”参与计算
二、COUNT(),两种用法
1、COUNT(*) -- 统计行数
对表中行数进行计数,不管是否有NULL
空结果集,返回0
2、COUNT(字段名)
对特定列有数据的行进行计数
忽略NULL值
三、MAX()、MIN()
求最大、最小值 ,都忽略NULL
四、SUM() -- 求和
可以对单个列求和,也可以对多个列运算后求和
忽略NULL值,且当对多个列运算求和时,如果运算的列中任意一列的值为NULL,则忽略这行的记录。
空结果集,返回null
例如: SUM(A+B+C),A、B、C 为三列,如果某行记录中A列值为NULL,则不统计这行。
五、GROUP BY的使用注意事项
1、分组列中若有NULL,这也将作为一组,且NULL值排在最前面
2、除汇总函数计算语句外,SELECT中的选择列必须出现在GROUP BY 中
3、GROUP BY 可以包含任意数目的列,可以嵌套
补充一:Mysql中的sum函数为null时的解决办法
方法1:使用IFNULL(expression_1,expression_2)函数:表示如果expression_1不为NULL,则IFNULL函数返回expression_1; 否则返回expression_2的结果。 如IFNULL(sum(id),0)
方法2:使用COALESCE(value,...) 函数:coalesce()解释:返回参数中的第一个非空(null)表达式(从左向右依次类推);select coalesce(null,null,3); -- Return 3
方法3:使用 case when 函数进行判断
补充二:MySQL的空值和NULL区别
null /nʌl/ adj. 无效的,无价值的;等于零的 n. 零,[数] 空
NULL在MySQL中是一个非常特殊的值,官方表述为“一个未知的值”,它与其它数据类型的值均不相同。
NULL也就是在字段中存储NULL值,空值也就是字段中存储空字符('')。null就是一个特殊的值,'未知的';
从本质上区别: 1、空值不占空间 2、null值占空间
通俗的讲:空值就像是一个真空转态杯子,什么都没有,而null值就是一个装满空气的杯子,虽然看起来都是一样的,但是有着本质的区别。
x
select length(NULL), length(''), length('1');
Oracle 与 Mysql NULL值,空字符串''的区别
Oracle(null等同于空字符'')
1.oracle插入空字符串默认替换成null
2.oracle查询(null和被替换的空字符)时使用 is null/is not null
3.使用聚合函数时自动忽略null值
Mysql(null不等同于空字符'')
1.mysql插入null显示为null,插入空字符串显示空
2.null查询用 is null/is not null,空字符''查询用 =''/<>''
3.使用聚合函数时自动忽略null值,(count()除外)
x
原文链接:https://blog.csdn.net/ljl890705/article/details/97263432
1)NULL只支持IS NULL、IS NOT NULL、IFNULL()操作;
2)NULL对数学比较运算符(>, =, <=, <>)运算出的结果都是FALSE;
3)索引列是允许存在NULL的;
4)DISTINCT、GROUP BY、ORDER BY中认为所有的NULL值都是相等的;
5)ORDER BY认为NULL是最小的值;
6)MIN()、SUM()、COUNT()在运算时会忽略NULL值,但是COUNT(*)不会忽略;
7)TIMESTAMP类型的字段被插入NULL时,实际写入到表中的是当前时间;
8)AUTO_INCREMENT属性的字段被插入NULL时,实际写入到表中的是顺序的下一个自增值;
9)想要禁止某个字段被设置为NULL,则对此字段设置NOT NULL属性;
10)如非必要,不要使用NULL,会带来不可预料的麻烦。
对于已经创建好的表,如果计划在列上创建索引,那么尽量修改为not null,并且使用0 或者一个特殊值或者空值''。
总之,对于表通常情况也全都指定为not null,并指定 default ''或者其它默认值,优势大于劣势。
小结及课堂纪要
子查询
导入:罗马不是一天建成的,数据统计也不是一步就到位的。那么在SQL中怎么分步来查询?怎么拿到并运用上一步的结果呢?
子查询概念
子查询(sub query):指在一条select语句中,嵌入了另外一条select语句,那么被嵌入的select语句称之为子查询语句。
子查询是一种常用计算机语言SELECT-SQL语言中嵌套查询下层的程序模块。当一个查询是另一个查询的条件时,称之为子查询。
主查询概念
主查询:主要的查询对象,第一条select语句,确定的用户所有获取的数据目标(数据源),以及要具体得到的字段信息。 子查询和主查询的关系
xxxxxxxxxx
1、 子查询是嵌入到主查询中的;
2、 子查询的辅助主查询的:要么作为条件,要么作为数据源
3、 子查询其实可以独立存在:是一条完整的select语句
优点
xxxxxxxxxx
1,允许结构化的查询,以便可以隔离语句的每个部分;
2,可以替代复杂的连接和联合;
3,有更高的可读性。实际上,正是子查询这个创新给了人们灵感,把SQL叫做结构化查询语言。
子查询分类
按功能分
xxxxxxxxxx
标量子查询:子查询返回的结果是一个数据(一行一列,即一个值)
列子查询:返回的结果是一列(一列多行)
行子查询:返回的结果是一行(一行多列)
表子查询:返回的结果是多行多列(多行多列)
Exists子查询:返回的结果1或者0(类似布尔操作,通常做where条件)
按应用场景分(更重要):
xxxxxxxxxx
单表操作: 主查询,子查询都来自一张表(解题思路:先数据,再语句)
多表操作: 主查询,子查询来自不同表(解题思路:先主查询,再子查询)
标量子查询
标量子查询是指子查询返回的是单一值的标量,如一个数字或一个字符串,也是子查询中最简单的返回形式。
使用子查询进行比较:
可以使用 = > < >= <= <> 这些操作符对子查询的标量结果进行比较,通常子查询的位置在比较式的右侧:
查出products_sales中销量与prod_sales最大销量相同的信息
xxxxxxxxxx
select * from products_sales a where a.p_sales=(select max(p.sales_num) from prod_sales p);
查出article表中与user表状态为1的id号最大的用户的信息
xxxxxxxxxx
SELECT * FROM article WHERE uid = (SELECT uid FROM user WHERE status=1 ORDER BY uid DESC LIMIT 1);
提示:对于采用这些操作符之一进行的比较,子查询必须返回一个标量。唯一的例外是 = 可以和行子查询同时使用。
子查询与表连接:
子查询与表连接很类似,可思考2种的互换写法,有助于理解.
在很多情况下,子查询的效果与 JOIN 表连接很类似,但一些特殊情况下,是必须用子查询而不能用表连接的,如:
找出发表了 2 篇文章的用户的所有文章记录
xxxxxxxxxx
select * from article a where a.uid=(select a.uid from article a group by a.uid HAVING count(*)=2);
SELECT * FROM article AS t WHERE 2 = (SELECT COUNT(*) FROM article t1 WHERE t1.uid = t.uid);
将标量子查询返回,作为标量操作数。
标量子查询是一个简单的操作数,您几乎可以在将它使用在任何单个列值或字面值合法的地方。你可以期望它具有一般操作数都拥有的特征:数据类型,长度,可以为NULL的指示,等等。
很少有一个标量子查询不能被使用的情况。如果一个语句只允许一个字面量值,那此时你无法使用一个子查询。例如,LIMIT要求整数类型的字面值参数,但limit 可以用变量(在存储过程中或预处理语句中)。
xxxxxxxxxx
-- limit 不可直接用标量子查询,以下为错误写法
select * from products_sales limit 1;
select * from products_sales limit (select a.uid from article a group by a.uid HAVING count(*)=2);
set @num=1;
select @num;
select * from products_sales limit @num;
select * from products_sales limit (@num);
select * from products_sales limit @num:=1;
补充1:在存储过程中或预处理语句中,limit 可以用变量。
xxxxxxxxxx
-- procedure 存储过程
DELIMITER $$
drop PROCEDURE if EXISTS PROC_NAME ;
CREATE PROCEDURE PROC_NAME(
IN a INT,
IN b INT
)
BEGIN
SELECT*FROM `user` LIMIT a,b ;
END$$
CALL PROC_NAME(1,2);
补充2 :prepare 预处理语句 MySQL5.0 开始支持
参考:https://blog.csdn.net/u014532775/article/details/90634292 mysql prepare语句使用
xxxxxxxxxx
-- prepare 预处理语句 mysql5.0 开始支持
PREPARE statement_name FROM sql_text /*定义*/
EXECUTE statement_name [USING variable [,variable...]] /*执行预处理语句*/
DEALLOCATE PREPARE statement_name /*删除定义*/
xxxxxxxxxx
-- prepare
PREPARE s1 FROM 'SELECT * FROM user LIMIT ?,?';
set @_limit=1;
set @_limit1=(select count(1) from user);
EXECUTE s1 USING @_limit,@_limit1;
PREPARE stmt1 FROM 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse';
SET @a = 3;
SET @b = 4;
EXECUTE stmt1 USING @a, @b;
xxxxxxxxxx
-- procedure and prepare
delimiter //
drop PROCEDURE if EXISTS myTest ;
create procedure myTest()
begin
set @_sql = 'select ? + ? as a_and_b';
set @a = 5;
set @b = 6;
PREPARE stmt from @_sql; -- 预定义sql
EXECUTE stmt USING @a,@b;-- 传入两个会话变量来填充sql中的 ?
DEALLOCATE PREPARE stmt; -- 释放连接
end //
call myTest;
补充3:标量子查询可以是表达式的一部分,但记得加括号,即使子查询只是作为操作数为函数提供参数。
xxxxxxxxxx
select lower((select u.username from user_login u where u.id=753014));-- 作为参数,要加括号
小结及课堂纪要
列子查询
由于列子查询返回的结果集是 N 行一列,该结果通常来自对表的某个字段查询返回。因此不能直接使用 = > < >= <= <> 这些比较标量结果的操作符。在列子查询中可以使用 IN、ANY、SOME 和 ALL 操作符:
xxxxxxxxxx
IN:在指定项内,同 IN(项1,项2,…)。
ANY:与比较操作符联合使用,表示与子查询返回的任何值比较为 TRUE ,则返回 TRUE 。
SOME:ANY 的别名,较少使用。
ALL:与比较操作符联合使用,表示与子查询返回的所有值比较都为 TRUE ,则返回 TRUE 。
IN操作符
单列子查询
xxxxxxxxxx
select * from prod_sales p where p.prod_id in (select p.p_name from products p );
select p.* from prod_sales p,products ps where p.prod_id=ps.p_name;
多列子查询 (解释见 行子查询)
xxxxxxxxxx
select * from prod_sales p where (p.prod_class,p.prod_id) in (select p.p_type,p.p_name from products p );
select p.* from prod_sales p,products ps where p.prod_id=ps.p_name and p.prod_class=ps.p_type;
单列子查询就是子查询中只有1个列;多列子查询就是子查询中不止1个列名。
小结及课堂纪要
ANY/SOME 操作符
xxxxxxxxxx
select t1.s1 from t1 where t1.s1 > any(select t2.s2 from t2);
select t1.s1 from t1 where t1.s1 > (select min(t2.s2) from t2);
条件 t1.s1 > any(select t2.s2 from t2) 返回true 即可。也就是大于最小值。
IN 是 = some/any 的别名,二者相同。
特殊情况:
xxxxxxxxxx
如果 子查询 为空表,则 ANY 后的结果为 FALSE;
如果子查询返回如 (NULL,NULL,NULL) 列为空的结果,则 ANY 后的结果为 UNKNOWN 。跟null比较返回false.
如果子查询返回的结果有null,则忽略这个null。等同max 与 min。
特殊情况举例:
xxxxxxxxxx
select t2.s2 from t2 where t2.`name`='s';
select t1.s1 from t1 where t1.s1 > any(select t2.s2 from t2 where t2.`name`='s');-- 空集为False
select t1.s1 from t1 where t1.s1 < any(select t2.s2 from t2 where t2.`name`='s');
select t1.s1 from t1 where 1=0;
SELECT s1 FROM t1 where t1.s1 is null;
SELECT s2 FROM t2 WHERE s2 > any ( SELECT s1 FROM t1 where t1.s1 is null );-- 全null为False
SELECT s2 FROM t2 WHERE s2 < any ( SELECT s1 FROM t1 where t1.s1 is null );-- 全null为False
SELECT s1 FROM t1;
SELECT s2 FROM t2 WHERE s2 > any (SELECT s1 FROM t1);-- 忽略null
SELECT s2 FROM t2 WHERE s2 > (SELECT min(s1) FROM t1);
SELECT s2 FROM t2 WHERE s2 < any (SELECT s1 FROM t1);-- 忽略null
SELECT s2 FROM t2 WHERE s2 < (SELECT max(s1) FROM t1);
xxxxxxxxxx
【注意】any操作符后接多行子查询返回列表中的每一个值。
<any为小于最大的
>any为大于最小的
=any 为 in
小结及课堂纪要
ALL 操作符
ALL 关键字必须接在一个比较操作符的后面,表示与子查询返回的所有值(包括null)比较为 TRUE ,则返回 TRUE 。一个 ALL 例子如下:
xxxxxxxxxx
SELECT s1 FROM t1 WHERE s1 < ALL (SELECT s2 FROM t2);
SELECT s1 FROM t1 WHERE s1 < (SELECT min(s2) FROM t2);
where条件 s1 < ALL (SELECT s2 FROM t2)成立,即s1 <min(s2). NOT IN 是 <> ALL 的别名,二者相同。
特殊情况
xxxxxxxxxx
如果 子查询 为空表,则 ALL 后的结果为 TRUE。即子查询返回空表,则all语句结果为True;
如果子查询返回如 (0,NULL,1) 这种尽管 s1 比返回结果都大,但有空行的结果,则 ALL 后的结果为 UNKNOWN 。
即子查询结果集有null,all语句为False;
特殊情况举例:
xxxxxxxxxx
-- 子查询返回空表,则all语句结果为True;
SELECT s2 FROM t2 WHERE s2 > ALL (SELECT s1 FROM t1 where t1.id>5);
SELECT s2 FROM t2 WHERE s2 < ALL (SELECT s1 FROM t1 where t1.id>5);
SELECT s2 FROM t2 WHERE 1=1;
-- 子查询结果集有null,all语句为False;
SELECT s1 FROM t1;
SELECT s2 FROM t2 WHERE s2 > ALL (SELECT s1 FROM t1);
SELECT s2 FROM t2 WHERE s2 < ALL (SELECT s1 FROM t1);
SELECT s2 FROM t2 WHERE 1=2;
总结:
xxxxxxxxxx
【注意】all操作符比较子查询返回列表中的每一个值。
<all为小于最小的
>all为大于最大的
<>all 为 not in
=all无意义,一般不写。
空集为True,有null为False
小结及课堂纪要
列子查询与limit
xxxxxxxxxx
-- 分别在mysql5.7和最新的mysql8.0执行以下语句
select * from product p1 where p1.product_id in (
select p.product_id from itcast.shopproduct p order by p.quantity limit 5
);
select t1.s1 from t1 where t1.s1 > any(select t2.s2 from t2 limit 5);
都报错:This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
这与版本无关,解决办法再套一层select。
xxxxxxxxxx
select * from product p1 where p1.product_id in (
select t.product_id from (select p.product_id from itcast.shopproduct p order by p.quantity limit 5)t
);
select t1.s1 from t1 where t1.s1 > any(select t.s2 from (select t2.s2 from t2 limit 5) t);
小结及课堂纪要
行子查询
行子查询是指子查询返回的结果集是一行 N 列,该子查询的结果通常是对表的某行数据进行查询而返回的结果集。
xxxxxxxxxx
SELECT * FROM table1 WHERE (1,2) = (SELECT column1, column2 FROM table2 [limit 1 ])
-- 在该例子中,在保证子查询返回单一行数据的前提下,如果 column1=1 且 column2=2 ,则该查询结果为 TRUE。
xxxxxxxxxx
select * from prod_sales p where (p.prod_class,p.prod_id)=(select p.p_type,p.p_name from products p where p.p_view>100 );
select * from prod_sales p where (p.prod_class=(select p.p_type from products p where p.p_view>100 )) and (p.prod_id=(select p.p_name from products p where p.p_view>100 ));
MySQL 行构造符 在上面的例子中,WHERE 后面的 (p.prod_class,p.prod_id) 被称为行构造符,也可以写作 ROW(p.prod_class,p.prod_id)。行构造符通常用于与对能返回两个或两个以上列的子查询进行比较。逐一与子查询返回的行记录作比较,如果相等则列出这些相等的记录(最终结果集理论上可能不止一条)。
运用:对有确定值的多条件查询,常构造行子查询。用MySQL 行构造符把查询字段包裹起来,用子查询返回对应的确定值。
xxxxxxxxxx
-- eg: 查询班级年龄最大且身高最高的学生
select * from students where (height,age) = (select max(height), max(age) from students);
-- t1.column1=t2.value2 and t1.column2=t3.value3
select * from table1 t1 where (t1.column1,t1.column2)=(select t2.value2,t3.value3 from table2 t2,table3 t3);-- 可以多个表构造 相互之间可以没有关系
小结及课堂纪要
表子查询
表子查询: 也叫from子查询,得到的结果作为from数据源。从子查询返回的结果集将用作临时表。 该表称为派生表(derived table)或物化子查询。把内层的查询结果当成临时表,供外层sql再次查询。查询结果集可以当成表看待。临时表要使用一个别名。
xxxxxxxxxx
select * from ( select p.p_type,count(*) nums from products p GROUP BY p.p_type) a where nums>3;-- a 别名不丢。否则报错派生表该有别名。
小结及课堂纪要
Exists子查询
当子查询与EXISTS或NOT EXISTS运算符一起使用时,子查询返回一个布尔值为TRUE或FALSE的值。把外层sql的结果,拿到内层sql去测试,如果内层的sql成立,则该行取出。内层查询是exists后的查询。
首先头脑中有三点概念:
xxxxxxxxxx
1、EXISTS 子查询找到的提交
NOT EXISTS 子查询中 找不到的提交
说明:不要去翻译为存在和不存在,把脑袋搞晕。
2、建立程序循环的概念,这是一个动态的查询过程。如 FOR循环 。
3、Exists执行的流程 Exists首先执行外层查询,再执行内层查询,与IN相反。
流程为首先取出外层中的第 一 元组, 再执行内层查询,将外层表的第一元组代入,若内层查询为真,即有结果
时。返回外层表中的第一元组,接着取出第二元组,执行相同的算法。一直到扫描完外层整表 。
查出products中与prod_sales共有的类别的信息
xxxxxxxxxx
-- exists
select * from products p1 where exists (select * from prod_sales p2 where p2.prod_class=p1.p_type);
-- select DISTINCT p1.p_type from products p1;
-- select DISTINCT p2.prod_class from prod_sales p2;
select * from products p1 where p1.p_type in (select DISTINCT p1.p_type from products p1,prod_sales p2 where p2.prod_class=p1.p_type);
select * from products p1 where exists (select p2.id from prod_sales p2 where p2.prod_class=p1.p_type);
注:将子查询中的"*"改为任意内容,返回结果一致,这是因为EXISTS关键字值关心子查询中返回数据的真假而不是具体的内容
NOT EXISTS和EXIST的返回结果相反。
推荐文章:EXISTS用法详解:https://blog.csdn.net/weixin_45280346/article/details/95311720
SQL语句扫盲:https://blog.csdn.net/wolfofsiberian/article/details/39346781#
找出比平均价格高的物品
xxxxxxxxxx
select Price from house_price where Price>AVG(Price);
以上为错误写法,avg不能写在where语句后
此时,我们可以用子查询,进行多次select
xxxxxxxxxx
select Price from house_price where Price>(select AVG(Price) from house_price);
这种写法就可以了,这种子查询叫做标量子查询
子查询先执行括号内的运算,再执行外部运算
找出一些房屋信息和房屋的均价
错误写法:
xxxxxxxxxx
select Price,AVG(Price) from house_price;-- mysql5.7前可以直接写
mysql8.0 报错 sql_mode=only_full_group_by,要修改sql_mode;不建议修改
正确写法:
xxxxxxxxxx
select Price,(select AVG(Price) from house_price) as avg_price from house_price;
以下写法也是支持的(知道均值)
xxxxxxxxxx
select Price,130427 as avg_price from house_price;
以Neighborhood和Bedrooms分组,统计分组后均价大于整体价格均价的Neighborhood、Bedrooms和分组后的均价数据
xxxxxxxxxx
select Neighborhood,Bedrooms,AVG(Price) from
house_price group by Neighborhood,Bedrooms
having AVG(Price)>(select AVG(Price) from house_price);
找出所有房屋中Bedrooms数量相同的价格大于以Neighborhood为分组的房屋均价的房屋
错误写法1:
xxxxxxxxxx
select Neighborhood,Bedrooms from house_price where Price>(select AVG(Price) from house_price group by Neighborhood);
错误原因:由于不是标量子查询,则子查询返回了多条数据,无法与Price进行一一比对
错误写法2:
xxxxxxxxxx
select Neighborhood,Bedrooms from house_price as a where a.Bedrooms=b.Bedrooms and Price>(select AVG(Price) from house_price as b group by Neighborhood);
错误原因:首先,子查询先执行。子查询执行完后,别名b就消失了,而子查询执行时,别名a已经声明,且没有消失
xxxxxxxxxx
select Neighborhood,Bedrooms from house_price as a where Price>(select AVG(Price) from house_price as b where a.Bedrooms=b.Bedrooms group by Neighborhood limit 1);
正确写法:
xxxxxxxxxx
select Neighborhood,Bedrooms from house_price as a where Price>(select AVG(Price) from house_price as b where a.Bedrooms=b.Bedrooms group by Neighborhood limit 1);
xxxxxxxxxx
select *,h.Home as `index`,avg(h.Price),(select avg(h.Price) from house_price h ) from house_price h group by h.Neighborhood,h.Bedrooms HAVING avg(h.Price)>(select avg(h.Price) from house_price h );-- 别名之间不冲突,但是要注意条理.
小结及课堂纪要
关于优化
1, 尽量避免in 和not in。in适合用于子表小且简单的情况,in 复杂时,会放弃索引,权标扫描。可用 EXISTS(NOT EXISTS)或 join代替
2, not in,一是可能会出现不期望的结果集,存在逻辑错误;二是放弃索引,对内外表都进行全表扫描。用not exist替代()。
3,any some all 一般也用的比较少。
多表联结查询
导入:为了数据的高效存储,真正做到关系型数据库,常常会把数据分开存储。如此我们需要的数据可能就不在一张表里,此时我们怎么进行关联呢?
在一般的业务情况下,我们大致将 Mysql多表连接 分为如下几种:
xxxxxxxxxx
内连接:INNER JOIN ON– 可简写为 JOIN ON;取两张表的交集
左外连接:LEFT OUTER JOIN...ON – 可简写为 LEFT JOIN...ON。
查询出左边表的完全集,如果右边表有相同的值就一起显示,没有就用null代替
右外连接:RIGHT OUTER JOIN...ON – 可简写为 RIGHT JOIN...ON;
全连接:使用 UNION [ALL]完成。左连接和右连接的并集。也叫组合查询
交叉连接:CROSS JOIN – 也称为 笛卡儿乘积连接,大抵不使用;
导入product.csv和shopproduct.csv
内连接
合并两张表,在两张表中分别获取部分数据
xxxxxxxxxx
select shop_id,shop_name,sp.product_id,quantity,product_name,product_type,sale_price
from product as p inner join shopproduct as sp
on p.product_id=sp.product_id
注:上述操作可以执行,但是可能一不留神就会出现像product_id这样的字段无法界定的问题。比较稳妥的写法如下(起别名):
xxxxxxxxxx
select sp.shop_id,sp.shop_name,sp.product_id,sp.quantity,p.product_name,p.product_type,p.sale_price
from product as p
inner join
shopproduct as sp
on p.product_id=sp.product_id
左外连接
xxxxxxxxxx
select sp.shop_id,sp.shop_name,sp.product_id,sp.quantity,p.product_name,p.product_type,p.sale_price
from product as p
left outer join
shopproduct as sp
on p.product_id=sp.product_id
保留左边的表中全部信息,右边表中的对应数据为空则不保留
右外连接
xxxxxxxxxx
select sp.shop_id,sp.shop_name,sp.product_id,sp.quantity,p.product_name,p.product_type,p.sale_price
from product as p
right outer join
shopproduct as sp
on p.product_id=sp.product_id
保留右边的表中全部信息,左边边表中的对应数据为空则不保留
交叉连接
xxxxxxxxxx
select sp.shop_id,sp.shop_name,sp.product_id,sp.quantity,p.product_name,p.product_type,p.sale_price
from product as p
cross join
shopproduct as sp
on p.product_id=sp.product_id
将左表和右表中的数据进行一一组合(笛卡尔积)
一种过时的写法(不推荐,偶尔可用)
xxxxxxxxxx
select sp.shop_id,sp.shop_name,sp.product_id,sp.quantity,p.product_name,p.product_type,p.sale_price
from product p,shopproduct sp
where p.product_id=sp.product_id and sp.shop_id="000A";
此时,无法直接看出是内连接还是外连接,条件中无法看出是连接条件还是其他判断条件。表关联还是用join。
小结及课堂纪要
组合查询
导入:当一个查询不足以输出我们想要的全部结果集时,这时我们就需要拼接。那么SQL是如何将多张表表纵向联接的呢?
组合查询的意义:
1,将不同的表进行查询拼接在一起,返回
2,将一个表进行多次查询,返回一个查询的结果
首先我们学习一个表的多次查询的情况:
xxxxxxxxxx
select product_id,product_name,product_type from product where product_id<5
union
select product_id,product_name,product_type from product where product_type="厨房用具";
其实上述也可以简写为:
xxxxxxxxxx
select product_id,product_name,product_type from product where product_type="厨房用具" or product_id<5;
使用UNION_ALL的效果:
xxxxxxxxxx
select product_id,product_name,product_type from product where product_id<5
union all
select product_id,product_name,product_type from product where product_type="厨房用具";
上述使用union和使用union all效果不一致,union all不会将和并后的数据去重
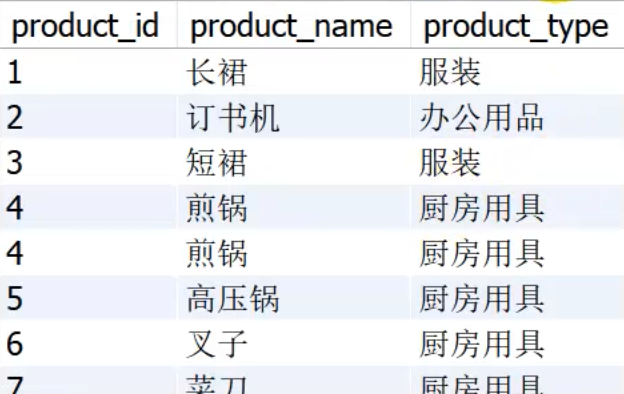
注:union或union all前后查询出的字段数量必须一致
以下写法是错误的
xxxxxxxxxx
select product_id,product_name from product where product_id<5
union all
select product_id,product_name,product_type from product where product_type="厨房用具";
最后,order by关键字只能在最后使用,而不能再union或union all之前使用
xxxxxxxxxx
select product_id,product_name,product_type from product where product_id<5
union all
select product_id,product_name,product_type from product where product_type="厨房用具"
order by product_id;
小结及课堂纪要
CASE表达式
导入:现实中也有很多假如,在不同条件下输出不同的值。 JavaScript或编程语言里的 if-esle if-else 或者 switch语句,在sql语言中是怎么来实现的呢?
定义:sql中,CASE表达式是一个标量表达式,它基于条件逻辑返回一个值。
case* /keɪs/ n. 情况; 实例; 箱; vt. 包围; 把…装于容器中;
理解:1,CASE表达式是一个表达式,而不是一条语句;它用于计算条件列表的表达式,并返回可能的结果之一。
2,由于case表达式返回一个值,类似于函数,也习惯上称case函数,严格的意义上来讲case函数已经是流程控制语句了,不是简单意义上的函数,不过为了方便,很多人将case函数称为流程控制函数。
case的两种形式
简单case表达式
xxxxxxxxxx
case <表达式>
when <表达式1> then <表达式4>
when <表达式2> then <表达式5>
when <表达式3> then <表达式6>
。。。
else <表达式>
end
特点:枚举这个字段所有可能的值。
搜索case表达式
xxxxxxxxxx
case
when <求值表达式1> then <表达式4>
when <求值表达式2> then <表达式5>
when <求值表达式3> then <表达式6>
。。。
else <表达式>
end
特点:搜索函数可以写判断,并且搜索函数只会返回第一个符合条件的值,其他case被忽略
这两种方式,可以实现相同的功能。简单Case函数的写法相对比较简洁,但是和Case搜索函数相比,功能方面会有些限制,比如写判断式。 注意:1,Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
2,else 分支可以省略,但是不能没有默认值。可默认为null,实际中一般默认为0;
3,then 可以为一个值,该分支返回该值;为一个条件时,表示执行该条件;
4,when后为值,表示 =“该值”,为条件是,表示满足该条件,
5,千万不要忽略end.习惯写完case when then else end然后填值。
xxxxxxxxxx
-- 2 比如说,下面这段SQL,你永远无法得到“第二类”这个结果
CASE WHEN col_1 IN ( 'a', 'b') THEN '第一类'
WHEN col_1 IN ('a') THEN '第二类'
ELSE'其他' END
xxxxxxxxxx
-- 4
case col_1
when 1 then 'RIGHT'
when null then 'wrong'
end
-- 分支when null 表示when col_1=null,此分支总是返回nuknow (N/A),也即永远不会出现wrong的情况。因为这一个错误的用法,此时我们应该用 when col_1 is null 条件表达式。
xxxxxxxxxx
select* from t1,t2 where (t2.name =
case t1.s1 when 2 then 'aaa'
when 3 then 'bbb'
when null then 'ccc'
end) and t2.s2 < 50;
select* from t1,t2 where (t2.name =
case when t1.s1=2 then 'aaa'
when t1.s1=3 then 'bbb'
when t1.s1 is null then 'ccc'
end) and t2.s2 < 50;
小结及课堂纪要
多条件判断(赋值或其他处理)
也叫动态赋值
使用house_price表,判断卧室2个位small,3个为 middle,4个为large,否则 largest;
简单case表达式写法
xxxxxxxxxx
select h.Bedrooms,
case Bedrooms
when 2 then 'small'
when 3 then 'middle'
when 4 then 'large'
else 'largest'
end as BedroomsDesc
from house_price h;
搜索case表达式写法
xxxxxxxxxx
select
case
when Bedrooms=2 then 'small'
when Bedrooms=3 then 'middle'
when Bedrooms=4 then 'large'
else 'largest'
end as BedroomsDesc
from house_price
案例:
准备数据
xxxxxxxxxx
CREATE TABLE c1 (
id INT,
sex VARCHAR (10),
score INT
);
/*插入数据*/
INSERT INTO c1
VALUES
(1001, '男' ,65),
(1002, '男' ,75),
(1003, '女' ,82),
(1004, '女' ,70),
(1005, '男' ,89),
(1006, '女' ,90),
(1007, '男' ,85);
SELECT * FROM c1;
需求:1,将性别男、女分别用0、1替换
2,将成绩分为小于60 差,60~80 中,80~90良,90以上优
3,将成绩等级分为四列
xxxxxxxxxx
/*将性别男、女分别用0、1替换*/
SELECT
id,
CASE
WHEN sex = '男' THEN 0
WHEN sex = '女' THEN 1 END sex ,
score
FROM c1;
/*将成绩分为小于60 差,60~80 中,80~90良,90以上优*/
SELECT * ,
CASE
WHEN score<60 THEN '差'
WHEN score>=60 AND score<80 THEN '中'
WHEN score>=80 AND score<90 THEN '良'
WHEN score>=90 THEN '优' END level
FROM c1;
SELECT * ,
CASE
WHEN score<60 THEN '差'
WHEN score<80 THEN '中'
WHEN score<90 THEN '良'
else '优'
END level
FROM c1;
/*将成绩等级分为四列*/
SELECT id, sex,score,
CASE WHEN score<60 THEN '差' END AS level1,
CASE WHEN score>=60 AND score<80 THEN '中' END AS level2,
CASE WHEN score>=80 AND score<90 THEN '良' END AS level3,
CASE WHEN score>=90 THEN '优'END AS level4
FROM c1;
此外还在更新语句中
xxxxxxxxxx
update table
set 字段1=case
when 条件1 then 值1
when 条件2 then 值2
else 值3
end
where ……
小结及课堂纪要
多条件统计
建表company_profile添加数据如下:
需求:
求出每个公司的男性的总数
xxxxxxxxxx
select company,sum(num)
from company_profile
where gender="M"
group by company;
求出每个公司的女性的总数
xxxxxxxxxx
select company,sum(num)
from company_profile
where gender="F"
group by company;
求出每个公司男性和女性的总数,需要将上述两个表进行合并
xxxxxxxxxx
select M.company,M.num_M,F.num_F from
(select company,sum(num) as num_M
from company_profile
where gender="M"
group by company) as M
inner join
(select company,sum(num) as num_F
from company_profile
where gender="F"
group by company) as F
on M.company=F.company
结果如下:
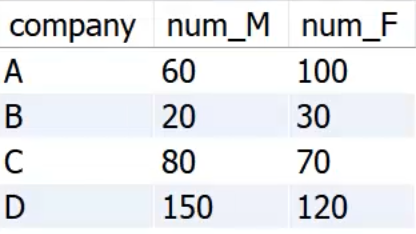
缺点:增加消耗(3条select),且sql语句较长,显得臃肿。
使用case表达式
xxxxxxxxxx
select c.company,
sum(CASE when c.gender='M' then c.number else 0 end ) num_M,
sum(CASE when c.gender='F' then c.number else 0 end ) num_F
from company_profile c
group by c.company;
4,c1表按照性别计算各成绩等级中的数量
xxxxxxxxxx
/*按照性别计算各成绩等级中的数量*/
SELECT sex,
SUM(CASE WHEN score<60 THEN 1 ELSE 0 END) AS '差',
SUM(CASE WHEN score>=60 AND score<80 THEN 1 ELSE 0 END) AS '中',
SUM(CASE WHEN score>=80 AND score<90 THEN 1 ELSE 0 END) AS '良',
SUM(CASE WHEN score>=90 THEN 1 ELSE 0 END) AS '优'
FROM c1
GROUP BY sex;
SELECT sex,
COUNT(CASE WHEN score<60 THEN 1 ELSE NULL END) AS '差',
COUNT(CASE WHEN score>=60 AND score<80 THEN 1 ELSE NULL END) AS '中',
COUNT(CASE WHEN score>=80 AND score<90 THEN 1 ELSE NULL END) AS '良',
COUNT(CASE WHEN score>=90 THEN 1 ELSE NULL END) AS '优'
FROM c1
GROUP BY sex;
SELECT sex,
COUNT(CASE WHEN score<60 THEN 1 ELSE NULL END) AS '差',
COUNT(CASE WHEN score<80 THEN 1 ELSE NULL END) AS '中',
COUNT(CASE WHEN score<90 THEN 1 ELSE NULL END) AS '良',
COUNT(CASE WHEN score>=90 THEN 1 ELSE NULL END) AS '优'
FROM c1
GROUP BY sex;-- 不同的case 相互之间是独立的
小结及课堂纪要
多条件分组处理
也叫动态分组,或自定义分组。
统计country中各洲人数
有洲(continent)列,简单分组统计
xxxxxxxxxx
select c.continent,sum(c.population) from country c group by c.continent;
实际业务中很可能没有这一列,你又不能修改原来表结构加一列,想一下,你要怎么统计?
方法一:生成一个带有洲的视图(view),
xxxxxxxxxx
-- 生成view
create view continent_code as select c.country,case c.country
when '中国' then '亚洲'
when '印度' then '亚洲'
when '日本' then '亚洲'
when '美国' then '北美洲'
when '加拿大' then '北美洲'
when '墨西哥' then '北美洲'
else '其他' end as contient
from country c;
-- 取数
select cc.contient,sum(c.population) from country c join continent_code cc on c.country=cc.country group by cc.contient;
缺点:除了麻烦,还很难动态的改变统计的方式。
方法二:用case多条件分组处理
xxxxxxxxxx
select case c.country
when '中国' then '亚洲'
when '印度' then '亚洲'
when '日本' then '亚洲'
when '美国' then '北美洲'
when '加拿大' then '北美洲'
when '墨西哥' then '北美洲'
else '其他' end as '洲',
sum(c.population) as '人口'
from country c
group by case c.country
when '中国' then '亚洲'
when '印度' then '亚洲'
when '日本' then '亚洲'
when '美国' then '北美洲'
when '加拿大' then '北美洲'
when '墨西哥' then '北美洲'
else '其他' end ;
假如薪资等级为100万以上为第一等,80万以上为第二等,60万以上为第三等,45万以上为第四等,30万以上为为第五等,其余为第六等。要求统计出个薪资等级的英雄数,并具体显示。
xxxxxxxxxx
select case when h.salary>=1000000 then '1'
when h.salary>=800000 and h.salary<1000000 then '2'
when h.salary>=600000 and h.salary<800000 then '3'
when h.salary>=450000 and h.salary<600000 then '4'
when h.salary>=300000 and h.salary<450000 then '5'
else '6' end salary_class,
count(*),
GROUP_CONCAT(h.`name`)
from hero h
group by case when h.salary>=1000000 then '1'
when h.salary>=800000 and h.salary<1000000 then '2'
when h.salary>=600000 and h.salary<800000 then '3'
when h.salary>=450000 and h.salary<600000 then '4'
when h.salary>=300000 and h.salary<450000 then '5'
else '6' end ;
xxxxxxxxxx
select case when h.salary>=1000000 then '1'
when h.salary>=800000 then '2'
when h.salary>=600000 then '3'
when h.salary>=450000 then '4'
when h.salary>=300000 then '5'
else '6' end salary_class,
count(*),
GROUP_CONCAT(h.`name`)
from hero h
group by case when h.salary>=1000000 then '1'
when h.salary>=800000 then '2'
when h.salary>=600000 then '3'
when h.salary>=450000 then '4'
when h.salary>=300000 then '5'
else '6' end ;
简化写法,有人可以解释吗?
Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。第一个条件不满足时,数据就是小于1000000的,以此类推。从上到下,直到匹配到合适的条件。但是这样写必须按一定的顺序,而前者不需要。
小结及课堂纪要
sum 配合 case when 的简单函数实现行转列
把edu_student、edu_score、edu_courses数据排列成方式结构。
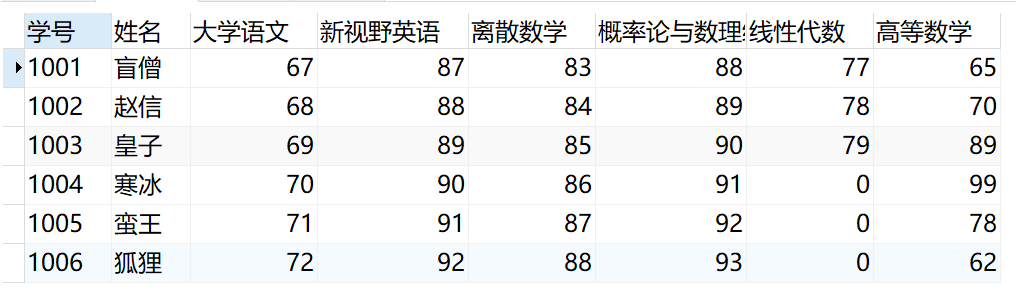
xxxxxxxxxx
-- 聚合函数 sum 配合 case when 的简单函数实现行转列
SELECT
st.stu_id '学号',
st.stu_name '姓名',
sum(CASE co.course_name WHEN '大学语文' THEN sc.scores END) '大学语文',
sum(CASE co.course_name WHEN '新视野英语' THEN sc.scores END) '新视野英语',
sum(CASE co.course_name WHEN '离散数学' THEN sc.scores END) '离散数学',
sum(CASE co.course_name WHEN '概率论与数理统计' THEN sc.scores END ) '概率论与数理统计',
sum(CASE co.course_name WHEN '线性代数' THEN sc.scores ELSE 0 END) '线性代数',
sum(CASE co.course_name WHEN '高等数学' THEN sc.scores ELSE 0 END) '高等数学'
FROM edu_student st
LEFT JOIN edu_score sc ON st.stu_id = sc.stu_id
LEFT JOIN edu_courses co ON co.course_no = sc.course_no
GROUP BY st.stu_id
ORDER BY NULL;
小结及课堂纪要
自定义排序
把t1的数据按index值得甲乙丙丁排序;
xxxxxxxxxx
select * from t1;
select * from t1 order by case `index` when '甲' then 1 when '乙' then 2
when '丙' then 3 when '丁' then 4 end ;-- 处理成1234 按升序排列
select * from t1 order by FIELD(t1.`index`,'甲','乙','丙','丁');
补充:order by field(value,str1,str2,str3,str4,,,,,,strn)
其中value后面的参数自定义,不限制参数个数
解释:将获取出来的数据根据str1,str2,str3,str4等的顺序排序
小结及课堂纪要
用在where中
准备数据
xxxxxxxxxx
-- 观察sql
select* from t1,t2 where t2.name in
case when t1.id=1 then ('a','aa','aaa')
when t1.id=2 then ('b','bb','bbb')
end;
要点:case表达式的注意事项3,then 可以为一个值,或一个条件;
xxxxxxxxxx
-- 正确写法1,t2.name in ('a','aa','aaa') 才是一个表达式,表达式的返回值为True或False
select* from t1,t2 where
case when t1.id=1 then t2.name in ('a','aa','aaa')
when t1.id=2 then t2.name in ('b','bb','bbb')
end;
xxxxxxxxxx
-- then为一个值,t2.name =case表达式返回值
select* from t1,t2 where t2.name =
case when t1.id=1 then 'aaa'
when t1.id=2 then 'bbb'
end;
xxxxxxxxxx
-- 最简洁写法
select* from t1,t2 where t2.name =
case t1.id when 1 then 'aaa'
when 2 then 'bbb'
end;
xxxxxxxxxx
select* from t1,t2 where (t2.name =
case t1.id when 1 then 'aaa'
when 2 then 'bbb'
end) and t2.s2 < 50;
当在where条件使用case时,注意语句顺序,where在前,case end要用小括号括起来,如果有其他条件,后面拼上其他条件就ok啦!
小结及课堂纪要
case嵌套
查看数据: select * from student;

从表中可以看出:有的学生同事选修了几门课程(100,200),有的学生只选择了一门(300,400,500),选修多门的学生,要选一门作为主修,主修flag为Y,只修一门的主修flag为N(按我们理解应该为Y,实际也许还有其他定义规则或其他表关联),现在按下面两个条件进行查询:
1,只修一门的人,返回所修课程id
2,选修多门的,返回主修课程id
简单做法是,两次查询在union :
xxxxxxxxxx
-- union
select s.stu_id,s.class_id,s.class_name as main_class from student s where s.main_class_flag='Y'
union
select s.stu_id,max(s.class_id)as class_id,max(s.class_name) main_class from student s group by s.stu_id having count(*)=1;
较好做法,灵活使用case嵌套,
xxxxxxxxxx
-- case函数嵌套,一条sql写出(一个select)
select s.stu_id,
case when count(*)=1 then max(s.class_id)
else max(case when s.main_class_flag='Y' then s.class_id else null end)
end as class_id
,s.class_name
from student s
group by s.stu_id;-- class_id与class_name不匹配?
总结:
1,case表达式很强大,也灵活多变,要深入理解case的执行逻辑,万变不离其宗。
2,多条件且简短的查询,优先使用case
/* 倒数第二行 前添加如下代码 */