查找转换(Lookup)组件用于实现两个数据源的连接,实现的方式是嵌套循环。查找转换通常在内存中缓存查找数据集,然后在输入管道中,把输入数据的每一行都和缓存中的查找数据集进行比较,并输出匹配成功和失败的数据行。
在数据流任务中,应用Lookup转换组件,需要配置:
- 输入数据:是上游数据流输出到查找转换的数据;
- 查找数据:用于查找的数据集,通常缓存到内存中;
- 两个输出:一个是输出匹配成功的数据,一个是输出匹配不成功的数据。上游数据流的一行数据跟整个查找集进行匹配,如果匹配成功,那么输出匹配成功的数据,否则,输出匹配不成功的数据;
- 比较逻辑:Lookup 转换组件采用的等值比较方式,当比较列相等时,匹配成功;当比较列和查找集中的任一数据行都不相等时,匹配失败;
- 比较列映射:从输入数据和查找数据中,设置用于比较的字段;
通常情况下,Lookup转换组件的设计图如下示例:
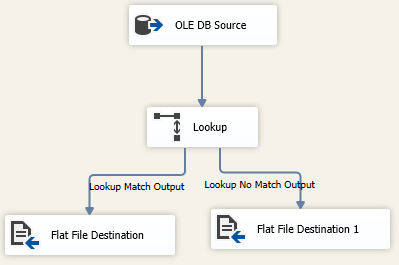
一,设置查找数据集
在查找转换中,输入数据集的每一行数据都和查找数据集的全集进行匹配,因此,查找数据集的读写速度影响查找转换的性能。Lookup转换组件支持三种缓存模式来读写查找数据集,
- Full Cache:把查找数据集全部缓存到内存中
- Partial Cache:把查找数据集的部分数据缓存到内存中,可以设置占用的缓存大小
- No Cache:不缓存查找数据集,几乎不占用任何内存
如果数据集较小,可以把查找数据集全部缓存到内存中,这种模式通常是最快的。如果查找数据集太过庞大以至于无法把所有数据缓存到内存中,可以选择No Cache模式或者部分缓存模式。对于不缓存模式,当每个输入行流经查找表时,查找组件向数据库服务器发送一条请求,以便执行匹配查找,这会给数据库系统带来沉重的性能开销,该模式是最差的模式,请慎重使用。
而部分缓存模式提供了介于全缓存和No Cache之间的这种方案,在该模式中,转换组件只缓存最近使用的数据集,一旦缓存增长过大,超出系统设置的缓存大小的阈值,那么最少使用的缓存数据就会被丢弃。当包启动时,与No Cache模式一样,转换组件不会把数据预先加载到缓存中。当每个输入行进入查找转换组件时,该组件使用指定键尝试从查找数据集中查找记录,如果查找到匹配行,那么把该行数据加载到本地缓存中。如果相同的输入键再次进行查找转换,那么就可以从本地缓存中获取匹配值,而不需要从查找数据集中,从而节省了因为访问书库而产生的时间。然而,如果在本地缓存中没有找到键,那么组件将访问数据库以检查查找数据集。请注意,键不在本地缓存中的原因有很多:可能是第一次查找该键,可能是以前在本地缓存中,但是由于内存压力而释放,或者是查找数据集中不存在该键。
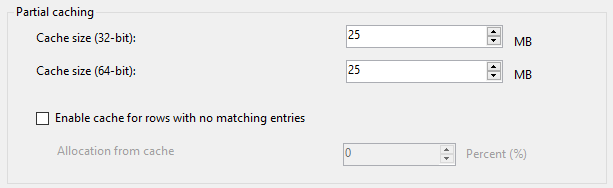
如果输入行不存在与本地缓存中,也不存在于查找数据集中,那么组件会把该行视为不匹配行,发送到不匹配行的输出。如果,输入数据集中不匹配的数据行出现的频率很高,那么,为了避免重复调用数据库,同时获得部分缓存模式带来的好处,可以使用查找转换的另外一个功能:缺失缓存,让组件记忆先前没有从查找表中找到的键值,从而避免重复查找该值所付出的代价,也就是,SSIS引擎分配部分内存,用于缓存匹配失败的键值,这样,一旦输入行和缺失缓存中的值匹配成功,那么就说明该行不会匹配查找数据集;但是,一旦输入行和缺失缓存中的键值都不匹配,那么就需要从本地缓存或者查找数据集中进行二次匹配,也会付出相应的代价。因此,应根据数据的分布,选择是否使用缺失缓存。
1,设置缓存模式
由于上游数据流的每一行都要和查找数据集的所有行进行匹配,因此,对查找数据集的访问是非常频繁的,为了提高性能,必须提高对查找数据集的访问速度。如果系统的内存资源允许,那么,首选Full Cache模式,把查找数据集驻留在内存中,最大可能地提高转换查找的执行性能。Full Cache是默认模式,在大多数情况下,该模式可以获得最佳性能。

2,设置链接管理器的类型
查找转换需要从外部数据源中导入查找数据集,链接管理器类型有两种:
- Cache Connection manager:缓存链接管理器,把数据缓存到内存
- OLE DB Connection mananger:从OLE DB 数据源中加载数据
3,缓存链接管理器
对于缓存链接管理器,需要用户手动输入数据列,并选择数据类型(Type),长度(Length),代码页(Code Page),索引位置(Index Position),其中,Index Position 用于标识当前的数据列是否是索引列。
当Index Position为1,标识当前列是索引列,用于比较;当Index Position为0,标识当前列不是索引列,虽然该列不能用于比较,但是可以替换输入列。
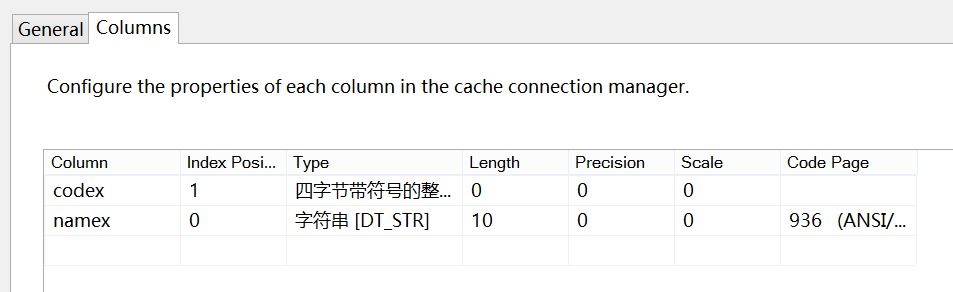
注意,Cache Connection manager仅仅是创建内存的架构(Schema),但是数据存储在哪里呢?这就需要使用 Cache Conversion把数据源中的数据导入到缓存中。

4,设置比较列映射
在查找转换的Columns选项卡中设置比较列映射,使用Code和Codex进行等值比较,即on子句的比较条件。
如果需要使用查找集来代替上游数据流输入,可以勾选Available Lookup Columns的非查找列(index 列没有放大镜的列),然后在Lookup operations中选择Replace。如果要将lookup columns增加到输出流中,在Lookup operations中选择add as new column。


5,配置查找转换的输出
查找转换的输出有两个:匹配成功始终有输出,但是需要配置匹配不成功的输出,如下图:

Redirect rows to no match output :把匹配失败的数据行输出到no match的输出中。
二,Lookup组件异常
Lookup组件有两个输入数据源,一个是上流组件的输出,一个是组件Lookup的数据源,这个数据源是在Connection选项卡中进行配置。在开发package的过程中,我发现一个异常,当Lookup数据源没有返回数据时,会产生异常。异常信息如下:
[Lookup [2]] Error: Row yielded no match during lookup.
[Lookup [2]] Error: SSIS Error Code DTS_E_INDUCEDTRANSFORMFAILUREONERROR. The "Lookup" failed because error code 0xC020901E occurred, and the error row disposition on "Lookup.Outputs[Lookup Match Output]" specifies failure on error. An error occurred on the specified object of the specified component. There may be error messages posted before this with more information about the failure.
异常发生的原因是no match entries的输出,默认情况下Specify how to handle rows with no matching entries选项为Fail component。

变通方法是把:匹配失败的数据行重定向到no macth output。在General选项卡中,将Specify how to handle rows with no matching entries 指定为 Redirect rows to no match ouput.
