1,多表连接查询
语法:select 表1 inner/left/right/ join 表2 on 表1.字段 =表2.字段;
1.1>外链接之内链接.
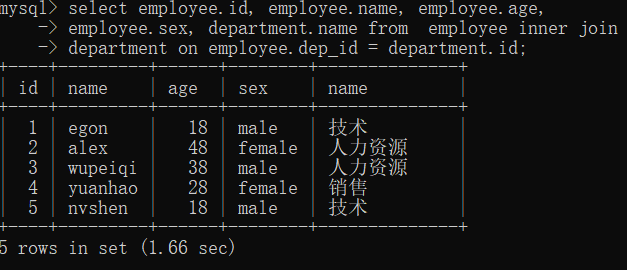
from department inner join employee onemployee.dep_id = department.id === from department, employee where employee.dep_id = department.id
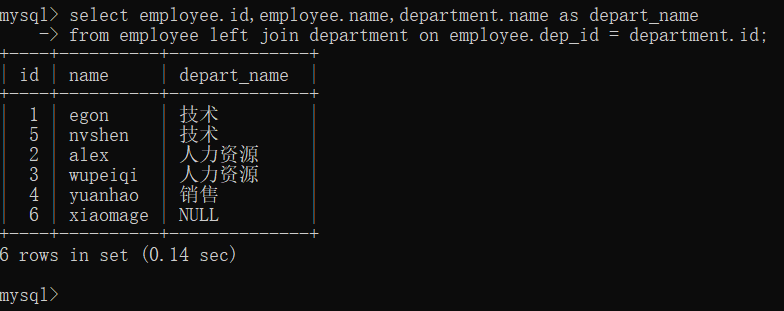
1.2>外链接之左连接
mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id #这里是把department_name重命名为depart_name
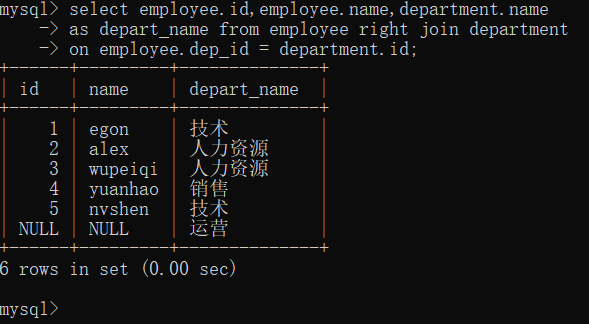
1.3>外链接之右连接
select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id = department.id;
1.4>全外链接(显示左右两个表匹配成功的全部记录)
在内连接的基础上增加左边和右边没有的结果,在mysql中是没有着个指令的,只是一种外在的一种巧妙的方法
语法:
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
;
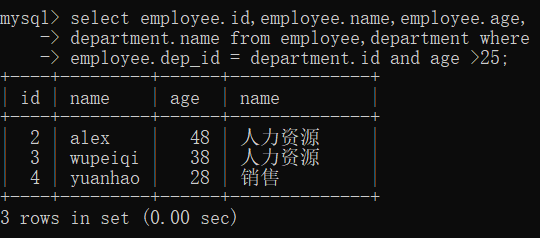
2,符合条件查询
select employee.name,department.name from employee inner join department on employee.dep_id = department.id where age > 25;
select employee.id,employee.name,employee.age,department.name from employee,department
where employee.dep_id = department.id
and age > 25
order by age asc;

3,子查询
3.1>带in的关键字查询
#1,子查询是将一个查询语句嵌套在另一个查询语句中, #2,内层查询语句的查询结果,可以作为外层查询语句提供查询条件. #3,子查询中可以包含:in,not,in,any,all,exists 和 not existsde 等关键字 #4,还可以包括比较运算符:=,!=,,>,<等
#查询平均年龄大于25岁以上的部门名字
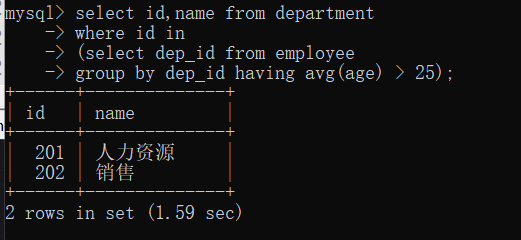
select id,name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25);
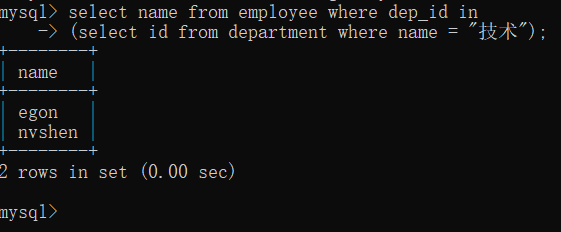
#查看计数部员工姓名 select name from employee where dep_id in (select id from department where name = "技术");
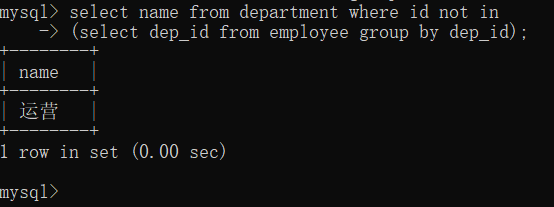
#查看不足1人的部门名 select name from department where id not in (select dep_id from employee group by dep_id);
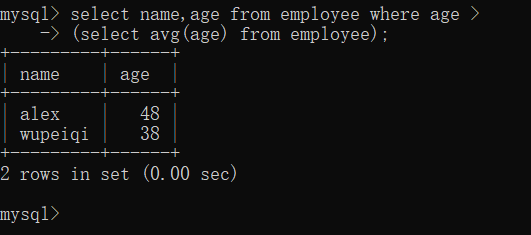
3.2>带比较运算符的子查询
##查询大于部门内平均年龄的员工名、年龄 select name,age from employee where age > (select avg(age) from employee);
3.3>带exists关键字的子查询
select * from employee where exists (select id from department where id= 200);
4,索引
4.1>索引的介绍
#数据库中专门用于帮助用户快速查找数据的一种数据结构 .类似于字典中的目录,查找字典内容时可以根据目录查找到数据存放的位置,然后直接获取内容
4.2>索引的作用
约束数据并且快速查找数据
4.3>常见的几种索引
-普通索引
-唯一索引
-主键索引
-联合索引(多列 )
-联合主键索引
-联合唯一索引
-联合普通索引
4.3.1>无索引和有索引的区别以及建立的目的
#无索引:从前往后,一条一条的查询 #有索引:创建索引的本质,就是创建额外的文件 (是某种格式的储存,查询的时候,先去格外的文件找,定好位置,然后再去原始表中直接查询,但是创建索引越多 ,对硬盘消耗越大,空间换时间) #建立索引的目的: #a,额外的晚间保存特殊的数据结构 #b,查询快 ,但是插入更新删除依然慢 #c,创建索引后 必须命中 索引才有用
4.3.2>索引的种类
hash索引和Btree (1)hash索引:查询倒要块,范围比较慢,(不适合范围查询) (2)btree索引:b+树,层级越多,数据量指数级增长(innoDB默认支差这个)
4.4>索引的介绍
4.4.1>普通索引
#创建表 及普通索引
create table userinfo( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, index ix_name(name) );
普通索引的创建
create index 索引的名字 on 表明(列名)
查看索引:
show index from 表名
删除索引 :
drop index 索引名 on 表名
4.4.2>唯一索引:加速查找和唯一约束
#创建 表及唯一索引
create table userinfo(
id int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
unique index ix_name(name)
);
创建唯一索引:
create unique index 索引名 on 表名(列名)
删除唯一索引:
drop index 索引名 on 表名
4.4.3>主题索引:功能:加速查找和唯一约束
create table userinfo(
id int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
unique index ix_name(name)
)
or
create table userinfo(
id int not null auto_increment,
name varchar(32) not null,
email varchar(64) not null,
primary key(nid),
unique index ix_name(name)
)
主键索引:
alter table 表名 add primary key (列名)
删除主键索引
alter table 表名 drop primary key;
alter table 表名 modify 列名 int, drop primary key
4.4.4>组合索引:组合索引是将n个列组合成一个索引
其应用场景为:频繁的使用n列来进行查询,如: where name = "alex" and "email" = "alex@qq.com".
联合普通索引的创建:
create index 索引名 on 表名(列名1,列名2);
5,索引名词
覆盖索引:在索引文件中直接获取数据
列如:
select name from userinfo where name = "alex50000";
索引合并 :把多个 单索引合并使用
列如:
select * from userinfo where name ="alex13131" and id = 13131
6,正确使用索引
数据库中添加索引后确实会让查询速度起飞,但前提必须使用索引来命名的字段来查询,如果不用,那么你给某一字段添加的字段的索引页毫无意义.
使用索引的三要素:(1)创建索引 (2)命中索引 (3)正确使用索引
#创建表
create table userinfo(
id int ,
name varchar(20),
gender char(6),
email varchar(50)
);
#插入数据
delimiter $$ #声明存储存储过程的结束符好为$$
create procedure auto_insert()
begin
declare i int default 1;
while(i<3000000)double
insert into userinfo values(i,concat("alex",i),"male",concat("xuexue",i,"@qq.com"));
set i = i + 1;
end while;
end #$$结束
delimiter; #重新声明分号为结束符号
插入数据需要一定的时间,我没有试出来...
查看存储过程:show create procedure auto_insert1g
调用存储过程:call auto_insert1();
7,索引的最左前缀的特点:
#最左前缀的匹配:
create index in_name_email on userinfo(name,email);
select * from userinfo where name = "xuexue";
select * from userinfo where name = "xuexue" and email="xuexue@qq.com";
select * from userinfo where email = "xuexue@qq.com";
#组合使用组合索引,name和email组合索引查询:
(1)name和email ----->使用索引
(2)name ----->使用索引
(3)email ----->不使用索引
对于同时搜索n个条件时,组合索引的性能好于单个索引
***********组合索引的性能>索引合并的性能********
8,索引的注意事项
(1)避免使用select * 这样的模糊查询 (2)count(1)或count(列)代替count(*) (3)创建表时尽量使用插入代替varchar (4)表的字段顺序固定长度的字段优先 (5)组合索引代替多个单列索引(经常使用多个条件查询) (6)使用连接(join)代替子查询 (7)联表时注意条件类型需要一致 (8)尽量使用短索引 (9)索引散列(重复少)不适用于建立索引,列如:性别不适
9,分页性能
第一页: select * from userinfo limit 0,10; 第二页: select * from userinfo limit 10,10; 第三页: select * from userinfo limit 20,10; 第四页: select * from userinfo limit 30,10; ...
性能优化
(1)只有上一页和下一页
做一个记录:记录当前页面的最大id或最小id
下一页:
select * from userinfo where id>max_id limit 10;
上一页:
select * from userinfo where id<min_id order by id desc limit 10;
(2)中间有页码的情况下
select * from userinfo where id in(
select id from (select * from userinfo where id>pre_max_id limit (cur_max_id-pre_max_id)*10) as A order by A.id desc limit 10);