1,hadoop:由Apache基金会所开发的分布式系统基础架构。
2,hadoop特点:
- 是一个分布式系统权限,有高容错性的特点,并且用来设计部署在低廉的硬件上,而且它提高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用
3,hadoop框架的核心设计:
- HDFS和mapreduse。HDFS为海量数据提供了存储而mapreduse则为海量数据提供了计算
4,hadoop的优点:
- hadoop是一个能够对大量数据进行分布式处理的软件框架,hadoop是一种可靠,高效可伸缩方式进行数据处理。
- hadoop是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够已失败的节点进行重新分布处理
- hadoop是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
- hadoop还是可伸缩的,可以处理pb级数据。
- 高可靠性:hadoop按为处理和存储数据和吹数据大的能力值得人们信赖。
- 高扩展性:hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便的扩展到数以亿计的节点中
- 高效性:hadoop能够在节点之间动态的移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性:hadoop能够自动保存数据的副本集,并且能够自动的将失败的任务重新分配。
- 低成本:与一体机,商业数据仓库等数据集相比,软件的成本会大大下降。
5,hadoop大数据处理的意义:
- hadoop得以在大数据处理应用中的广泛,得益于自身在数据提取,变形和加载的天然优势,hadoop的分布式框架,将大数据引擎尽可能的靠近存储,对例如像加载(elt)这样的批处理操作相对合适,类似于这样的操作批处理结果可以直接走向存储。hadoop中的mapreduce功能实现了将单个任务打碎,并将碎片任务(map)发送到多个节点上,最后在一单个数据集的形式加载(reduce)到数据仓库中。
6,hadoop核心架构图:
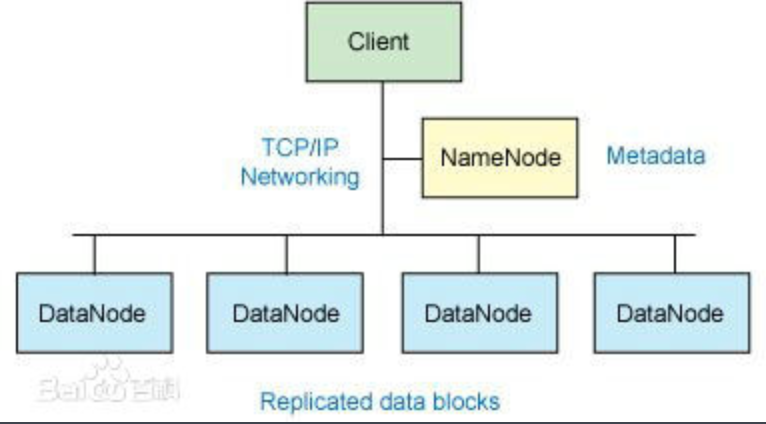
7,HDFS架构是基于一组特定的节点构建的,参考上图即可,因为仅存在与一个namenode,因此这是hadoop的一个缺点(单点失败)。HDFS的NameNode和DataNode
- NameNode:通常是在一个HDFS实例中单独机器上运行的软件。
- 它负责处理文件系统名称和控制客户外部机的访问
- DataNode:通常也是在HDFS实例中单独机器上运行的软件
- hadoop集群包含一个NameNode和大量DataNode,DataNode通常以几家的形式组织,机架通常以交换机将所有的系统链接起来。hadoop的一个假设就是:机架内部节点之间的传输速度快于机架间节点的传输速度
8,文件操作
- 它不是文能的文件系统,它主要的目的是以流的形式访问写入的大型文件
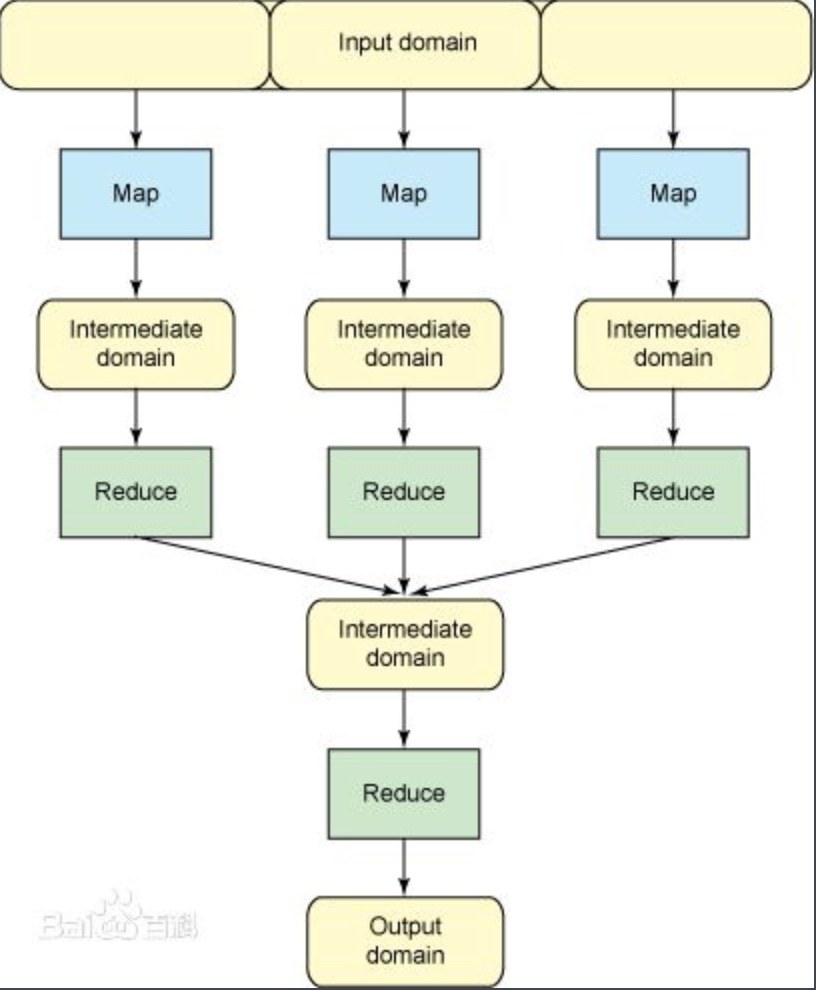
9,MapReduce:
- MapReduce应用程序包含3个部分:一个map函数,一个reduce函数,一个main函数。main函数将作业控制和文本输入输出结合起来
- mapreduce的框架图: