1.问题描述
2018-12-16 23:53起,因10.120.14.1节点出现问题,已经无法ssh上去,导致xxx lag延迟上升,在17日凌晨1:43掉线,落在该节点但leader partition无法转移,凌晨3点磁盘故障,恢复后集群大面积不可用,直至凌晨7:30以后集群逐渐恢复
起止时间:2018-12-16 23:53~2018-12-17 08:20
处理人:xxx、xxx、xxx
2.处理过程
2018-12-16 00:32 xxx收到cjv lag报警,查看日志发现10.120.14.1 broker链接失败
2018-12-17 00:37 与xxx取得联系后,确认14.1节点掉线,但尚不明确掉线机器会影响到服务不可用
2018-12-17 00:41 xxx尝试联系钉群联系运维请求处理故障节点,无法取得联系 ,xxx确认14.1上分配点leader partition无法服务,重启controller之后仍然无法更新metadata,尝试手动更新故障分区
2018-12-17 01:57 xxx联系到xxx,开始恢复故障服务器,因管理卡有问题,机房重置之后直至凌晨3点确认/data1磁盘故障,xxx在cloudera manager更改节点配置,启动节点
2018-12-17 03:50 xxx联系到xxx,此时发现集群大面积不可用状态,包括camus已经 index大面积报错,分析日志,所有节点直接无法互通,于4:30开始下掉14.1节点,重启集群
2018-12-17 05:30 节点下线,集群重启完毕,发现重要topic 甚至 __commit_offsets很多parittion leader 仍然无法转移,isr列表只有141节点,与此同时联系到李志涛
2018-12-17 06:00 xxx又重新启动 14.1节点,再次出现集群大面积不可用状态
2018-12-17 06:30 xxx说明现在 leader partition状态,并寻求可以丢失数据,让partition转移的办法
2018-12-17 08:00 xxx改回之前调整的配置,unclean.leader.election.enable = ture,集群逐渐恢复
2018-12-17 08:20 xxx确认cjv集群开始恢复,xxx通知依赖V2集群模型任务,各项逐渐恢复
3.影响范围
light cjv 在影响时间段内基本不可服务,相关算法模型任务也无法服务
4.思考总结
此次故障主要由两方面原因来看
其一:此次节点故障对原因是由 14.1节点网络不通导致大量超时,包括读写请求以及isr fetch 的剔除 ,节点问题,而节点问题分别在 2018-12-16 18:00、20:00、23:19分间断性出现问题,grafana监控已缺失,目前正请运维协助排查,到目前为止,确认不是所属交换机网络问题,根本原因尚未查明
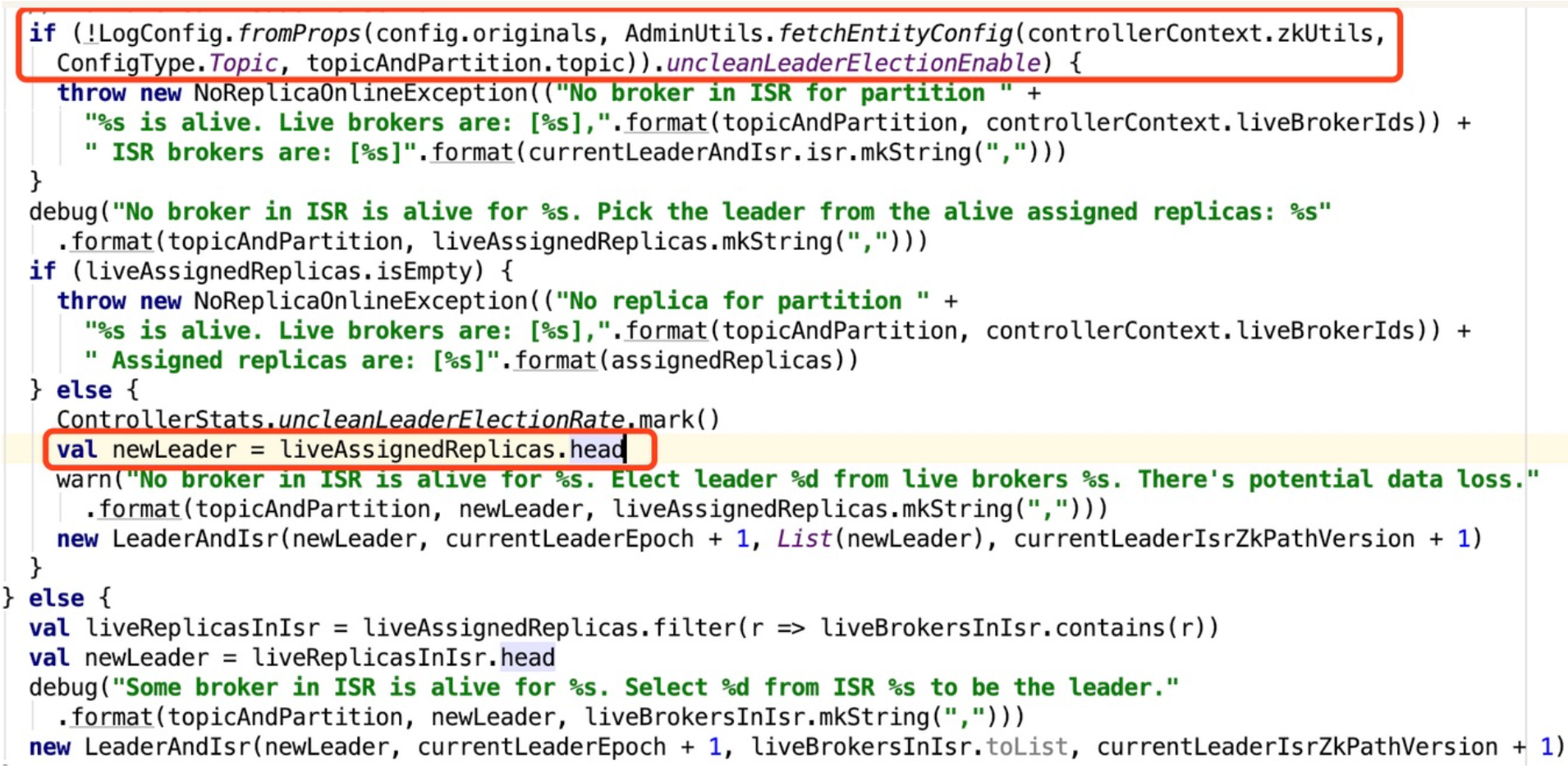
其二:此次因节点故障导致集群故障主要是由 unclean.leader.election.enable 参数引起的,对其解释 Kafka参数unclean.leader.election.enable详解,此前v2集群有不少参数被调整,包括这个参数
本次故障涉及14.1磁盘损坏问题,磁盘损坏在机器运行中避免不了,但参数调整不久就导致其中一个磁盘故障,尚不确认是否于调整的刷盘策略有影响
unclean.leader.election.enable概述如下:
unclean.leader.election.enable true kafka集群高可用优先,选择非ISR中副本作为leader,会丢失数据
unclean.leader.election.enable false kafka数据一致性优先,如果此时刚好ISR为0,则leader选举失败,然后大面积不可用
该集群属于线上算法模型训练的重要集群,吞吐量较高,参数的调整需要做足充分的验证,调整需要单一化,避免参数过多导致问题定位困难
对kafka各项参数的理解需要加深,适用场景以及极限情况触发条件等