一.相关知识
1.何为常量
第一种常量:是一个值,我们将这个值本身称为常量。比如:
整型常量:1024 实型常量:1.024 字符常量:'g' 'c' 'w' 字符串常量:"gcw" 逻辑常量:true false
例如,我们可以将数字1024称为一个int类型的常量。
第二种常量:不可变的变量,我们也称为常量。被关键字final修饰的变量,其值就不可以改变。可能它本身是个变量,但是被final修饰后,我们就可以认为它是个常量。比如:
final int i=1024;
2.常量池
常量池分为两种:静态常量池和运行时常量池。
(1)静态常量池也就是Class字节码文件中的常量池。我们举一个简单的例子,下面是一个HelloWorld的源文件和Class文件。
源文件:
public class HelloWorld{
public static void main(String args[]){
System.out.println("hello world");
}
}
class文件:

我们对class文件中的标识符予以一一分析。
①魔数
魔数是class字节码文件中的前四个字节:ca fe ba be(漱壕)。它的唯一作用是确定这个文件是否可以被JVM接受。很多文件存储标准中都使用魔数来进行身份识别。
②版本号
第5和第6个字节是次版本号,第7个和第8 个是主版本号。这里的第7和第8位是0034,即:0x0034。0x0034转为10进制是52。Java的版本是从45开始的然而从1.0 到1.1 是45.0到45.3, 之后就是1.2 对应46, 1.3 对应47 … 1.6 对应50,这里的1.6.0_24对应的是52,就是0x0034;
③常量池的入口
由于常量池中的常量的数量不是固定的,所以常量池的入口需要放置一项u2类型的数据,代表常量池的容量计数值。这里的常量池容量计数值是从1开始的。如图常量池的容量:0x001d(29)。所以共有29个常量。
④常量池
常量池中主要存放两类常量:字面量和符号引用。字面量是比较接近Java语言层面的常量概念,也就是我们提到的常量。符号引用则属于编译原理的方面的概念,包括三类常量:类和接口的全限定名;字段的名称和描述符;方法的名称和描述符。
(2)运行时常量池:运行时常量池是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外还有一项信息是常量池,它用于存放编译期生成的字面量和符号应用,这部分内容将在类加载后进入方法区的时候存到运行时常量池中。运行时常量池还有个更重要的的特征:动态性。Java要求,编译期的常量池的内容可以进入运行时常量池,运行时产生的常量也可以放入池中。常用的是String类的intern()方法【当调用 intern() 方法时,编译器会将字符串添加到常量池中(stringTable维护),并返回指向该常量的引用。 】。
3.常量池的好处
常量池是为了避免频繁地创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
(1)节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
(2)节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。
4.equals和==的区别
Java中的数据类型分两种:基本数据类型和引用数据类型。
(1)基本数据类型共8种:byte short int long char float double boolean。
对于基本数据类型的比较,都是用==来比较两者的值是不是相等。
(2)引用数据类型。
一般情况下,equals和==是一样的,都是比较的两者的地址值是不是一样。但是也有特殊情况,比如,我们都知道所有类都是继承自Object基类,Object中的equals方法中是使用==来实现的,即比较的是两者的地址值。但是,Object的子类可以重写equals方法,比如Date、String、Integer等类都是重写了equals()方法,比较的是值是否相等。例如,在String类的equals()源码中,先比较是不是指向同一个地址,如果不是再比较两者是不是值相等。这个时候,equals和==所表达的含义显然就不一样了。
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String) anObject;
int n = count;
if (n == anotherString.count) {
char v1[] = value;
char v2[] = anotherString.value;
int i = offset;
int j = anotherString.offset;
while (n-- != 0) {
if (v1[i++] != v2[j++])
return false;
}
return true;
}
}
return false;
}
二.8种基本数据类型
8种基本数据类型都有自己的包装类,其中有6个包装类(Byte,Short,Integer,Long,Character,Boolean)实现了常量池技术。举例来说,通过查看Integer的源码会发现,它有个内部静态类IntegerCache,这个内部静态类进行了缓存,范围是[-128,127],只要是这个范围内的数字都会缓存到里面,从而做成常量池进行管理。我们来看一个实例:
package com.itszt.test5;
/**
* Integer常量池
*/
public class IntegerTest {
public static void main(String[] args) {
Integer i1=10;
Integer i2=10;//在[-128-127之间,存入常量池]
System.out.println("i1 ==i2 ---> " + (i1==i2));
Integer i3=1000;
Integer i4=1000;//超出常量池范围,各自创建新的对象
System.out.println("i3 ==i4 ---> " + (i3==i4));
}
}
控制台打印结果:
i1 ==i2 ---> true i3 ==i4 ---> false
上述代码中,第一次把i1的值缓存进去了,当创建i2的时候,它其实是指向了第一次缓存进去的那个10,所以i1和i2指向了同一个地址;由于i3和i4均超出了常量池范围,故在堆内存中重新创建了两个对象,它们在堆内存中的地址不相等。
如果使用new关键字,意味着在堆内存中开辟了新的一块内存孔家。每次new一个对象都是在堆内存中开辟一块新的空间,所以每一个new出的对象的地址都不一样。
Float和Double没有实现常量池。代码演示如下:
Float f1=10.0f;
Float f2=10.0f;
System.out.println("f1 =f2 ---> " + (f1==f2));
Double d1=12.0;//默认为double类型
Double d2=12.0d;
System.out.println("d1 =d2 ---> " + (d1==d2));
上述代码在main()主函数中执行后,控制台打印如下:
f1 = f2 ---> false d1 =d2 ---> false
三.String类
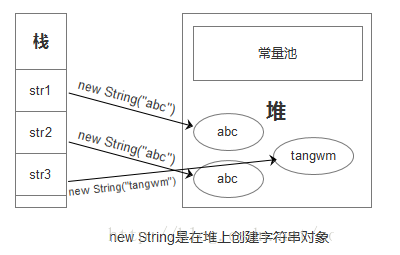
1.new String都是在堆上创建字符串对象。
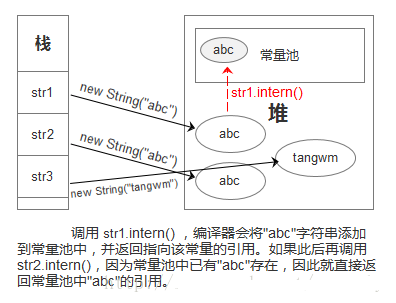
2.当调用 intern() 方法时,编译器会将字符串添加到常量池中(stringTable维护),并返回指向该常量的引用。
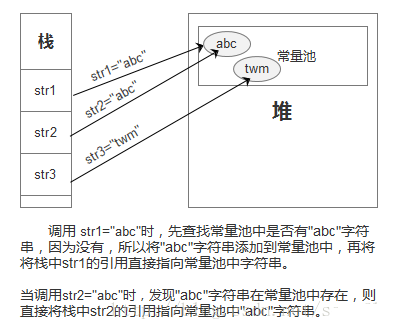
3.通过字面量赋值创建字符串(如:String str=”twm”)时,会先在常量池中查找是否存在相同的字符串,若存在,则将栈中的引用直接指向该字符串;若不存在,则在常量池中生成一个字符串,再将栈中的引用指向该字符串。
4.常量字符串的“+”操作,编译阶段直接会合成为一个字符串。如string str=”JA”+”VA”,在编译阶段会直接合并成语句String str=”JAVA”,于是会去常量池中查找是否存在”JAVA”,从而进行创建或引用。
5.对于final字段,编译期直接进行了常量替换(而对于非final字段则是在运行期进行赋值处理的)。
final String str1=”ja”;
final String str2=”va”;
String str3=str1+str2;
在编译时,直接替换成了String str3=”ja”+”va”,然后再次替换成String str3=”JAVA”。
6.常量字符串和变量拼接时(如:String str3=baseStr + “01”;)会调用stringBuilder.append()在堆内存上创建新的对象。
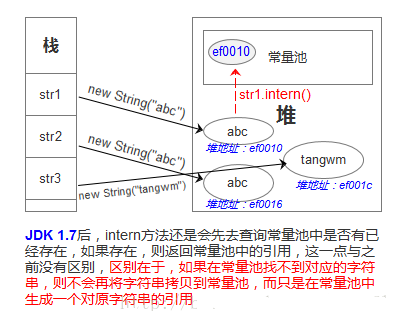
7.在JDK 1.7后,intern()方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池中找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。简单的说,就是往常量池放的东西变了:原来在常量池中找不到时,复制一个副本放到常量池,1.7后则是将在堆上的地址引用复制到常量池。
四.常见试题解答:
Q:下列程序的输出结果:
String s1= “abc”;
String s2= “abc”;
System.out.println(s1==s2);
A:true,均指向常量池中对象。
Q:下列程序的输出结果:
String s1=new String(“abc”);
String s2=new String(“abc”);
System.out.println(s1==s2);
A:false,两个引用指向堆中的不同对象。
Q:下列程序的输出结果:
String s1 = “abc”;
String s2 = “a”;
String s3 = “bc”;
String s4 = s2 + s3;
System.out.println(s1 == s4);
A:false,因为s2+s3实际上是使用StringBuilder.append来完成,
会生成不同的对象。
Q:下列程序的输出结果:
String s1 = “abc”;
final String s2 = “a”;
final String s3 = “bc”;
String s4 = s2 + s3;
System.out.println(s1 == s4);
A:true,因为final变量在编译后会直接替换成对应的值,
所以实际上等于s4=”a”+”bc”,而这种情况下,
编译器会直接合并为s4=”abc”,所以最终s1==s4。
Q:下列程序的输出结果:
String s = new String(“abc”);
String s1 = “abc”;
String s2 = new String(“abc”);
System.out.println(s == s1.intern());
System.out.println(s == s2.intern());
System.out.println(s1 == s2.intern());
A:false,false,true。