节点亲缘性规则可以影响pod被调度到哪个节点。但是,这些规则只影响了pod和节点之间的亲缘性。然而,有些时候也希望能有能力指定pod自身之间的亲缘性。
举例来说,想象一下有一个前端pod和一个后端pod, 将这些节点部署得比较靠近,可以降低延时,提高应用的性能。可以使用节点亲缘性规则来确保这两个pod被调度到同一个节点、同一个机架、同一个数据中心。但是,之后还需要指定调度到具体哪个节点、哪个机架或者哪个数据中心。因此,这不是一个最佳的解决方案。更好的做法应该是,让Kubernetes将pod部署在任何它觉得合适的地方。
同时确保 2个pod是靠近的。这种功能可以通过pod亲缘性来实现。
1.使用pod间亲缘性将多个pod部署在同一个节点
实验环境1个后端pod和5个包含pod亲缘性配置的前端pod实例,使得这些前端实例将被部署在后端pod所在的同一个节点上。
首先,先部署后端pod:
$ kubectl run backend -l app=backend --image busybox -- sleep 999999 deployment "backend" created
在pod定义中指定pod亲缘性
#代码 16.13 使用podAffinity的pod: frontend-podaffinity-host.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: frontend spec: replicas: 5 template: metadata: labels: app: frontend spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: #定一个强制性要求,而不是偏好 - topologyKey: kubernetes.io/hostname #本次部署的pod,必须被调度到匹配pod的选择器节点上 labelSelector: matchLabels: app: backend containers: - name: main image: busybox args: - sleep - "99999"
代码显示了,该部署将创建包含强制性要求的pod,其中要求pod将被调度到和其他包含app=backend标签的pod所在的相同节点上(通过topologyKey字段指定),如图16.4所示。

注意:除了使用简单的matchLabels字段,也可以使用表达能力更强的matchExpressions字段。
部署包含pod亲缘性的pod
现在先确认之前的后端 pod被调度到了哪个节点上:
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
backend-257820-qhqj6 1/1 Running 0 8m 10.47.0.1 node2.k8s
创建前端 pod 时, 它们应该也会被调度到node2 上。接着开始创建Deployment, 然后看 pod被调度到了哪里。
#代码16.14 部署前端pod,观察pod被调度到哪些节点 $ kubectl create -f frontend-podaffinity-host.yaml deployment "frontend" created $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE backend-257820-qhqj6 1/1 Running 0 8m 10.47.0.1 node2.k8s frontend-121895-2c1ts 1/1 Running 0 13s 10.47.0.6 node2.k8s frontend-121895-776m7 1/1 Running 0 13s 10.47.0.4 node2.k8s frontend-121895-7ffsm 1/1 Running 0 13s 10.47.0.8 node2.k8s frontend-121895-fpgm6 1/1 Running 0 13s 10.47.0.7 node2.k8s frontend-121895-vb9ll 1/1 Running 0 13s 10.47.0.5 node2.k8s
了解调度器如何使用 pod 亲缘性规则
有趣的是,如果现在删除了后端pod,调度器会将该pod调度到node2,即便后端pod本身没有定义任何pod亲缘性规则(只有前端pod设置了规则)。这种情况很合理,因为假设后端pod被误删除而被调度到其他节点上,前端pod的亲缘性规则就被打破了。
如果增加调度器的日志级别检查它的日志的话, 可以确定调度器是会考虑其他pod 的亲缘性规则的。 下面的代码清单显示了相关的日志。
#代码16.15 调度器日志显示了后端pod被调度到node2的原因 ... Attempting to schedule pod: default/backend-257820-qhqj6 ... ... ... backend-qhqj6 -> node2.k8s: Taint Toleration Priority, Score: (10) ... backend-qhqj6 -> node1.k8s: Taint Toleration Priority, Score: (10) ... backend-qhqj6 -> node2.k8s: InterPodAffinityPriority, Score: (10) ... backend-qhqj6 -> node1.k8s: InterPodAffinityPriority, Score: (0) ... backend-qhqj6 -> node2.k8s: SelectorSpreadPriority, Score: (10) ... backend-qhqj6 -> node1.k8s: SelectorSpreadPriority, Score: (10) ... backend-qhqj6 -> node2.k8s: NodeAffinityPriority, Score: (0) ... backend-qhqj6 -> node1.k8s: NodeAffinityPriority, Score: (0) ... Host node2.k8s => Score 100030 ... Host node1.k8s => Score 100022 ... Attempting to bind backend-257820-qhqj6 to node2.k8s
加粗的两行日志,发现当调度后端pod时,由于pod间亲缘性,node2获得了比node1更高的分数。
2.将pod部署在同一机柜、可用性区域或者地理地域
在前面的例子中,使用了pod.Affinity将前端pod和后端pod部署在了同一个节点上。你可能不希望所有的前端pod都部署在同一个节点上,但仍希望和后端pod保持足够近,比如在同一个可用性区域中。
在同一个可用性区域中协同部署pod
如果集群节点运行在不同的可用性区域中,那么需要将topologyKey属性设置为failure-domain.beta.kubernetes.io/zone,以确保前端pod和后端pod运行在同一个可用性区域中。
在同一个地域中协同部署pod
如果要将pod部署在同一个地域而不是区域内(云服务提供商通常拥有多个地理地域的数据中心,每个地理地域会被划分成多个可用性区域),那么需要将topologyKey属性设置为failure-domain.beta.kubernetes.io/region。
了解topologyKey是如何工作的
topologyKey的工作方式很简单,目前提到的3个键并没有什么特别的。 如果你愿意,可以任意设置自定义的键,例如rack,为了让pod能部署到同一个机柜。唯一的前置条件就是,在节点上加上rack标签。
举例来说,有20个节点,每10个节点在同一个机柜中,你将前10个节点加上标签rack=rack1,另外10个加上标签rack=rack2。接着,当定义pod的podAffinity时,将toplogyKey设置为rack。
当调度器决定pod调度到哪里时,它首先检查pod的podAffinity配置,找出那些符合标签选择器的pod,接着查询这些pod运行在哪些节点上。特别的是,它会寻找标签能匹配podAffinity配置中topologyKey的节点。接着,它会优先选择所有的标签匹配pod的值的节点。在图16.5中,标签选择器匹配了运行在Node 12的后端pod,那个节点rack标签只等于rack2.所以,当调度1个前端pod时,调度器只会在包含标签rack=rack2的节点中进行选择。

注意:在调度时,默认情况下,标签选择器只有匹配同一命名空间中的pod。但是,可以通过在labelSelector同一级添加namespaces字段,实现从其他的命名空间选择pod的功能。
3.表达pod亲缘性优先级取代强制性要求
另外介绍过节点亲缘性,nodeAffinity可以表示一种强制性要求,表示pod只能被调度到符合节点亲缘性规则的节点上。它也可以表示一种节点优先级,用于告知调度器将pod调度到某些节点上,同时也满足当这些节点出于各种原因无法满足pod要求时,将pod调度到其他节点上。
这种特性同样适用于podAffinity,你可以告诉调度器,优先将前端pod调度到和后端pod相同的节点上,但是如果不满足需求,调度到其他节点上也是可以的。一个使用了preferredDuringSchedulingIgnoredDuringExecutionpod亲缘性规则的Deployment的样例如以下代码清单所示。
#代码16.16 pod亲缘性优先级 apiVersion: extensions/v1beta1 kind: Deployment metadata: name: frontend spec: replicas:5 template: ... spec: affinity: podAffinity: preferredDuringSchedulingIgnoredDuringExecution: #使用了Preferred,而不是required - weight: 80 #weight和podAffinityTerm设置为和之前例子中一样的值 podAffinityTerm: topologyKey: kubernetes.io/hostname labelSelector: matchLabels: app: backend containers:
注意:以上的策略有2个:
-
- requiredDuringSchedulingIgnoredDuringExecution 硬策略表示调度过程必须满足执行过程忽略
- preferredDuringSchedulingIgnoredDuringExecution 软策略表示调度过程尽量满足执行过程忽略
跟nodeAffinity优先级规则一样,需要为一个规则设置一个权重。同时也需要设置topologyKey和labelSelector,正如podAffinity规则中的强制性要求一样。图16.6展示了这种场景。
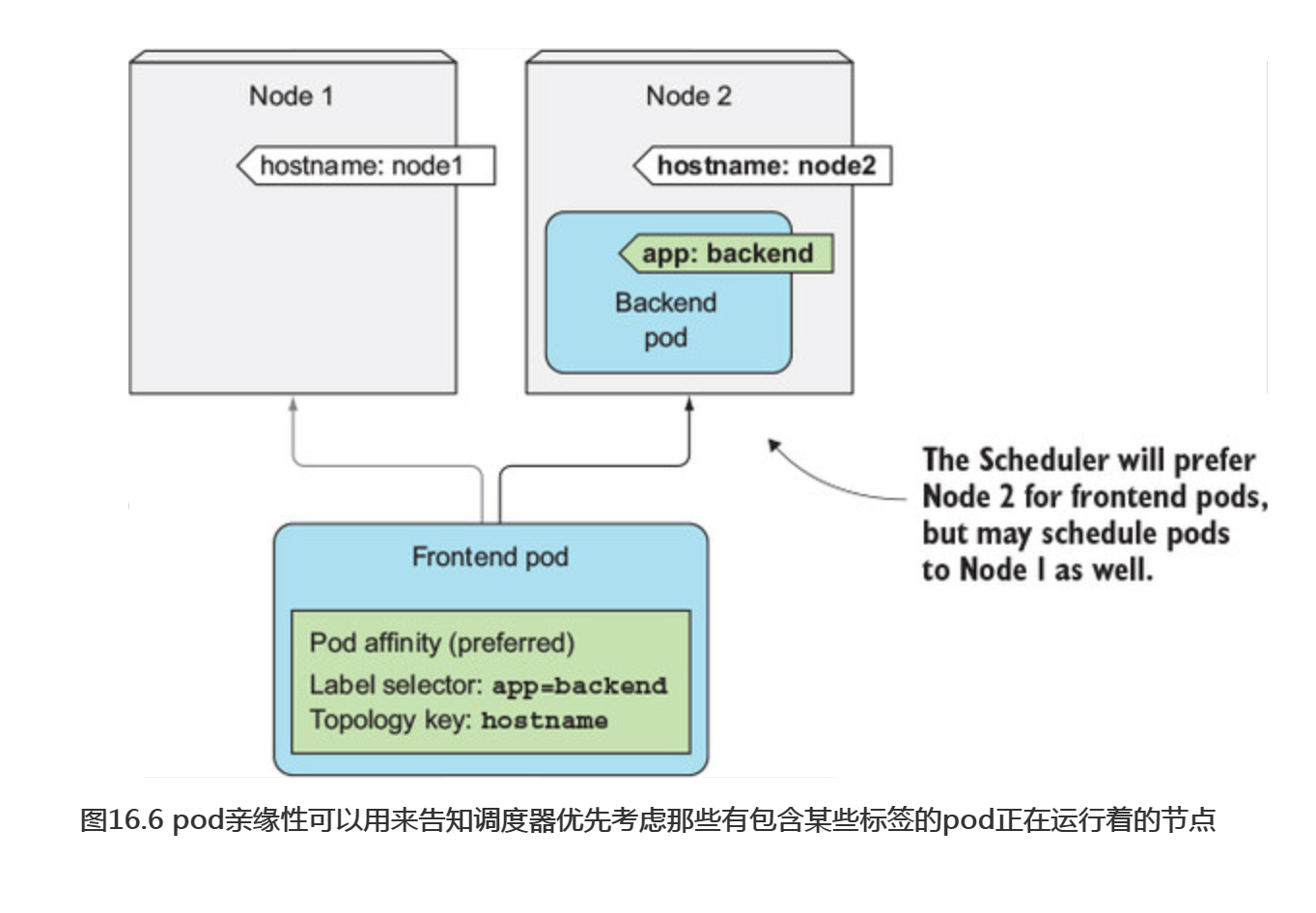
正如nodeAffinty样例,部署将4个pod调度到和后端pod一样的节点,另外一个调度到了其他节点(如下面的代码清单所示)。
#代码16.17 使用podAffinity优先级的pod部署 $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE backend-257820-ssrgj 1/1 Running 0 1h 10.47.0.9 node2.k8s frontend-941083-3mff9 1/1 Running 0 8m 10.44.0.4 node1.k8s frontend-941083-7fp7d 1/1 Running 0 8m 10.47.0.6 node2.k8s frontend-941083-cq23b 1/1 Running 0 8m 10.47.0.1 node2.k8s frontend-941083-m70sw 1/1 Running 0 8m 10.47.0.5 node2.k8s frontend-941083-wsjv8 1/1 Running 0 8m 10.47.0.4 node2.k8s
4.利用pod的非亲缘性分开调度pod
上面的例子就是告诉调度器对pod进行协同部署,但有时候你的需求却恰恰相反,可能希望pod远离彼此。这种特性叫作pod非亲缘性(反亲和性)。它和pod亲缘性的表示方式一样, 只不过是将podAffinity字段换成podAntiAffinity,这将导致调度器永远不会选择那些有包含podAntiAffinity匹配标签的pod所在的节点。如图16.7所示。
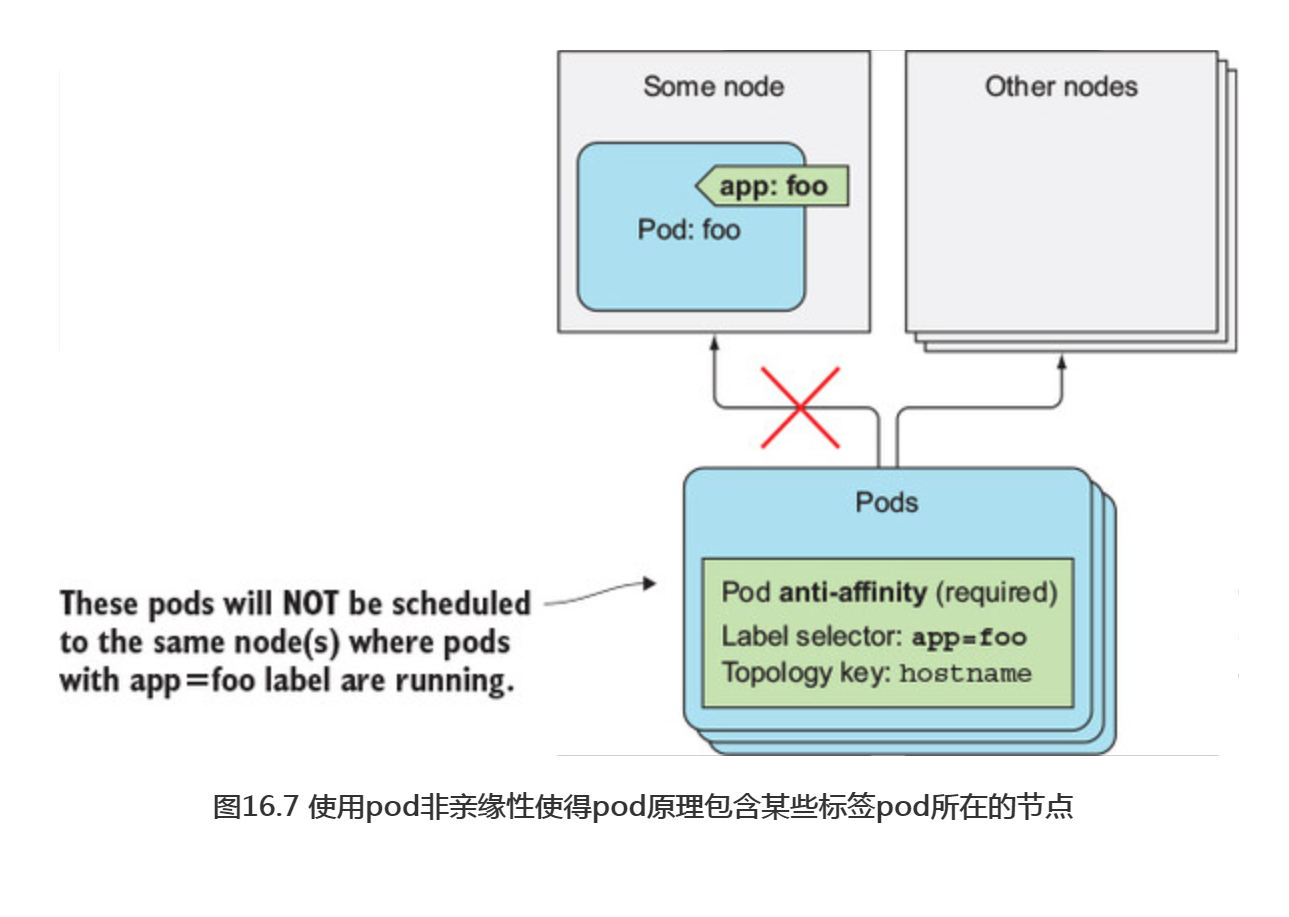
一个为什么需要使用pod非亲缘性的例子,就是当两个集合的pod,如果运行在同一个节点上会影响彼此的性能。在这种情况下,需要告知调度器永远不要将这些pod部署在同一个节点上。另一个例子是强制让调度器将同一组的pod分在在不同的可用性区域或者地域,这样让整个区域或地域失效之后,不会使得整个服务完全不可用。
使用非亲缘性分散一个部署中的pod
让来看一下如何强制前端pod被调度到不同节点上。下面的代码清单展示了pod的非亲缘性是如何配置的。
#代码16.18 包含非亲缘性的 pod : frontend-podantiaffinity-host.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: frontend spec: replicas: 5 template: metadata: labels: app: frontend spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: #定义pod非亲缘性强制性要求 - topologyKey: kubernetes.io/hostname #一个前端pod必须不能调度到app=frontend标签的pod运行的节点 labelSelector: matchLabels: app: frontend containers: - name: main image: busybox args: - sleep - "99999"
这次,需要定义podAntiAffinty而不是podAffinity, 并且将label Selector和 Deployment创建的pod匹配。看一下当创建了该Deployment之后会发生什么,创建的pod 如下面的代码所示。
#代码16.19 Deployment创建的pod $ kubectl get po -l app=frontend -o wide NAME READY STATUS RESTARTS AGE IP NODE frontend-286632-0lffz 0/1 Pending 0 1m <none> frontend-286632-2rkcz 1/1 Running 0 1m 10.47.0.1 node2.k8s frontend-286632-4nwhp 0/1 Pending 0 1m <none> frontend-286632-h4686 0/1 Pending 0 1m <none> frontend-286632-st222 1/1 Running 0 1m 10.44.0.4 node1.k8s
只有2个pod被调度,一个在node1上,另一个在node2上。 剩下的3个pod均处于Pending状态,因为调度器不允许这些pod调度到同一个节点上。
理解pod非亲缘性忧先级
在这种情况下,可能应该制定软性要求(使用preferredDuringSchedu linglgnoredDuringExecution字段)。毕竟,如果有2个前端pod运行在同一个节点上也不是什么大问题。但是如果运行在同一个节点上会造成问题的场景下,使用requiredDuringScheduling就比较合适了。
与使用pod亲缘性一样,topologyKey字段决定了pod不能被调度的范围。可以使用这个字段决定pod不能被调度到同一个机柜、可用性区域、地域,或者任何创建的自定义节点标签标示的范围。