1.了解ReplicationController
ReplicationController是一种kubernetes资源,可确保它的pod始终保持运行状态。 如果pod因任何原因消失(例如节点从集群中消失或由于该pod己从节点中逐出),则ReplicationController会注意到缺少了pod并创建替代pod。
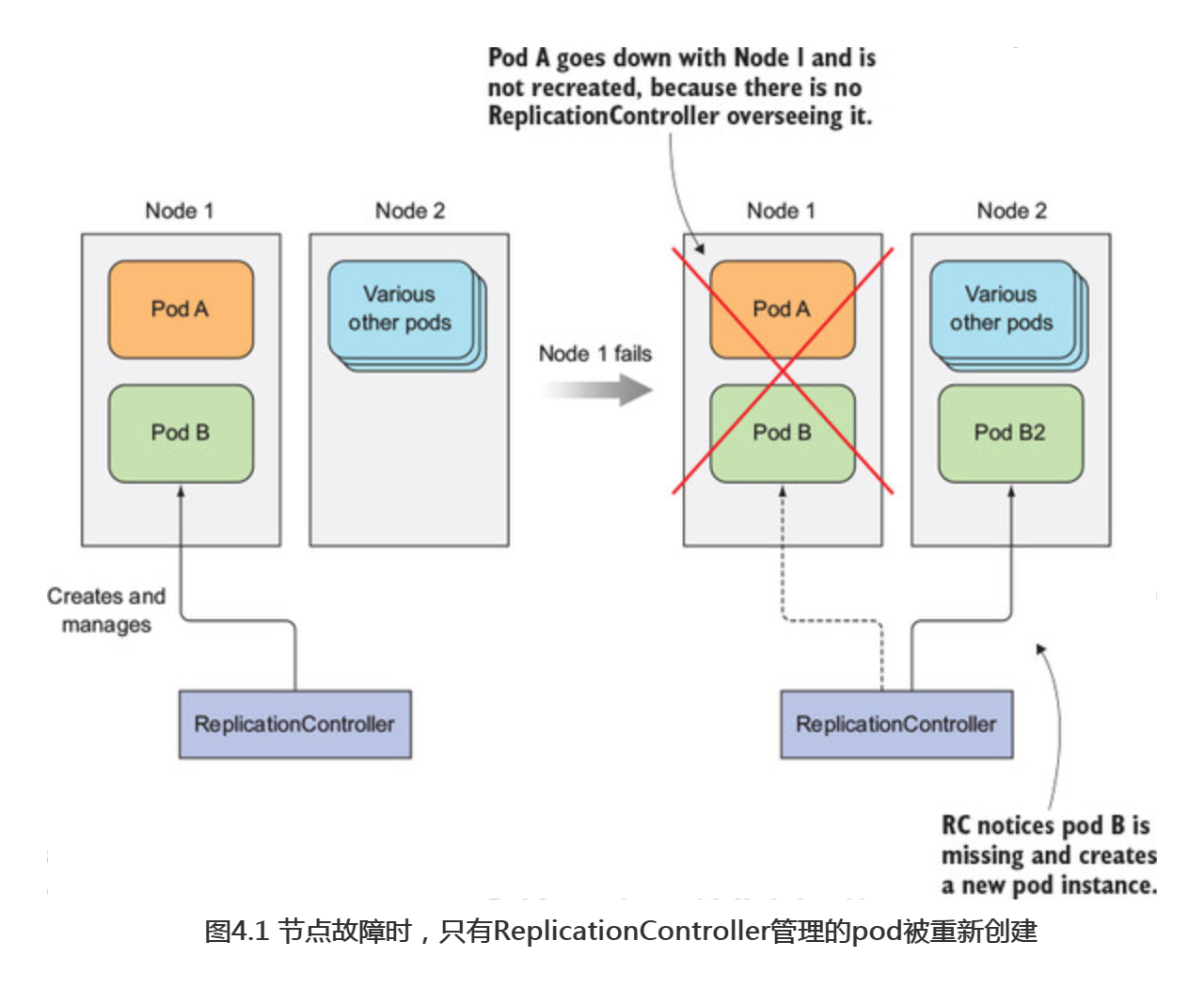
图4.1显示了当一个节点下线且带有两个pod时会发生什么。Pod A是被直接创建的,因此是非托管的pod,而podB由ReplicationController管理。节点异常退出后,ReplicationController会创建一个新的pod(pod B2)来替换缺少的podB,而podA完全丢失——没有东西负责重建它。
图中的ReplicationController只管理一个pod,但一般而言,ReplicationController旨在创建和管理—个pod的多个副本(replicas)。这就是ReplicationController名字的由来。
1.1 ReplicationController的操作
ReplicationController会持续监控正在运行的pod列表,并保证相应“类型”的pod的数目与期望相符。如正在运行的pod太少,它会根据pod模板创建新的副本。如正在运行的pod太多,它将删除多余的副本。你可能会对有多余的副本感到奇怪。这可能有几个原因:
-
- 有人会手动创建相同类型的pod。
- 有人更改现有的pod的“类型”。
- 有人减少了所需的pod的数量,等等。
这里第二个有人更改现有的pod的“类型”是不存在的。ReplicationController不是根据pod类型来执行操作的,而是根据pod是否匹配某个标签选择器。
介绍控制器的协调流程
ReplicationController的工作是确保pod的数量始终与其标签选择器匹配。如果不匹配,则ReplicationController将根据所需,采取适当的操作来协调pod的数量。图4.2显示了ReplicationController的操作。

了解ReplicationController的三部分
—个ReplicationController有三个主要部分(如图4.3所示):

-
- Label selector (标签选择器),用于确定ReplicationController作用域中有哪些pod
- replica count(副本个数),指定应运行的pod数量
- pod template(pod模板),用于创建新的pod副本
ReplicationController的副本个数、标签选择器,甚至是pod模板都可以随时修改,但只有副本数目的变更会影响现有的pod。
更改控制器的标签选择器或pod模板的效果
更改标签选择器和pod模板对现有pod没有影响。更改标签选择器会使现有的pod脱离ReplicationController的范围,因此控制器会停止关注它们。在创建pod后,ReplicationController也不关心其pod的实际“内容”(容器镜像、环境变量及其他)。因此,该模板仅影响由此ReplicationController创建的新pod。可以将其视为创建新pod 的曲奇切模(cookiecutter)。
使用ReplicationController的好处
像Kubernetes中的许多事物一样,ReplicationController尽管是一个令人难以置信的简单概念,却提供或启用了以下强大功能:
-
- 确保一个pod (或多个pod副本)持续运行,方法是在现有pod丢失时启动一个新pod。
- 集群节点发生故障时,它将为故障节点上运行的所有pod (即受 ReplicationController控制的节点上的那些pod)创建替代副本。
- 它能轻松实现pod的水平伸缩---手动和自动都可以。
注意: pod实例永远不会重新安置到另一个节点。相反,ReplicationController会创建一个全新的pod实例, 它与正在替换的实例无关。
1.2 创建一个ReplicationController
现在了解一下如何创建一个ReplicationController,然后看看它如何pod运行。就像pod和其他Kubernetes资源,可以通过上传JSON或YAML描述文件到Kubernetes API服务器来创建ReplicationController。
现在创建一个ReplicationController创建名为kubia-rc.yaml的YAML文件,如下面的代码清单所示。
#代码4.4 ReplicationController的YAML定义: kubia-rc.yaml
apiVersion: v1 kind: ReplicationController #这里定义ReplicationController(RC) metadata: name: kubia #ReplicationController的名字 spec: replicas: 3 #pod实例的目标数目 selector: #pod选择器决定了RC的操作对象 app: kubia template: #下面都是创建pod所用的pod模版 metadata: labels: app: kubia spec: containers: - name: kubia image: luksa/kubia ports: - containerPort: 8080
上传文件到API服务器时,Kubernetes会创建一个名为kubia的新ReplicationController,它确保符合标签选择器app=kubia的pod实例始终是三个。当没有足够的pod时,根据提供的pod模板创建新的pod。
模板中的pod标签显然必须和ReplicationController的标签选择器匹配,否则控制器将无休止地创建新的容器。因为启动新pod不会使实际的副本数量接近期望的副本数量。为了防止出现这种情况,API服务会校验ReplicationController的定义,不会接收错误配置。
根本不指定选择器也是一种选择。在这种情况下,它会自动根据pod模板中的标签自动配置。
提示: 定义ReplicationController时不要指定pod选择器,让Kubernetes从pod模 板中提取它。这样YAML更简短。
1.3 使用ReplicationController
由于没有任何pod有app=kubia标签,ReplicationController会根据pod模板启动二个新的pod。列出pod以查看ReplicationController是否完成了它应该做的事情:
$ kubectl get pods NAME READY STATUS RESTARTS AGE kubia-53thy 0/1 ContainerCreating 0 2s kubia-k0xz6 0/1 ContainerCreating 0 2s kubia-q3vkg 0/1 ContainerCreating 0 2s
它确实创建了三个pod。现在ReplicationController正在管理这三个pod。接下来, 将通过稍稍破坏它们来观察ReplicationController如何响应。
查看ReplicationController对已删除的pod的响应
首先,手动删除其中一个pod,以查看ReplicationController如何立即启动新容器,从而将匹配容器的数量恢复为三:
$ kubectl delete pod kubia-53thy pod "kubla-53thy" deleted
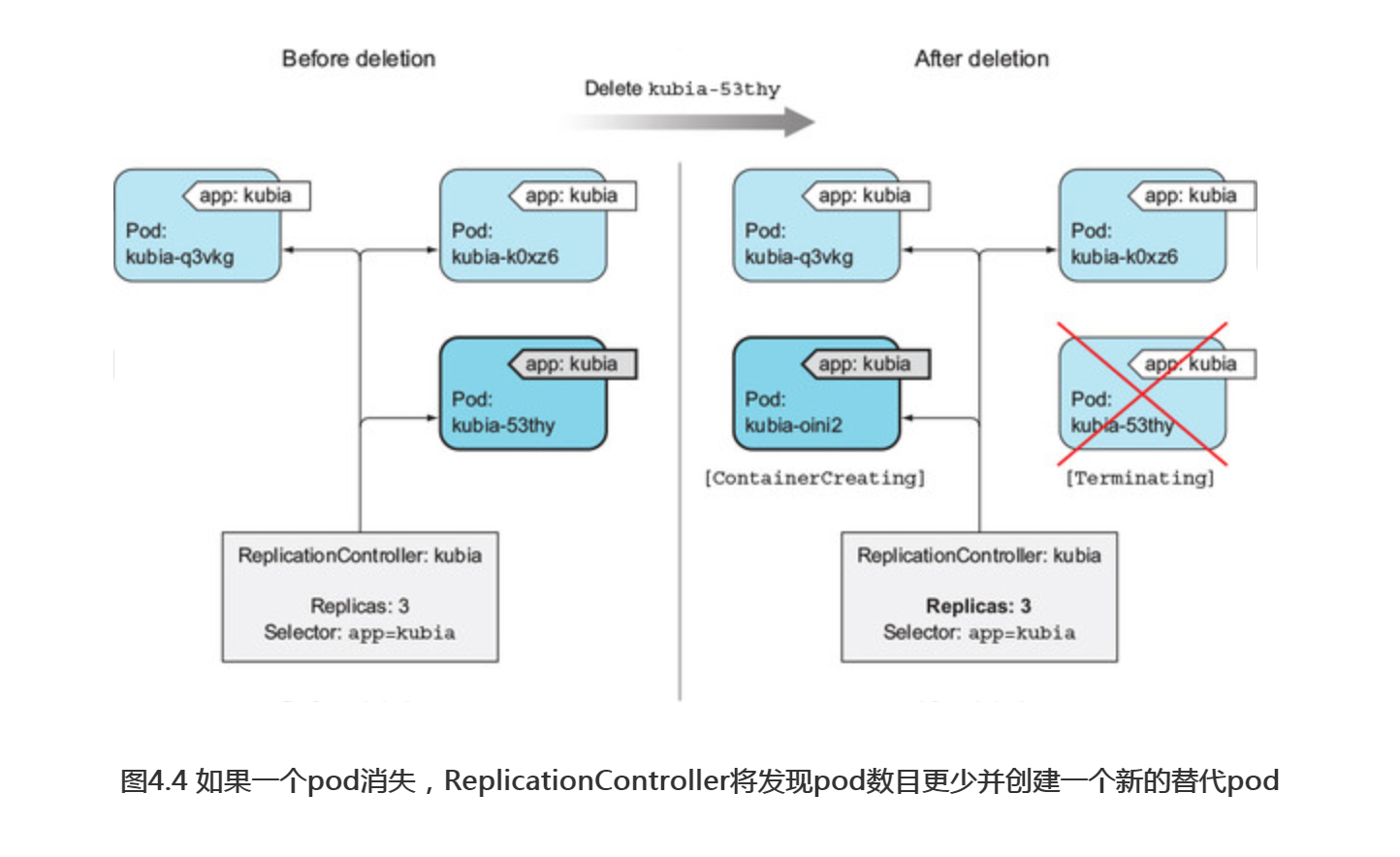
重新列出pod会显示四个,因为你删除的pod己终止,并且己创建一个新的pod:
$ kubectl get pods NAME READY STATUS RESTARTS AGE kubia-53thy 1/1 Terminating 0 3m kubia-oini2 0/1 ContainerCreating 0 2s kubia-k0xz6 1/1 Running 0 3m kubia-q3vkg 1/1 Running 0 3m
ReplicationController再次完成了它的工作。这是非常有用的。
获取有关ReplicationController的信息
通过kubectl get命令显示的关于ReplicationController的信息:
$ kubectl get rc #rc是ReplicationController的缩写 NAME DESIRED CURRENT READY AGE kubia 3 3 2 3m
看到三列显示了所需的pod数量,实际的pod数量,以及其中有多少pod 己准备就绪可以通过kubectl describe命令看到ReplicationController的附加信息。
$ kubectl describe rc kubia Name: kubia Namespace: default Selector: app=kubia Labels: app=kubia Annotations: <none> Replicas: 3 current / 3 desired Pods Status: 4 Running / 0 Waiting / 0 Succeeded / 0 Failed Pod Template: Labels: app=kubia Containers: ... Volumes: <none> Events: From Type Reason Message ---- ------- ------ ------- replication-controller Normal SuccessfulCreate Created pod: kubia-53thy replication-controller Normal SuccessfulCreate Created pod: kubia-k0xz6 replication-controller Normal SuccessfulCreate Created pod: kubia-q3vkg replication-controller Normal SuccessfulCreate Created pod: kubia-oini2
当前的副本数与所需的数量相符,因为控制器己经创建了一个新的pod。它显示了四个正在运行的pod,因为被终止的pod仍在运行中,尽管它并未计入当前的副本个数中。底部的事件列表显示了ReplicationCaitroller的行为——它到目前为止创建了四个pod。
控制器如何创建新的pod
控制器通过创建一个新的替代pod来响应pod的删除操作(见图4.4)。从技术上讲,它并没有对删除本身做出反应,而是针对由此产生的状态----pod数量不足。
虽然ReplicationCaitroller会立即收到删除pod的通知(API服务器允许客户端监听资源和资源列表的更改),但这不是它创建替代pod的原因。该通知会触发控制器检查实际的pod数量并采取适当的措施。
应对节点故障
看着ReplicationController对手动删除pod做出响应没什么意思,所以看一个更好的示例。如果用Google Kubernetes Engine来运行这些示例,那么己经有一个三节点Kubernetes集群。将从网络中断开其中一个节点来模拟节点故障。
注意:如果使用Minikube,则无法做这个练习,因为只有一个节点同时充当主节点和工作节点。
如果节点在没有Kubernetes的场景中发生故障,运维人员需要手动将节点上运行的应用程序迁移到其他机器。而现在Kubernetes会自动执行此操作。在ReplicationController检测到它的pod己关闭后不久,它将启动新的pod以替换它们。
在实践中看看这个行为。需要使用gcloud compute ssh命令ssh 进入其中一个节点,然后使用sudo ifconfig eth0 down关闭其网络接口,如下面的代码清单所示。
$ gcloud compute ssh gke-kubia-default-pool-b46381f1-zwko Enter passphrase for key '/home/luksa/.ssh/google_compute_engine': Welcome to Kubernetes v1.6.4! ... luksa@gke-kubia-default-pool-b46381f1-zwko ~ $ sudo ifconfig eth0 down
当你关闭网络接口时,ssh会话将停止响应,所以需要打开另一个终端或强行退出ssh会话。在新终端中,可以列出节点以查看Kubernetes是否检测到节点下线。这需要一分钟左右的时间。然后,该节点的状态显示为NotReady:
$ kubectl get node NAME STATUS AGE gke-kubia-default-pool-b46381f1-opc5 Ready 5h gke-kubia-default-pool-b46381f1-s8gj Ready 5h gke-kubia-default-pool-b46381f1-zwko NotReady 5h #节点与网络断开
如果你现在列出pod,那么仍然会看到三个与之前相同的pod,因为 Kubernetes在重新调度pod之前会等待一段时间(如果节点因临时网络故障或Kubelet重新启动而无法访问)。如果节点在几分钟内无法访问,则调度到该节点的pod的状态将变为Unknown。此时,ReplicationController将立即启动一个新的pod。可以通过再次列出pod来看到这一点:
$ kubectl get pods NAME READY STATUS RESTARTS AGE kubia-oini2 1/1 Running 0 10m kubia-k0xz6 1/1 Running 0 10m kubia-q3vkg 1/1 Unknown 0 10m #此pod状态未知,因为其节点无法访问 kubia-dmdck 1/1 Running 0 5s #这个pod是5秒前创建的
注意pod的存活时间,你会发现kubia-dmdck pod是新的。你再次拥有三个运行的pod实例,这意味着ReplicationController再次开始它的工作,将系统的实际状态置于所需状态。
如果一个节点不可用(发生故障或无法访问),会发生同样的情况。立即进行人为干预就没有必要了。系统会自我修复。要恢复节点,需要使用以下命令重置它:
$ gcloud compute instances reset gke-kubia-default-pool-b46381f1-zwko
当节点再次启动时,其状态应该返回到Ready,并且状态为Unknown的pod将被删除。
1.4 将pod移入或移出ReplicationController的作用域
由ReplicationController创建的pod并不是绑定到ReplicationController。在任何时刻,ReplicationController管理与标签选择器匹配的pod。通过更改pod的标签,可以将它从ReplicationController的作用域中添加或删除。它甚至可以从一个ReplicationController移动到另一个。
提示: 尽管一个pod没有绑定到一个ReplicationController,但该pod在metadata.ownerReferences字段中引用它,可以轻松使用它来找到一个pod属于哪个ReplicationController。
如果你更改了一个pod的标签,使它不再与ReplicationController的标签选择器相匹配,那么该pod就变得和其他手动创建的pod—样了。它不再被任何东西管理。如果运行该节点的pod异常终止,它显然不会被重新调度。但请记住,当你更改pod的标签时,ReplicationController发现一个pod丢失了,并启动一个新的pod替换它。
ReplicationController管理具有app=kubia标签的pod,因此需要删除这个标签或修改其值以将该pod移出ReplicationController的管理范围。添加另一个标签并没有用,因为ReplicationController不关心该pod是否有任何附加标签,它只关心该pod是否具有标签选择器中引用的所有标签。
给ReplicationController管理的pod加标签
需要确认的是,如果你向ReplicationController管理的pod添加其他标签,它并不关心:
$ kubectl label pod kubia-dmdck type=special pod "kubia-dmdck" labeled $ kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS kubia-oini2 1/1 Running 0 11m app=kubia kubia-k0xz6 1/1 Running 0 11m app=kubia kubia-dmdck 1/1 Running 0 1m app=kubia,type=special
给其中一个pod添加了type=special标签,再次列出所有pod会显示和以前一样的三个pod。因为从ReplicationController角度而言,没发生任何更改。
更改已托管的pod的标签
现在,更改app=kubia标签。这将使该pod不再与ReplicationController的标签选择器相匹配,只剩下两个匹配的pod。因此,ReplicationController会启动一个新的pod,将数目恢复为三:
$ kubectl label pod kubia-dmdck app=foo --overwrite pod "kubia-dmdck" labeled
--overwrite参数是必要的,否则kubectl将只打印出警告,并不会更改标签。这样是为了防止你想要添加新标签时无意中更改现有标签的值。再次列出所有pod时会显示四个pod:
$ kubectl get pods -L app NAME READY STATUS RESTARTS AGE APP kubia-2qneh 0/1 ContainerCreating 0 2s kubia #新建的pod,用于替换RC范围中杀出的pod kubia-oini2 1/1 Running 0 20m kubia kubia-k0xz6 1/1 Running 0 20m kubia kubia-dmdck 1/1 Running 0 10m foo #不在由RC管理的pod
现在有四个pod:—个不是ReplicationController管理的,其他三个是。 其中包括新建的pod。
图4.5说明当更改pod的标签,使得它们不再与ReplicationController的pod选择器匹配时,发生的事情。可以看到三个pod和ReplicationController。在将pod的标签从app=kubia更改为app=foo之后,ReplicationController就不管这个pod了。由于控制器的副本个数设置为3,并且只有两个pod与标签选择器匹配,所以ReplicationController启动kubia_2qneh pod,使总数回到了三。kubia-dmdck pod现在是完全独立的,并且会一直运行直到手动删除它(现在可以这样做,因为不再需要它)。

从控制器删除pod
当你想操作特定的pod时,从ReplicationController管理范围中移除pod的操作 很管用。例如,你可能有一个bug导致你的pod在特定时间或特定事件后开始出问题。如果你知道某个pod发生了故障,就可以将它从Replication-Controller的管理范围中移除,让控制器将它替换为新pod,接着这个pod就任你处置了。完成后删除该pod即可。
更改ReplicationController的标签选择器
如果不是更改某个pod的标签而是修改了ReplicationController的标签选择器,你认为会发生什么?
它会让所有的pod脱离ReplicationController的管理,导致它创建三个新的pod.
1.5 修改pod模板
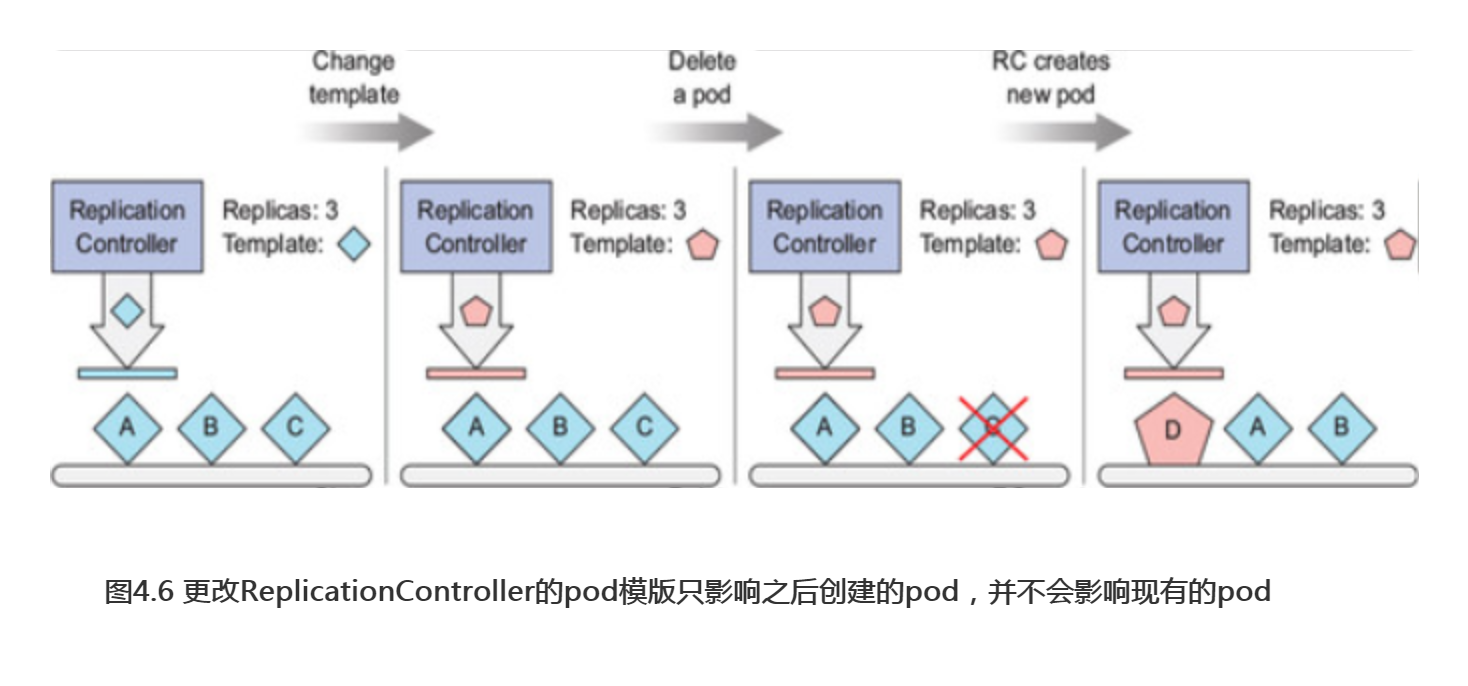
ReplicationController的pod模板可以随时修改。更改pod模板就像用一个曲奇刀替换另一个。它只会影响你之后切出的曲奇,并且不会影响你已经剪切的曲奇(见图4.6)。要修改旧的pod,你需要删除它们,并让ReplicationController根据新模板将其替换为新的pod。
可以试编辑ReplicationController并向pod模板添加标签。使用以下命令编辑ReplicationController:
$ kubectl edit rc kubia
这将在你的默认文本编辑器中打开ReplicationController YAML配置。找到 pod 模板部分并向元数据添加一个新的标签。保存更改并退出编辑器后,kubectl将更新ReplicationController并打印以下消息:
replicationcontroller "kubia" edited
现在可以再次列出pod及其标签,并确认它们未发生变化。但是如果你删除了这个pod并等待其替代pod创建,你会看到新的标签。
像这样编辑一个ReplicationController,来更改容器模板中的容器图像,删除现有的容器,并让它们替换为新模板中的新容器,可以用于升级pod。
1.6 水平缩放pod
可以看到ReplicationController如何确保持续运行的pod实例数量保持不变。 因为改变副本的所需数量非常简单,所以这也意味着水平缩放pod很简单。
放大或者缩pod的数量规模就和在ReplicationController资源中更改Replicas字段的值一样简单。更改之后,ReplicationController将会看到存在太多的pod并删除其中的一部分(缩容时),或者看到它们数目太少并创建pod(扩容时)。
Replicationcontroller扩容
ReplicationController—直保持三个pod实例在运行的状态。现在要把这个数字提高到10。
$ kubectl scale rc kubia --replicas=10
现在用另一种做法
通过编辑定义来缩放ReplicationController
不使用kubectl scale命令,而是通过以声明的形式编辑ReplicationConfroller的定义对其进行缩放:
$ kubectl edit rc kubia
当文本编辑器打开时,找到spec.replicas字段并将其值更改为10,如下面的代码清单所示。
apiVersion: v1 kind: ReplicatinController metadata: ... spec: replicas: 3 #改成10 seelctor: app: kubia
保存该文件并关闭编辑器,ReplicationController会更新并立即将pod数量增加到10:
$ kubectl get rc
NAME DESIRED CURRENT READY AGE
kubia 10 10 4 21m
用kubectl scale命令缩容
现在将副本数目减小到3。可以使用kubectl scale命令:
$ kubectl scale rc kubia --replicas=3
所有这些命令都会修改ReplicationController定义的spec.replicas字段, 就像通过kubectl edit进行更改一样。
伸缩集群的声明式方法
在Kubernetes中水平伸缩pod是陈述式的:“我想要运行x个实例。”你不是告诉Kubernetes做什么或如何去做,只是指定了期望的状态。
这种声明式的方法使得与Kubernetes集群的交互变得容易。设想一下,如果你必须手动确定当前运行的实例数量,然后明确告诉Kubernetes需要再多运行多少个实例的话,工作更多且更容易出错,改变一个简单的数字要容易得多。
1.7 删除一个 ReplicationController
当你通过kubectl delete删除ReplicationController时,pod也会被删除。但是由于由ReplicationController创建的pod不是ReplicationController的组成部分,只是由其进行管理,因此可以只删除ReplicationController并保持pod运行,如图4.7所示。
当你最初拥有一组由ReplicationController管理的pod,然后决定用ReplicaSet(你 接下来会知道)替换ReplicationController时,这就很有用。可以在不影响pod的情况下执行此操作,并在替换管理它们的ReplicationController时保持pod不中断运行。
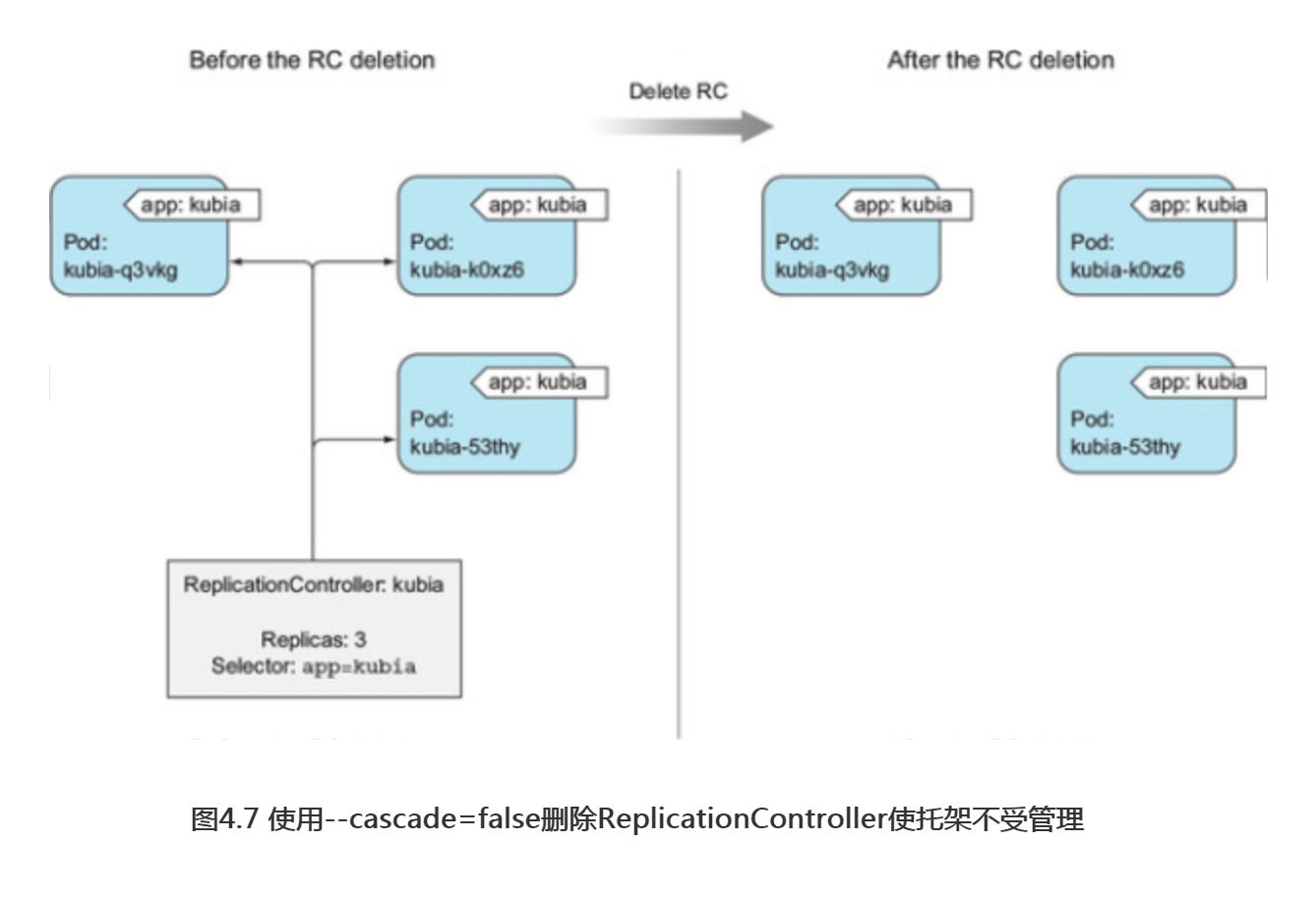
当使用kubectl delete删除ReplicationController时,可以通过给命令增加--cascade=false选项来保持pod的运行。马上试试看:
$ kubectl delete rc kubia --cascade=false replicationcontroller "kubia" deleted
己经删除了 ReplicationController,所以这些pod独立了,它们不再被管理。 但是始终可以使用适当的标签选择器创建新的ReplicationController,并再次将它们管理起来。
2.使用ReplicaSet而不是ReplicationController
最初,ReplicationController是用于复制和在异常时重新调度节点的唯一Kubernetes组件,后来又引入了一个名为ReplicaSet的类似资源。它是新一代的 ReplicationController,并且将其完全替换掉(ReplicationController 最终将被弃用)。
本可以通过创建一个ReplicaSet而不是一个ReplicationController来幵始本章, 但是笔者觉得从Kubernetes最初提供的组件幵始是个好主意。另外,你仍然可以看到使用中的ReplicationController,所以你最好知道它们。也就是说从现在起,你应该始终创建ReplicaSet而不是ReplicationController。它们几乎完全相同,所以你不会碰到任何麻烦。
你通常不会直接创建它们,而是在创建更高层级的Deployment资源时自动创建它们。无论如何,你应该了解ReplicaSet,所以来看看它们与ReplicationController的区别。
2.1 比较 ReplicaSet和Replicationcontroller
ReplicaSet的行为与ReplicationController完全相同,但pod选择器的表达能力更强。虽然ReplicationController的标签选择器只允许包含某个标签的匹配pod,但ReplicaSet的选择器还允许匹配缺少某个标签的pod,或包含特定标签名的pod,不管其值如何。
另外,举个例子,单个ReplicationController无法将pod与标签env=production和env=devel同时匹配。它只能匹配带有env=devel标签的pod或带有env=production标签的pod。但是一个ReplicaSet可以匹配两组pod并将它们视为一个大组。
同样,无论ReplicationController的值如何,ReplicationController都无法仅基于 标签名的存在来匹配pod,而ReplicaSet则可以。例如,ReplicaSet可匹配所有包含名为env的标签的pod,无论ReplicaSet的实际值是什么(可以理解为env=*)。
2.2 定义ReplicaSet
现在要创建一个ReplicaSet,并看看先前由ReplicationController创建稍后又被抛弃的无主pod,现在如何被ReplicaSet管理。首先,创建一个名为kubia-replicaset.yaml的新文件将你的ReplicationController改写为ReplicaSet,其中包含以下代码清单中的内容。
#代码4.8 ReplicaSet的YAML定义: kubia-replicaset.yaml
apiVersion: apps/v1beta2 #不是v1版本的一部分,但属于apps API组的v1beta2版本 kind: ReplicaSet metadata: name: kubia spec: replicas: 3 selector: matchLabels: #这里使用了更简单matchLabels选择器,这非常类似于RC的选择器 app: kubia template: #该模版与RC中的相同 metadata: labels: app: kubia spec: containers: - name: kubia image: luksa/kubia
首先要注意的是ReplicaSet不是v1 API的一部分,因此需要确保在创建资源时指定正确的apiVersion。你正在创建一个类型为ReplicaSet的资源,它的内容与你之前创建的ReplicationControlier的内容大致相同。
唯一的区别在选择器中。不必在selector属性中直接列出pod需要的标签,而是在selector.matchLabels下指定它们。这是在RejlicaSet中定义标签选择器的更简单(也更不具表达力)的方式。之后,你会看到表达力更强的选项。
因为你仍然有三个pod匹配从最初运行的app=kubia选择器,所以创建此ReplicaSet不会触发创建任何新的pod。ReplicaSet将把它现有的三个pod归为自己的管辖范围。
2.3 创建和检查ReplicaSet
使用kubectl create命令根据YAML文件创建ReplicaSet。之后,可以使用kubectl get和kubectl describe来检查ReplicaSet:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
kubia 3 3 3 3s
$ kubectl describe rs Name: kubia Namespace: default Selector: app=kubia Labels: app=kubia Annotations: <none> Replicas: 3 current / 3 desired Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed Pod Template: Labels: app=kubia Containers: ... Volumes: <none> Events: <none>
如你所见,ReplicaSet与ReplicationController没有任何区别。显示有二个与选择器匹配的副本。如果列出所有pod,你会发现它们仍然是你以前的三个pod。ReplicaSet没有创建任何新的pod。
2.4 使用ReplicaSet的更富表达力的标签选择器
ReplicaSet相对于ReplicationController的主要改进是它更具表达力的标签选择器。之前我们故意在第一个ReplicaSet示例中,用较简单的matchLabels选择器来确认ReplicaSet与ReplicationController没有区别。现在,将用更强大的 matchExpressions属性来重写选择器,如下面的代码清单所示。
#代码4.9 一个matchExpressions选择器: kubia-replicaset-matchexpressions.yaml
apiVersion: apps/v1beta2 kind: ReplicaSet metadata: name: kubia spec: replicas: 3 selector: matchExpressions: - key: app #此选择器要求改pod包含名为“app”的标签 operator: In #标签的值必须是“kubia” values: - kubia template: metadata: labels: app: kubia spec: containers: - name: kubia image: luksa/kubia
可以给选择器添加额外的表达式。如示例,每个表达式都必须包含一个key、 一个operator (运算符),并且可能还有一个values的列表(取决于运算符)。你会看到四个有效的运算符:
-
- In: Label的值必须与其中一个指定的values匹配。
- Notin: Label的值与任何指定的values不匹配。
- Exists: pod必须包含一个指定名称的标签(值不重要)。使用此运算符时,不应指定values字段。
- DoesNotExist: pod不得包含有指定名称的标签。values属性不得指定。
如果你指定了多个表达式,则所有这些表达式都必须为true才能使选择器与pod匹配。如果同时指定matchLabels和matchExpressions,则所有标签都必须匹配,并且所有表达式必须计算为true以使该pod与选择器匹配。
2.5 ReplicaSet小结
这是对ReplicaSet的快速介绍,将其作为ReplicationController的替代。请记住,始终使用它而不是ReplicationController,但仍可以在其他人的部署中找到ReplicationController。
现在,删除ReplicaSet以清理集群。可以像删除ReplicationController—样删除ReplicaSet:
$ kubectl delete rs kubia replicaset "kubia" deleted
删除ReplicaSet会删除所有的pod。这种情况下是需要列出pod来确认的。
3.总结
1.不应该直接创建pod,因为如果它们被错误地删除,它们正在运行的节点异常, 或者它们从节点中被逐出时,它们将不会被重新创建。
2.ReplicationController始终保持所需数量的pod副本正在运行。
3.pod不属于ReplicationController,如有必要可以在它们之间移动。
4.ReplicationController将从pod模板创建新的pod。更改模板对现有的pod没有影响。
5.ReplicationController应该替换为ReplicaSet和Deployment,它们提供相同的能力,但具有额外的强大功能。