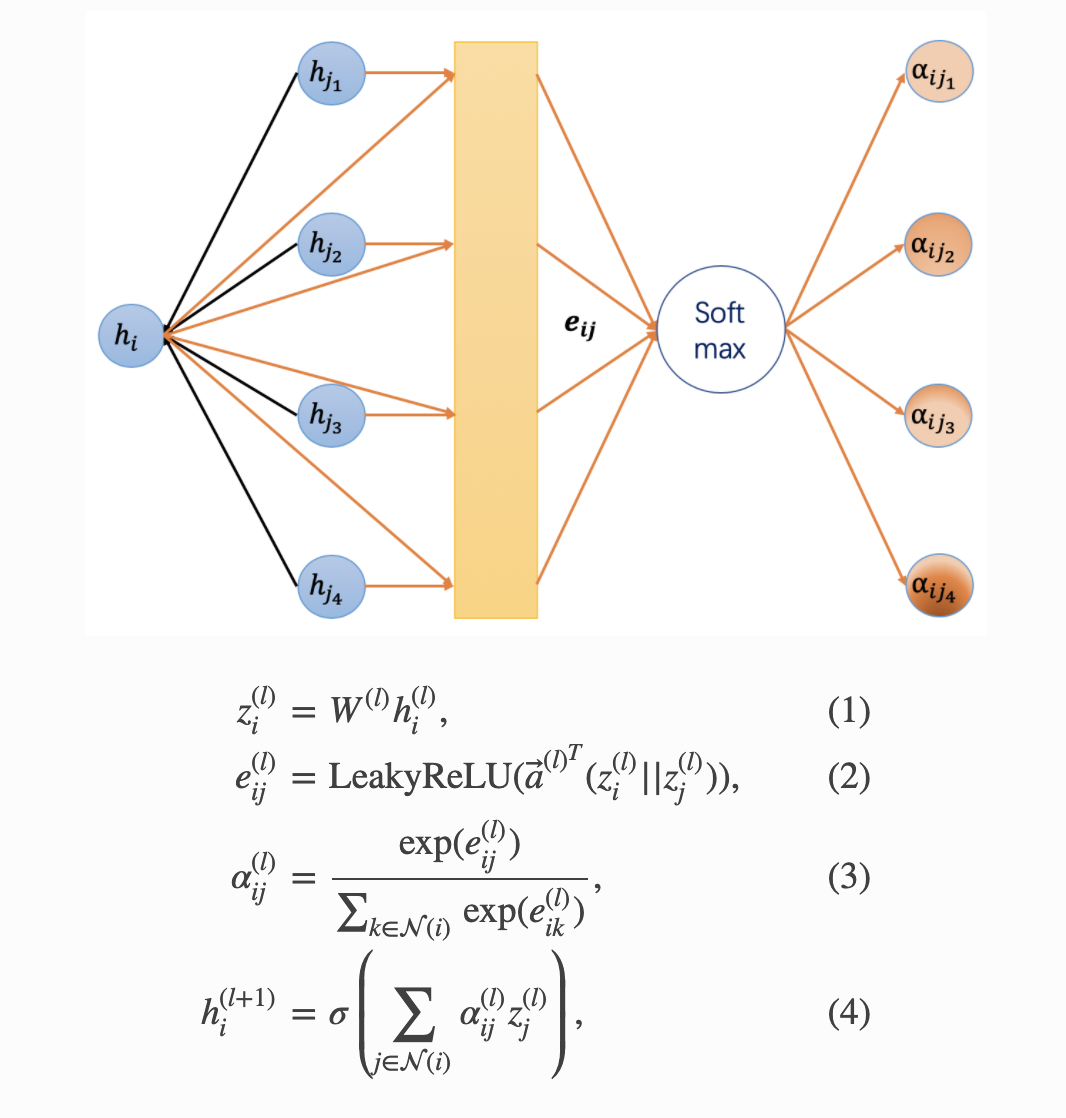
DGL采用attention的方式为节点加权。
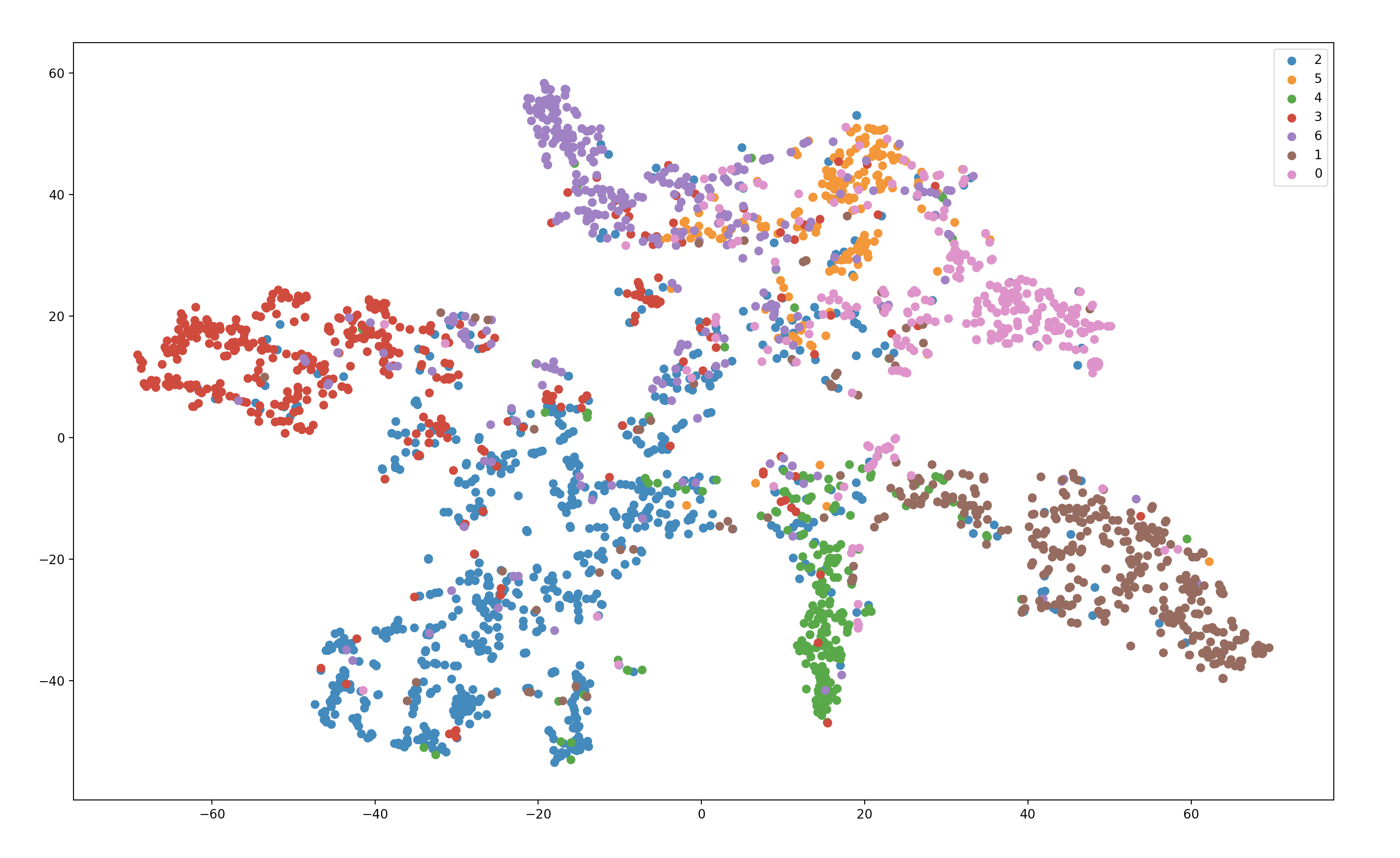
import torch import torch.nn as nn import torch.nn.functional as F from dgl import DGLGraph from dgl.data import citation_graph as citegrh import networkx as nx import numpy as np from sklearn.manifold import TSNE import matplotlib.pyplot as plt from dgl.nn.pytorch import edge_softmax, GATConv class GATLayer(nn.Module): def __init__(self, g, in_dim , out_dim): super(GATLayer, self).__init__() self.g = g self.fc = nn.Linear(in_dim, out_dim, bias=False) self.attn_fc = nn.Linear(2*out_dim, 1, bias=False) self.reset_parameters() def reset_parameters(self): gain = nn.init.calculate_gain('relu') nn.init.xavier_normal_(self.fc.weight, gain=gain) nn.init.xavier_normal_(self.attn_fc.weight, gain=gain) def edge_attention(self, edges): z2 = torch.cat([edges.src['z'], edges.dst['z']], dim=1) a = self.attn_fc(z2) return {'e': F.leaky_relu(a)} def message_func(self,edges): return {'z': edges.src['z'], 'e': edges.data['e']} def reduce_func(self, nodes): alpha = F.softmax(nodes.mailbox['e'], dim=1) # 归一化每一条入边的注意力系数 h = torch.sum(alpha * nodes.mailbox['z'], dim=1) return {'h':h} def forward(self, h): z = self.fc(h) self.g.ndata['z'] = z # 每个节点的特征 self.g.apply_edges(self.edge_attention) # 为每一条边获得其注意力系数 self.g.update_all(self.message_func, self.reduce_func) return self.g.ndata.pop('h') class MultiHeadGATLayer(nn.Module): def __init__(self, g, in_dim , out_dim , num_heads=1, merge='cat'): super(MultiHeadGATLayer, self).__init__() self.heads = nn.ModuleList() for i in range(num_heads): self.heads.append(GATLayer(g, in_dim, out_dim)) self.merge = merge def forward(self, h): head_out = [attn_head(h) for attn_head in self.heads] if self.merge=='cat': return torch.cat(head_out, dim=1) else: return torch.mean(torch.stack(head_out)) class GAT(nn.Module): def __init__(self, g, in_dim, hidden_dim , out_dim, num_heads): super(GAT, self).__init__() self.layer1 = MultiHeadGATLayer(g , in_dim, hidden_dim, num_heads) self.layer2 = MultiHeadGATLayer(g, hidden_dim*num_heads, out_dim, 1) def forward(self, h): h = self.layer1(h) h = F.elu(h) h = self.layer2(h) return h def load_cora_data(): data = citegrh.load_cora() print(data.graph) features = torch.FloatTensor(data.features) labels = torch.LongTensor(data.labels) mask = torch.BoolTensor(data.train_mask) g = DGLGraph(data.graph) return g,features, labels, mask g, features, labels, mask = load_cora_data() net = GAT(g,features.size()[1], hidden_dim=16, out_dim=7, num_heads=2) optimizer = torch.optim.Adam(net.parameters(), lr = 1e-3) dur = [] print(net) for epoch in range(400): logits = net(features) logp = F.log_softmax(logits, 1) loss = F.nll_loss(logp[mask], labels[mask]) optimizer.zero_grad() loss.backward() optimizer.step() print("Epoch {:05d} | Loss {:.4f}".format(epoch, loss.item())) embedding_weights = net(features).detach().numpy() ## 得到所有节点的embedding。 print(embedding_weights[0]) def plot_embeddings(embeddings, X, Y): print(Y) emb_list = [] for k in X: emb_list.append(embeddings[k]) emb_list = np.array(emb_list) model = TSNE(n_components=2) ### 降维 node_pos = model.fit_transform(emb_list) color_idx = {} for i in range(len(X)): color_idx.setdefault(Y[i], []) color_idx[Y[i]].append(i) for c, idx in color_idx.items(): plt.scatter(node_pos[idx, 0], node_pos[idx, 1], label=c) plt.legend() plt.show() plot_embeddings(embedding_weights, np.arange(features.size()[0]), labels.numpy()