一:阿里
1:多线程的工具类
2:threadLocal 类 https://www.zhihu.com/question/23089780
This class provides thread-local variables. These variables differ from their normal counterparts in that each thread that accesses one (via its {@code get} or {@code set} method) has its own, independently initialized copy of the variable. {@code ThreadLocal} instances are typically private static fields in classes that wish to associate state with a thread (e.g., a user ID or Transaction ID).
翻译过来大概是这样的(英文不好,如有更好的翻译,请留言说明):
ThreadLocal类用来提供线程内部的局部变量。这种变量在多线程环境下访问(通过get或set方法访问)时能保证各个线程里的变量相对独立于其他线程内的变量。ThreadLocal实例通常来说都是private static类型的,用于关联线程和线程的上下文。
可以总结为一句话:ThreadLocal的作用是提供线程内的局部变量,这种变量在线程的生命周期内起作用,减少同一个线程内多个函数或者组件之间一些公共变量的传递的复杂度。
Thread 中的ThreadLocalMap是以ThreadLocal<Object>作键,Object作值 ,保存自己线程中 的一些变量,和其它线程没关
TheadLocal 是一个线程内部的数据存储类,通常用于存储以线程为作用域的数据变量,避免产生多线程的同步问题。
3:mysql的隔离级别, 使用共享锁和排它锁,两阶段提交等可以实现隔离级别。
https://blog.csdn.net/starlh35/article/details/76445267
http://blog.sina.com.cn/s/blog_499740cb0100ugs7.html
http://uule.iteye.com/blog/1109647
假设两个事务T1,T2
1:未提交读: 事务T1读取了T2未提交的数据,出现脏读。
2:已提交读:T1只能读取T2提交的数据,解决了脏读。
事务T1读取了一个数据之后,T2修改了该数据,T1再次读取该数据时,会出现T1两次读取数据不一致, 出现不可重复读。
3:可重复读:T1两次读取同一数据时,在这期间不能被其它事务修改,解决了不可重复读。
但是会出现幻读:假设有一张工资表,工资为1000的有10个人。T1执行select操作,查询工资为1000的人的个数为10,T2提交的一组工资为1000的数 据,T1再次查询工资为1000的人的个数为11,出现幻读。
4:可串行化: T1,T2串行执行。
1:读未提交,出现涨读问题,2:读写提交,出现不可重复读问题,3,重复读,出现幻读 问题,4:序列化。
| 隔离级别 | 脏读 | 不可重复读 | 幻象读 | 第一类丢失更新 | 第二类丢失更新 |
| READ UNCOMMITED | 允许 | 允许 | 允许 | 不允许 | 允许 |
| READ COMMITTED | 不允许 | 允许 | 允许 | 不允许 | 允许 |
| REPEATABLE READ | 不允许 | 不允许 | 允许 | 不允许 | 不允许 |
| SERIALIZABLE | 不允许 | 不允许 | 不允许 | 不允许 | 不允许 |
幻读和不可重复读:
不可重复读重点是:update修改,两次读取同一个数据不一致。
幻读是重点是:插入和删除,两次查询到的个数不一致。
4:前台传递多个json
将多个json拼接在一起
5:一个请求都要带哪些参数
6:elasticsearch 实现中英文搜索
7:ik 和其它分词的比较
ik优点:
-
采用了特有的“正向迭代最细粒度切分算法”,具有60万字/秒的高速处理能力。
-
采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
-
优化的词典存储,更小的内存占用。支持用户词典扩展定义。
- 自定义词库效果
-
针对Lucene全文检索优化的查询分析器IKQueryParser,采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
- https://blog.csdn.net/regan_hoo/article/details/78802897
ik缺点:
-
在出现连词时,不是顺序取词,而是取最后的词,如:“流体用”,(词典有‘流体’和‘体用’)本应该分为“流体 | 用”,而IK却分成了“流 | 体用”。
8:vertx 使用的是全异步还是半异步。
9:请求method方法都有哪些
10:做的项目有没有考虑并发。
11:介绍一下CountDownLatch
12:vert.x的io模式
13:使用的是哪一种垃圾回收器 https://blog.csdn.net/earthhour/article/details/76468084
java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=132537600 -XX:MaxHeapSize=2120601600 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
PS Scavenge
PS MarkSweep
垃圾收集算法:
标记清除:将不可达(GC Root set能够到达)(或者引用计数算法)的对象标记,等回收时清除掉。这样堆内的内存是不连续的,当分配内存时使用 “空闲列表” (虚拟机维护一个表,记录哪些内存时可用的)的内存分配方式。 使用标记清除算法的垃圾回收器为 CMS
复制算法:将不可达(或者引用计数算法)的对象标记,将堆内存分为eden去和两个survivor区,其中一个每次将eden区和一个survivor区的对象回收之后,存活的对象复制到另一个survivor区中。 当分配内存时使用指针碰撞(移动指针位置为一个对象的大小)的方式。 使用该算法的垃圾收集器有 serial,parNew等。
标记整理:因为当内存存活率较高时,复制算法比较低效,因此将不可达的对象标记。当进行垃圾回收时,将不可达对象清除,将剩余对象移向一端。
分代收集:因为对象存活的时间不一样,因此将内存区域分为新生代和老年代(当一个对象存活一定代数后,就进入了老年代),新生代回收率高,使用复制算法,老年代回收率低,使用标记清除算法或标记整理算法。
14:jvm都有哪些参数需要设置,https://yq.aliyun.com/articles/49201
1:设置参数:选中主程序,在idea>run>edit configrations>中vm options 对jvm进行参数设置
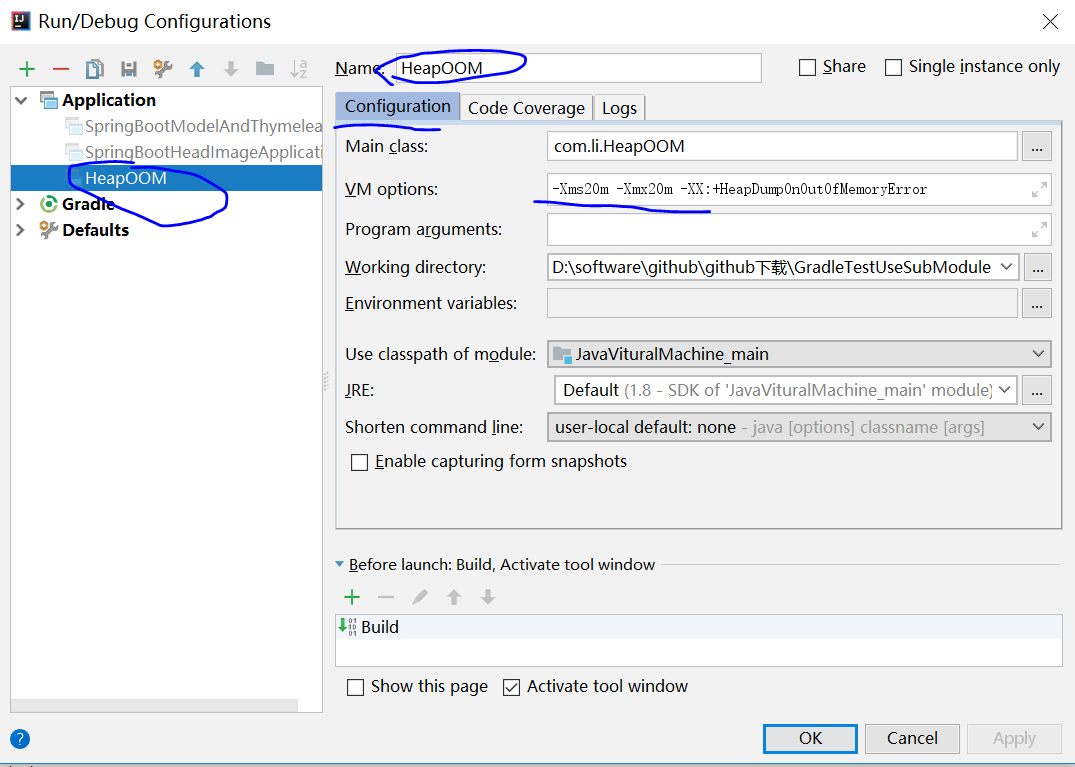
-server 以服务端模式开启jvm -Xms10m 堆初始值 -Xmx10m 堆最大值
-Xss 栈内存 -XX:+DoEscapeAnalysis 启用逃逸分析,方法中未暴露的实例在栈中创建引用,速度会快 -XX:+PrintGC 打印GC日志 -ea
2:java 测试代码:
public class CountDownLatch { public static void main(String[] args){ long timeMillis1 = System.currentTimeMillis(); long maxMemory = Runtime.getRuntime().maxMemory(); System.out.println(maxMemory); long totalMemory = Runtime.getRuntime().totalMemory(); System.out.println(totalMemory); test1(); long timeMillis2 = System.currentTimeMillis(); System.out.println(timeMillis2-timeMillis1); } public static void test1() { byte[] b = new byte[10]; b[0]=1; b[2]=2; } }:
3:测试结果
加载虚拟机,和参数
D:soft7.3.4.winlibhamcrest-core-1.3.jar javaConcurrency.CountDownLatc
[GC (Allocation Failure) 2048K->768K(9728K), 0.0011729 secs]
9961472 9961472 0 Process finished with exit code 0
4:去掉 参数配置,测试。
D:softwar1.3.jar javaConcurrency.CountDownLatch 1886912512 128974848 0 Process finished with exit code 0
-Xmx Java Heap最大值,默认值为物理内存的1/4,最佳设值应该视物理内存大小及计算机内其他内存开销而定;
-Xms Java Heap初始值,Server端JVM最好将-Xms和-Xmx设为相同值,开发测试机JVM可以保留默认值;
-Xmn Java Heap Young区大小,不熟悉最好保留默认值;
-Xss 每个线程的Stack大小,不熟悉最好保留默认值;
15:java的引用类型有哪些,例如:强引用,弱引用等。 http://www.importnew.com/20468.html
四个级别:强应用(有了就不能删)、软引用(当内存不够时,会回收)、弱引用(只能活到下一次回收之前)和虚引用(作为一个标记)
16: b树的范围查询。
https://www.cnblogs.com/vincently/p/4526560.html
- B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
二面:
1:熟悉的排序算法?快速排序的核心?
2:有几种链表
3:linkedList和ArrayList的区别
4:自己总结的有用的经验。
5:redis性能提高了多少倍。
6:动态规划算法的核心。
7:可变变量和小的同步代码块的区别。
8:在一个数组中寻找是否有两个数的和等于某一个整数(三个数的和呢)
9:自己做项目时如何对业务进行分析。
10: 内核态和用户态的区别,什么时候需要由用户态转到内核态。
二: 十一贝
1:介绍一下 rpc
2:linux 后台监控流量工具
3:对项目整个系统的描述
4:solrj
5: ik分词缺点
6:mysql 通信
mysql 通信协议有
Tcp/ip, 网络之间的通信,不同主机之间连接
unix socket, 进程连接,当登入mysql时,需要用到,获得文件位置。
share memory, 一个主机只能有一个server.
https://blog.csdn.net/joson793847469/article/details/52206692
7:lru解释及实现的数据结构
最近最常用,实现数据结构linkedhashmap
8:除了redis ,还有哪些缓存
https://www.cnblogs.com/java-zhao/p/5134819.html
memcached
9:mybatis的原理
10:http服务
11:tcp,ip服务
tcp状态机 https://www.cnblogs.com/qlee/archive/2011/07/12/2104089.html
12:状态码 500异常
13:一个int数组变成string的简单方式
13.1: Arrays.toString
13.2: int[]+""; 转字符串
Java 中怎么打印数组?(answer答案)
你可以使用 Arrays.toString() 和 Arrays.deepToString() 方法来打印数组。由于数组没有实现 toString() 方法,所以如果将数组传递给 System.out.println() 方法,将无法打印出数组的内容,但是 Arrays.toString() 可以打印每个元素。
14: linux下文件分发工具。
rsync
三:sap ,英语介绍.
四,百度电面一面
1:两个 Integer i=4;Integer i=4;是否相等, Integer 与int的区别?
https://blog.csdn.net/login_sonata/article/details/71001851
2:生产者消费者模型,当生产者消费者对队列中的数据共同操作发送冲突时,怎么办。
一个取,一个存,没有冲突。 BlockingQueue 阻塞队列
阻塞队列:可以阻塞等待,阻塞队列提供了可阻塞的put,take方法,以及支持定时的offer和poll方法。如果队列已经满了,那么put方法将阻塞直到有空间可用;如果队列为空,那么take方法将会阻塞直到有元素可用。因此不会冲突。
3:堆,栈,静态区
常量池:常量池是方法区的一部分内存。常量池在编译期间就将一部分数据存放于该区域,包含基本数据类型如int、long等以final声明的常量值,和String字符串、特别注意的是对于方法运行期位于栈中的局部变量String常量的值可以通过 String.intern()方法将该值置入到常量池中。
静态域:位于方法区的一块内存。存放类中以static声明的静态成员变量
4:hashCode相等,equals一定相等?错
equals相等, hashCode一定相等?对
5:final,finally,finallize的区别。
5.1、final修饰符(关键字)。被final修饰的类,就意味着不能再派生出新的子类,不能作为父类而被子类继承。因此一个类不能既被abstract声明,又被final声明。将变量或方法声明为final,可以保证他们在使用的过程中不被修改。被声明为final的变量必须在声明时给出变量的初始值,而在以后的引用中只能读取。被final声明的方法也同样只能使用,不能重载。
5.2、finally是在异常处理时提供finally块来执行任何清除操作。不管有没有异常被抛出、捕获,finally块都会被执行。try块中的内容是在无异常时执行到结束。catch块中的内容,是在try块内容发生catch所声明的异常时,跳转到catch块中执行。finally块则是无论异常是否发生,都会执行finally块的内容,所以在代码逻辑中有需要无论发生什么都必须执行的代码,就可以放在finally块中。
5.3、finalize是方法名。java技术允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。它是在object类中定义的,因此所有的类都继承了它。子类覆盖finalize()方法以整理系统资源或者被执行其他清理工作。finalize()方法是在垃圾收集器删除对象之前对这个对象调用的。
6:tcp三次握手过程中,当服务端给客户端发送确认信号后,会一直等待吗?
https://blog.csdn.net/qiansg123/article/details/80126677
Client发送SYN包给Server后挂了,Server回给Client的SYN-ACK一直没收到Client的ACK确认,此时这个连接既没建立起来,也不能算失败。这就需要一个超时时间让Server将这个连接断开,否则这个连接就会一直占用Server的SYN连接队列中的一个位置,大量这样的连接就会将Server的SYN连接队列耗尽,让正常的连接无法得到处理。目前,Linux下默认会进行5次重发SYN-ACK包,重试的间隔时间从1s开始,下次的重试间隔时间是前一次的双倍,5次的重试时间间隔为1s,2s,4s,8s,16s,总共31s,第5次发出后还要等32s都知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 63s,TCP才会断开这个连接。由于,SYN超时需要63秒,那么就给攻击者一个攻击服务器的机会,攻击者在短时间内发送大量的SYN包给Server(俗称SYN flood攻击),用于耗尽Server的SYN队列。对于应对SYN过多的问题,Linux提供了几个TCP参数:tcp_syncookies、tcp_synack_retries、tcp_max_syn_backlog、tcp_abort_on_overflow来调整应对。
问的问题:以后自己的工作,在开发过程中会用到很多算法吗?
公司自己的框架,工具。在软件领域有哪些领先市场的地方,或者对一些开源的框架,做了哪些改进。比如阿里的druid
使用的框架是公司自己的,还是开源的框架
hr面: 如果有幸被进入到贵公司,请问入职前有哪些需要提前准备的吗
阿里校招一面:
1:redis作分布式缓存和本地缓存的优缺点
本地缓存速度快
https://blog.csdn.net/qq_26562641/article/details/53257800
https://www.cnblogs.com/dumi/p/8660677.html
https://blog.csdn.net/hcmony/article/details/80694560
https://blog.csdn.net/baiyunpeng42/article/details/53694430
https://blog.csdn.net/m15712884682/article/details/55654853
https://www.cnblogs.com/rjzheng/p/9041659.html#!comments
redis有以下优点
1.1 单线程, 不算。
1.2 使用epoll ,只查询有效的。https://blog.csdn.net/shenya1314/article/details/73691088
1.3 数据类型丰富
1.4 设计简单,底层使用数组,用角标查询,memcached使用红黑树。
1.5原子性递增指令 incr
原子性递增实现:多核CPU, 就需要借助上面说道的CPU提供的Lock, 锁住总线. 防止在"读取, 修改, 写入"整个过程期间其他CPU访问内存.
不过Redis事件模型中有一个亮点,我们知道epoll是针对fd(文件描述:File description)的,它返回的就绪事件也是只有fd,Redis里面的fd就是服务器与客户端连接的socket的fd,但是处理的时候,需要根据这个fd找到具体的客户端的信息,怎么找呢?通常的处理方式就是用红黑树将fd与客户端信息保存起来,通过fd查找,效率是lgn。
不过Redis比较特殊,Redis的客户端的数量上限可以设置,即可以知道同一时刻,Redis所打开的fd的上限,而我们知道,进程的fd在同一时刻是不会重复的(fd只有关闭后才能复用),所以Redis使用一个数组,将fd作为数组的下标,数组的元素就是客户端的信息,这样,直接通过fd就能定位客户端信息,查找效率是O(1),还省去了复杂的红黑树的实现(我曾经用c写一个网络服务器,就因为要保持fd和connect对应关系,不想自己写红黑树,然后用了STL里面的set,导致项目变成了c++的,最后项目使用g++编译,这事我不说谁知道?)。显然这种方式只能针对connection数量上限已确定,并且不是太大的网络服务器,像nginx这种http服务器就不适用,nginx就是自己写了红黑树。
1.6 能够持久化
1.7 Redis另一个比Memcached强大的地方,是它支持简单的事务
1.8、Redis的发布订阅频道
1.9 redis使用跳跃表skiplist存储hashtable , 存储形式 【键1,值1,键2,值2,...,】
1.10 将主节点的数据同步到从节点使用的是异步复制,客户端将数据写到主节点,主节点返回客户端成功标志,然后同步数据到从节点。
1.11 通过建立redis集群,实现高可用和大数据量
redis 集群,Redis的集群分片机制,redis存储时会分为16384个hash槽,这些槽会分给这些集群中的节点,例如第一个节点存储1-3000的hash值,这样就可以知道哪个节点保存哪些值。
过期键的判定
通过过期字典,程序可以用以下步骤检查一个给定键是否过期:
1 )检查给定键是否存在于过期字典:如果存在,那么取得键的过期时间。
2 )检查当前UNIX 时间戳是否大于键的过期时间: 如果是的话,那么键已经过期;否则的话,键未过期。
2:有没有用到比较复杂的技术
3:设计数据库时,有没有用到范式之类的。
4:怎么学习一个新知识点的
5 :自己的优势
6:IO和NIO
7:HashMap底层的实现数据结构
8:有没有试着改进过一些框架。
9:JVM内存模型:工作内存和主内存
10: JVM内存分为几部分:堆栈,方法区
11: 分布式开发, 怎么知道多个服务器开发的接口, 对方没有告知。
12:OOP 的理解 https://www.cnblogs.com/xiaosongluffy/p/5072501.html
https://www.cnblogs.com/lanxuezaipiao/archive/2013/06/09/3128665.html
13:HashMap和HashTable有什么区别
主要区别:Hashtable是线程安全的, 同步容器
HashMap不是线程安全的,可以多线程访问。但是不安全
其它:初始容量大小不同,等
14:HashMap底层数据结构:
一个桶结构,每个桶里面是一个链表,链表每个节点是一个Entry