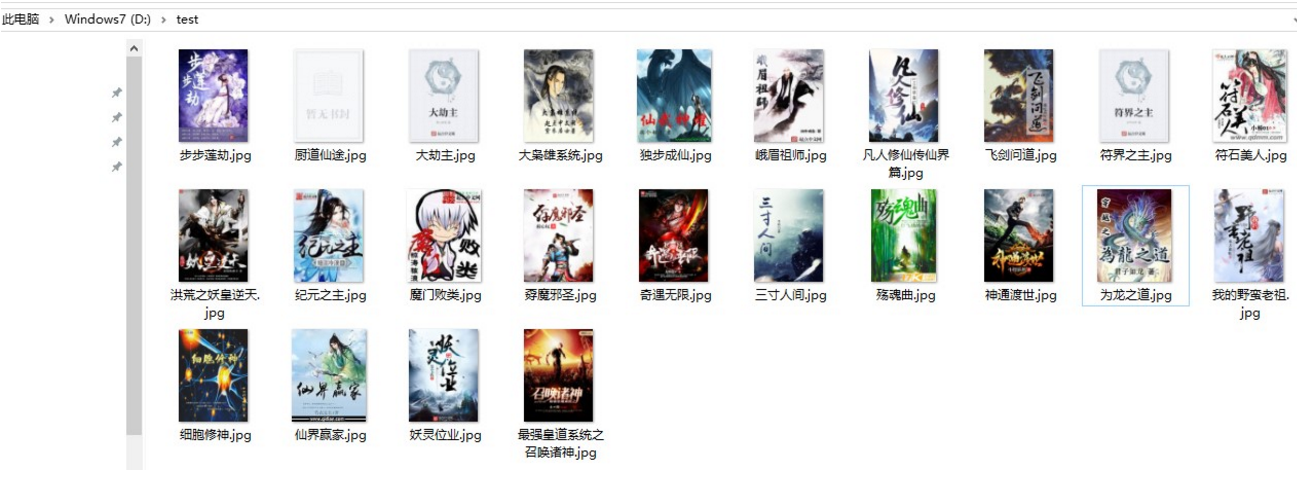
''' 作者:Caric_lee 日期:2018 查看图片 ''' import requests from bs4 import BeautifulSoup r = requests.get("http://www.80txt.com/sort3/1.html") m = r.content.decode("utf-8") tupian = BeautifulSoup(m, "html.parser") all = tupian.find_all("img") print(all) # for i in all: # print(i.a.img) # 取 照片 # 循环把照片连接放到list里面 # tupian1 = BeautifulSoup(m, "html.parser") # all1 = tupian1.find_all("img") # image = [] # for j in all1: # print(j["src"]) # image.append(j["src"]) # print(image) # 把照片连接存储在文件上 for i in all: try: url = i["src"] print(url) name = i["title"] print(name) r1 = requests.get(url) path ="D:\test" # 判断是否存着这个目录 import os if not os.path.exists(path): os.mkdir() fp = open(path + "\%s.jpg" % name, "wb") fp.write(r1.content) # r1.content获取的是二进制流 fp.close() except Exception as msg: print(msg)