GINet: Graph Interaction Network for Scene Parsing
本文探讨了如何通过提出图形交互单元(GI unit)和语义上下文丢失(SC-loss)来整合语言知识,以促进图像区域的上下文推理。
一、Introduction
场景解析是一项基础性和挑战性的任务,它旨在将图像中的每个像素分类为指定的语义类别,包括对象(例如自行车、汽车、人)和东西(例如道路、长凳、天空)。
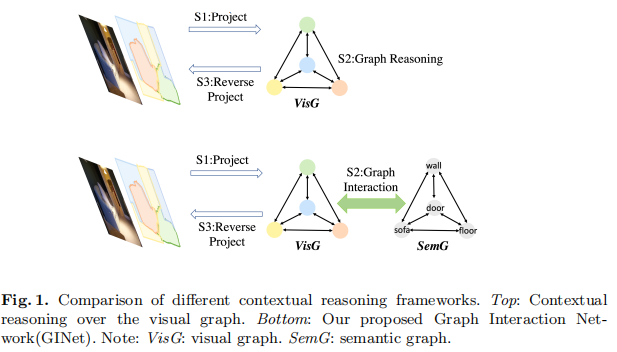
在本文中,我们不单纯地对2D输入图像或视觉特征的视觉图形表示进行上下文推理(如图1的顶部所示),而是寻求结合语言知识,如语言相关性和标签依赖,以共享跨位置的外部语义信息,这些信息可以促进视觉图形上下文推理。我们提出了一个图形交互单元(GI unit),它首先将基于数据集的语言知识集成到视觉图形上的特征表示中,并将视觉图形的演化表示重新投影到每个位置表示中,以增强鉴别能力(如图1的底部所示)。 GI unit显示了视觉和语义图之间的交互。
二、Approach
Framework of Graph Interaction Network (GINet)
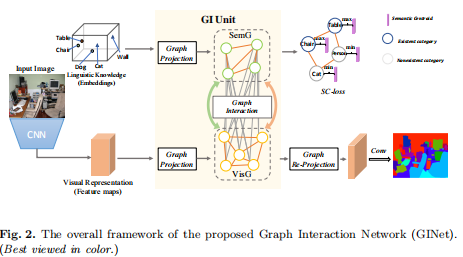
- 首先,我们采用预先训练的ResNet作为backbone network,提取视觉特征。 同时,基于数据集的语言知识可以分类实体(类)的形式提取,并将其输入到word embedding中,以实现语义表示。
- 将视觉特征和文本特征经过graph projection投射到图空间,分别构建两个图VisG和SemG。此时VisG中的节点表示某一区域的视觉特征,边表示不同区域之间的关系。SemG中的节点和边表示经过word embedding后的文本特征和文本间的关系。
- 在GI Unit中进行图交互graph interaction,利用文本图的语义信息指导视觉图的形成。
- 最后,我们使用1×1Conv,然后使用简单的双线性上采样来获得解析结果。
三、Experiments
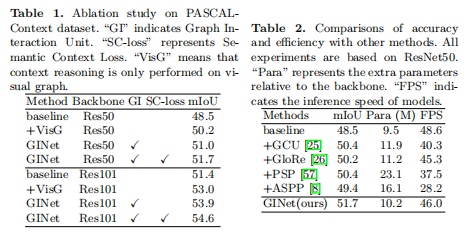
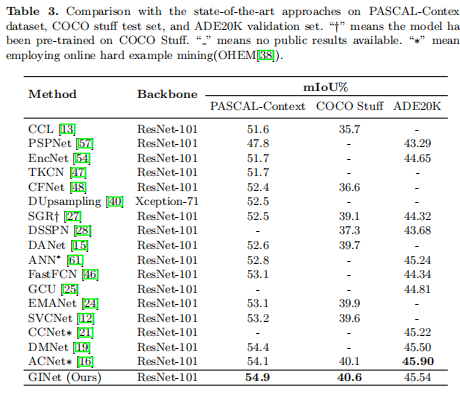
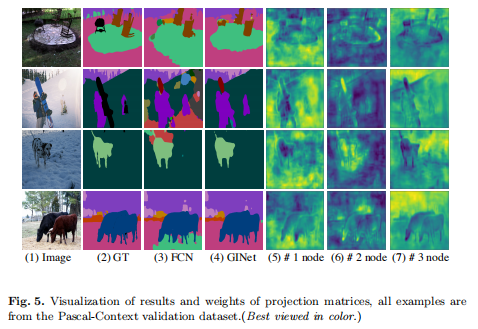
场景解析结果:
四、Conclusion
本文提出了一个图形交互单元,通过结合语义知识来促进视觉图形的上下文推理。 还在图交互单元的语义图输出上开发了语义上下文损失,以强调场景中出现的类别,并抑制那些不出现在场景中的类别。 基于所提出的图形交互单元和语义上下文损失,开发了一个新的框架,称为图形交互网络(GINet)。 基于新框架的拟议方法在两个具有挑战性的场景解析基准(例如Pascal-Context和COCOStuff)上的性能显著提高,从而优于最先进的方法,并在ADE20K数据集上获得了竞争性能。