重点知识归纳
一些重要的符号:
一个点号:. 匹配任意字符,换行符 除外,点 . 就是一个占位符,几个点就占用几个符号。 一个点号 . 代表一个字符 ,匹配任意字符,换行符除外。
一个星号: * 匹配前一个字符零次或者多次。
一个问号:? 匹配前一个字符一次或者零次。(记忆方法:问号表示可选,有或者没有均可,如果有,最多一个。)
点号加星号:.* 贪心算法
点号加星号加问号: .*? 非贪心算法
.?
.?
.*?
.*? 常常用于爬虫中正则表达式匹配。请多留意。
括号:() 括号内的数据作为结果返回。
re.S:re.S 的作用是让 . 的作用包含了换行符 ,这一点我们可以通过看 Python3 的源码得知。
几个重要的方法:
1、findall:返回所有,匹配所有符合规律的内容,返回包含结果的列表
2、search:返回第 1 个,返回并提取第 1 个符合规律的内容,返回一个正则表达式对象
3、sub:替换符合规律的内容,返回替换后的值
例子
代码1:
# . 号的使用
a = 'xy123'
b = re.findall('x.',a)
print(b)
控制台显示:

代码2:
# . 号的使用
a = 'xy123'
b = re.findall('x..',a)
print(b)
控制台显示:

知识点:星号 * ,匹配前一个字符零次或者无限次。
注意:返回的是一个数组。
代码3:
# * 号的使用
a = 'xy123xy'
b = re.findall('x*',a)
print(b)
控制台显示:

代码4:
# * 号的使用
a = 'xxy123'
b = re.findall('x*',a)
print(b)
控制台显示:

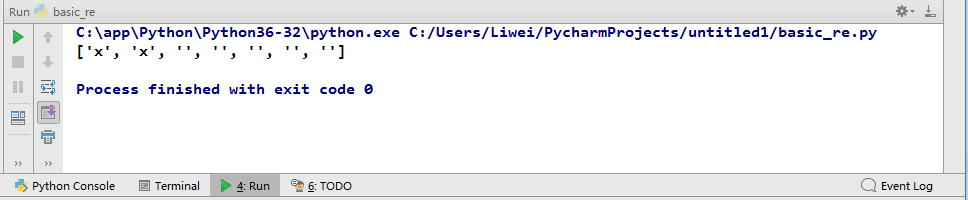
代码5:注意与代码4区分开来
# ? 号的使用
a = 'xxy123'
b = re.findall('x?',a)
print(b)
控制台显示:
上面的内容全部都是只需要了解即可,需要掌握的只有下面这一种组合方式(.?)。
上面的内容全部都是只需要了解即可,需要掌握的只有下面这一种组合方式(.?)。
上面的内容全部都是只需要了解即可,需要掌握的只有下面这一种组合方式(.*?)。
代码6:使用 findall 结合 .* 实现贪心算法
import re
secret_code = 'djdajdaxxIxxdafdsasdsxxlovexxfdsasdsxxpythonxxfsfdsdsddsd'
# .* 号的使用举例,
# 这个符号像一个大胖子,会尽可能地去匹配更多的字符
# 这也叫贪心算法
b = re.findall('xx.*xx',secret_code)
print (b)
控制台显示:

代码7:使用 findall 结合 .*? 实现非贪心算法
import re
secret_code = 'djdajdaxxIxxdafdsasdsxxlovexxfdsasdsxxpythonxxfsfdsdsddsd'
# .*? 号的使用举例,
# 这个符号像一个婴儿,会去匹配较少的字符串
# 这也叫非贪心算法
b = re.findall('xx.*?xx',secret_code)
print (b)
控制台显示:

代码8:下面我们开始使用括号了
import re
secret_code = 'djdajdaxxIxxdafdsasdsxxlovexxfdsasdsxxpythonxxfsfdsdsddsd'
b = re.findall('xx(.*?)xx', secret_code)
print(b)
for each in b:
print(each)
控制台显示:

代码9:
import re
secret_code = '''djdajdaxxI
xxdafdsasdsxxlovexxfdsasdsxxpythonxxfsfdsdsddsd'''
b = re.findall('xx(.*?)xx', secret_code, re.S)
print(b)
for each in b:
print(each)
分析:一个点号(.)代表一个字符 ,匹配任意字符,换行符除外。re.S 表示
控制台显示:

代码6:
secret_code = 'djdajdaxxIxxdafdsasdsxxlovexxfdsasdsxxpythonxxfsfdsdsddsd'
## search 的用法,
## 填 1 显示 I
## 填 2 显示 love
## 填 3 抛出异常
b = re.search('xx(.*?)xxdafdsasdsxx(.*?)xx', secret_code).group(1)
print(b)
代码10:使用 findall 不用 search 和 group
import re
secret_code = 'djdajdaxxIxxdafdsasdsxxlovexxfdsasdsxxpythonxxfsfdsdsddsd'
## search 的用法,
## 填 1 显示 I
## 填 2 显示 love
## 填 3 抛出异常
b = re.findall('xx(.*?)xxdafdsasdsxx(.*?)xx', secret_code)
print(b[0][0])
print(b[0][1])
控制台显示:

代码11: sub 字符串替换的功能
import re
secret_code = 'djdajdaxxIxxdafdsasdsxxlovexxfdsasdsxxpythonxxfsfdsdsddsd'
b = re.sub('xx(.*?)xx','xx%dxx'%123, secret_code)
print(b)
控制台显示:

代码12:
# 匹配纯数字
a= 'fddd1234ddds567gfss89fdd'
b = re.findall('(d+)',a)
print(b)
控制台显示:

一些小技巧
1、如果我们能确定我们要爬取的内容只有一个,就使用 search。
2、先抓大再抓小
3、翻页的功能
#-*-coding:utf-8-*-
import re
old_url = "http://www.jikexueyuan.com/course/android?pageNum=2"
total_page = 20
f = open('text.html','r')
html = f.read()
f.close()
print(html)
title = re.search("<title>(.*?)</title>",html,re.S).group(1)
print("------")
print(title)
print("------")
links = re.findall('href="(.*?)"',html,re.S)
for each_link in links:
print (each_link)
print("------")
text_surround = re.findall("<ul>(.*?)</ul>",html,re.S)[0]
texts = re.findall('">(.*?)</a>',text_surround,re.S)
for each_text in texts:
print (each_text)
print("------")
# 翻页功能
for i in range(2,total_page+1):
new_link = re.sub('?pageNum=d+',"?pageNum=%d"%i,old_url,re.S)
print new_link