当模型的复杂度增大时,训练误差会逐渐减小并趋向于0;而测试误差会先减小,达到最小值后又增大。当选择的模型复杂度过大时,过拟合现象就会发生。这样,在学习时就要防止过拟合。进行最优模型的选择,即选择复杂度适当的模型,以达到使测试误差最小的学习目的。
模型选择的典型方法是正则化。正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项或惩罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。比如,正则化项可以是模型参数向量的范数。
正则化一般具有如下形式:
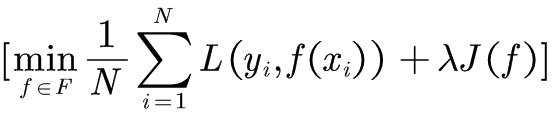 (1.19)
(1.19)
其中,第1项是经验风险,第2项是正则化项,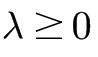 为调整两者之间关系的系数。
为调整两者之间关系的系数。
正则化项可以取不同的形式。
例如,回归问题中,损失函数是平方损失,正则化项可以是参数向量的L2范数:
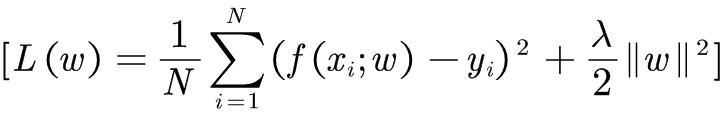
这里,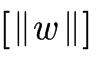 表示参数向量W的L2范数。
表示参数向量W的L2范数。
正则化项也可以是参数向量的L1范数:

这里,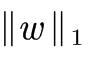 表示参数向量W的L1范数。
表示参数向量W的L1范数。
第1项的经验风险较小的模型可能较复杂(有多个非零参数),这时第2项的模型复杂度会较大。正则化的作用是选择经验风险与模型复杂度同时较小的模型。
来源:
李航著 统计学习方法 清华大学出版社