第四章《串、数组》
(一)串
数据结构中提到的串,即字符串,由 n 个字符组成的一个整体( n >= 0 )。这 n 个字符可以由字母、数字或者其他字符组成。
例如,S = ”BEIJING” ,S 代表这个串的串名,BEIJING 是串的值。
空串:含有零个字符的串。例如:S = “”(双引号中没有任何东西),一般直接用 Ø 表示。
空格串:只包含空格的串。注意和空串区分开,空格串中是有内容的,只不过包含的是空格,且空格串中可以包含多个空格。例如,a = ” ”(包含3个空格)。
子串与主串:串中任意个连续字符组成的字符串叫做该串的子串,包含子串的串称为主串。
两个串相等的标准:如果两个串的串值完全相同,那么这两个串相等。
存储串的结构有三种:
1 定长顺序存储(固定长度的数组(即静态数组)存储串)
例如:char a[7] = "abcdfg";
此方式存储串时,需要预估串的长度提前申请足够的存储空间。目标串如果超过了数组申请的长度,超出部分会被自动舍弃(称为“截断”)。
2 堆分配存储(动态数组存储串)
例如:char * a = (char*)malloc(5*sizeof(char));//创建 a 数组,动态申请5个 char 类型数据的存储空间
使用堆分配存储的优势在于:当发现申请的空间不够用时,可以通过 realloc() 函数重新申请更大的存储空间。
例如:a = (char*)realloc(a, 10*sizeof(char));//前一个参数指申请空间的对象;第二个参数,重新申请空间的大小
使用 malloc 函数申请的存储空间,不会自动释放,需要程序员调用 free() 函数手动释放。如果不手动释放,当程序执行彻底结束,由操作系统进行回收。
例如:free(a);//释放动态数组a申请的空间
3 块链存储(链表的存储结构来存储串)
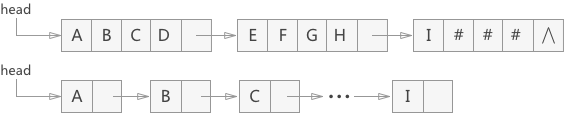
一般情况下使用单链表就足够了,而且不需要增设头结点。
在构建链表时,每个结点可以存放一个字符,也可以存放多个字符。
链表中最后一个结点的数据域不一定全被串值占满,通常会补上 “#” 或者其他特殊的字符和字符串中的字符区分开。
每个结点设置字符数量的多少和存储的串的长度、可以占用的存储空间以及程序实现的功能相关。
如果串包含数据量很大,但是可用的存储空间有限,那么就需要提高空间利用率,相应地减少结点数量(因为多一个节点,就多申请一个指针域的空间)。
而如果程序中需要大量地插入或者删除数据,如果每个节点包含的字符过多,操作字符就会变得很麻烦,为实现功能增加了障碍。
总结:
在平时编写程序,经常会用到例如:char *a = ”abcd”;这种方式表示字符串,和上面三种存储方式最主要的区别是:这种方式用于表示常量字符串,只能使用,不能对字符串内容做修改(否则程序运行出错);而以上三种方式都可以对字符串进行删改的操作。
三种存储表示方式中,最常用的是堆分配存储,因为它在定长存储的基础上通过使用动态数组,避免了在操作串时可能因为申请存储空间的不足而丢失字符数据;和块链存储方式相比,结构相对简单,更容易操作。
串最基本的5个操作:
①串赋值StrAssign /* 生成一个其值等于chars的串T */ Status StrAssign(String T,char *chars) { int i; if(strlen(chars)>MAXSIZE) return ERROR; else { T[0]=strlen(chars); for(i=1;i<=T[0];i++) T[i]=*(chars+i-1); return OK; } } //串赋值的算法比较简单,把目标字符串一个个复制到数组T即可。 //T[i]=*(chars+i-1) 这行代码是关键,字符串可以用指针访问。 ②串比较StrCompare /* 初始条件: 串S和T存在 */ /* 操作结果: 若S>T,则返回值>0;若S=T,则返回值=0;若S < T,则返回值 < 0 */ int StrCompare(String S,String T) { int i; for(i=1; i<=S[0]&&i<=T[0]; ++i) if(S[i]!=T[i]) return S[i]-T[i]; return S[0]-T[0]; } //这里字符串数组的第一个元素存储的是字符串的长度,所以循环条件是 i<=S[0]&&i<=T[0]。 //假如 S[i]与T[i]不相等,就返回它们的差值,根据这个差值我们就可以知道,哪个字符串比较大。 ③求串长 StrLength /* 返回串的元素个数 */ int StrLength(String S) { return S[0]; } //字符串数组的第一个元素存储的就是它的长度,所以直接返回第一个元素就可以了。 ④串联接Concat /* 用T返回S1和S2联接而成的新串。若未截断,则返回TRUE,否则FALSE */ Status Concat(String T,String S1,String S2) { int i; if(S1[0]+S2[0]<=MAXSIZE) { /* 未截断 */ for(i=1;i<=S1[0];i++) T[i]=S1[i]; for(i=1;i<=S2[0];i++) T[S1[0]+i]=S2[i]; T[0]=S1[0]+S2[0]; return TRUE; } else { /* 截断S2 */ for(i=1;i<=S1[0];i++) T[i]=S1[i]; for(i=1;i<=MAXSIZE-S1[0];i++) T[S1[0]+i]=S2[i]; T[0]=MAXSIZE; return FALSE; } } //连接两个串,需要考虑截断问题,判断条件就是 S1[0]+S2[0] 是否大于 MAXSIZE。 //如果未发生截断,则将数组S2的元素补到S1的后边 T[S1[0]+i]=S2[i]; //如果发生截断,那就将MAXSIZE-S1[0]个S2的元素补到S1的后边。 ⑤求子串SubString /* 用Sub返回串S的第pos个字符起长度为len的子串。 */ Status SubString(String Sub,String S,int pos,int len) { int i; if(pos<1||pos>S[0]||len<0||len>S[0]-pos+1) return ERROR; for(i=1;i<=len;i++) Sub[i]=S[pos+i-1]; Sub[0]=len; return OK; } //这里需要注意条件,起始位置不能小于1,也不能大于串长度,长度len不能小于0,也不能大于总长度减去起始位置等。接下来就简单了,从起始位置开始,将串数组元素逐个赋值给sub数组。
串的模式匹配
判断两个串之间是否存在主串与子串的关系,这个过程称为串的模式匹配。
在串的模式匹配过程,子串 T 通常被叫做“模式串”。
<1> 普通的模式匹配(“BF”算法)
算法思想:拿着模式串,去和主串从头到尾一一比对
将提供的模式串(例如 “ABABABB” )从主串的第一个字符开始,依次判断相同位置的字符是否相等,如果全部相等,则匹配成功;反之,将子串向后移动一个字符的位置,继续与主串中对应的字符匹配。
算法运行过程:(图中,i 和 j 表示匹配字符在数组中的位置下标)


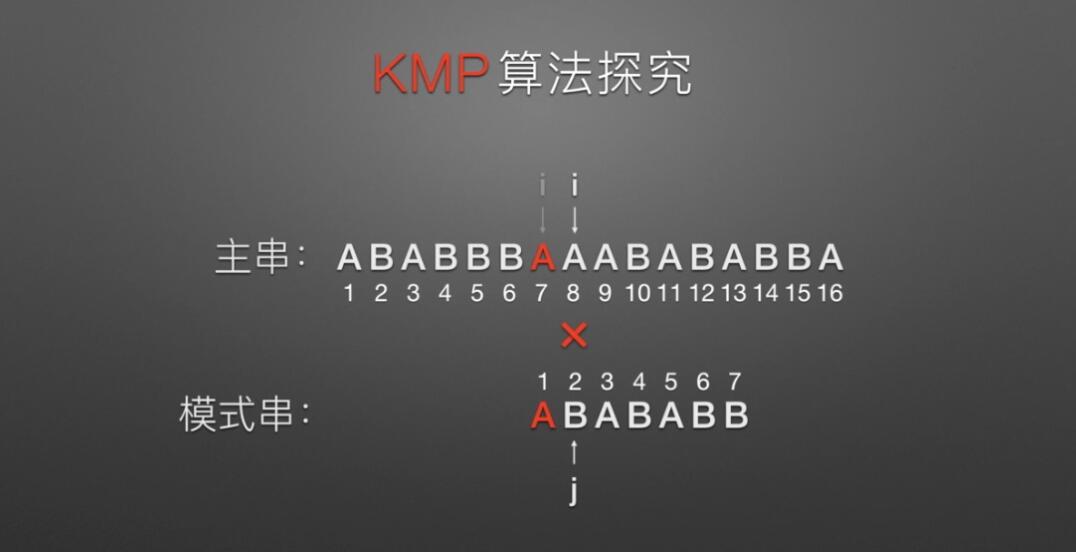

int index(Str str,Str substr) { int i=1,j=1,k=i; //i主串,j子串 while(i<=str.length && j<=substr.length) //若i小于str主串长度且j小于substr子串长度时循环 { if(str.ch[i]==substr.ch[j]) //两字母相等时继续 { i++; j++; } else { j=1; //j退回子串T的首位 i=++k; //i退回上次匹配位置的下一位(k记录了上一次的起始位置) } } if(j>substr.length) //j大于substr子串长度时,匹配成功 return k; else return 0; }
算法的时间复杂度:
“BF” 算法在最理想的情况下的时间复杂度为O(m)( m 是模式串的长度,也就是第一次匹配就成功的情况)。
一般情况下,"BF"算法的时间复杂度为O(n+m)(n是主串的长度,m是模式串的长度)。
最坏的情况下的时间复杂度为O(n*m)(例如主串 S 为“000000000001”,模式串 T ”001”,每次匹配时,直到匹配最后一个元素,才得知匹配失败,运行了 n*m 次)。
“BF”算法在进行模式匹配时,从主串的第一个字符开始,每次失败,模式串向后移动一个字符的位置,继续匹配,无脑式操作。但是整个算法受测试数据的影响非常大,在解决实际问题时,由于数据量庞大,时间复杂度往往会很高。







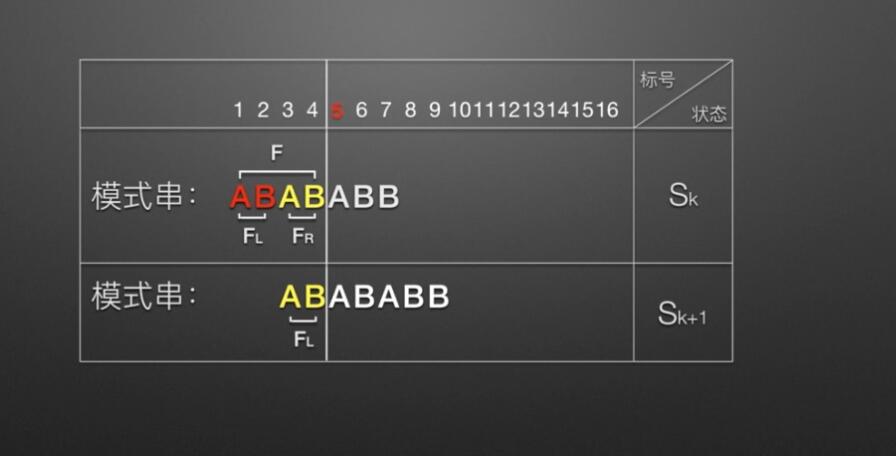






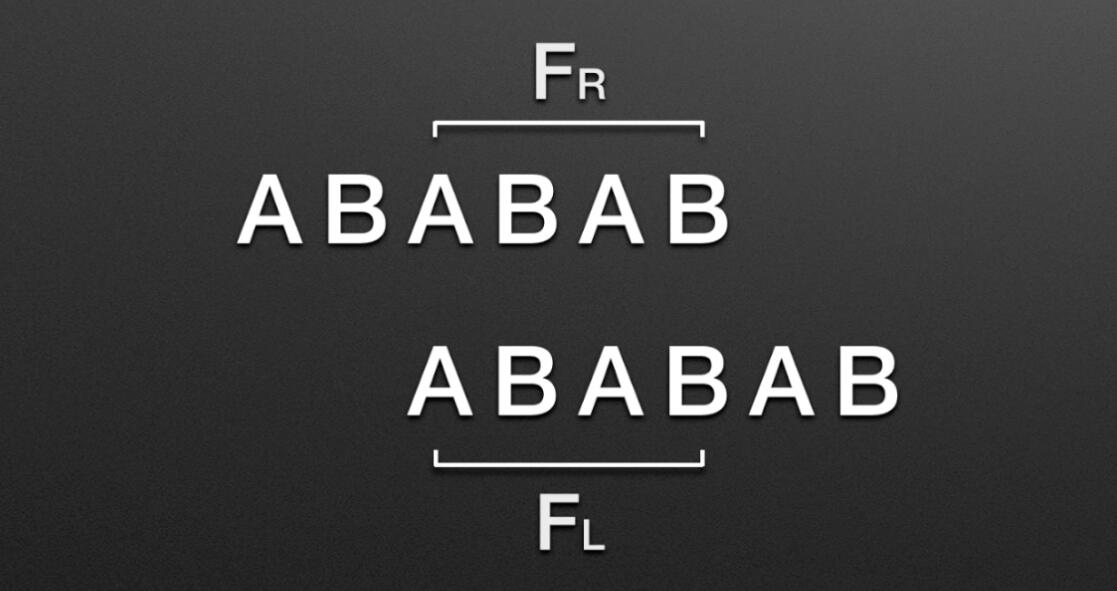
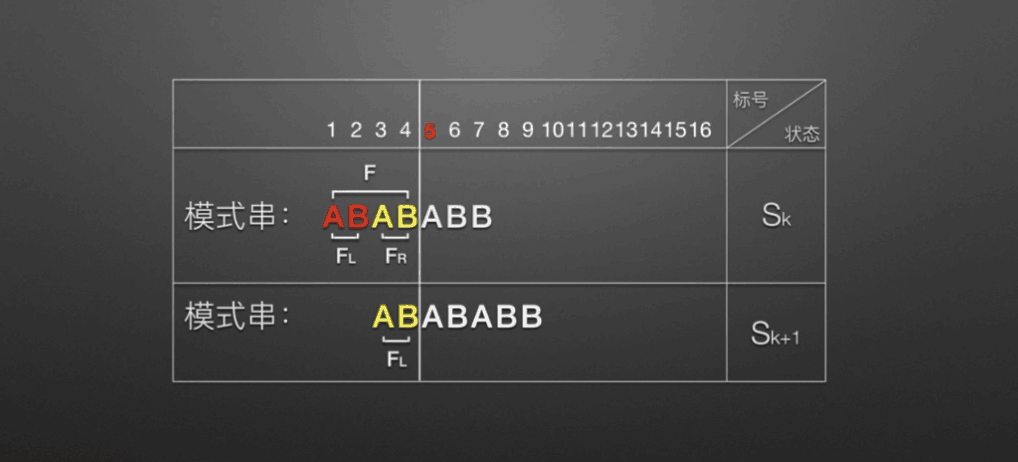
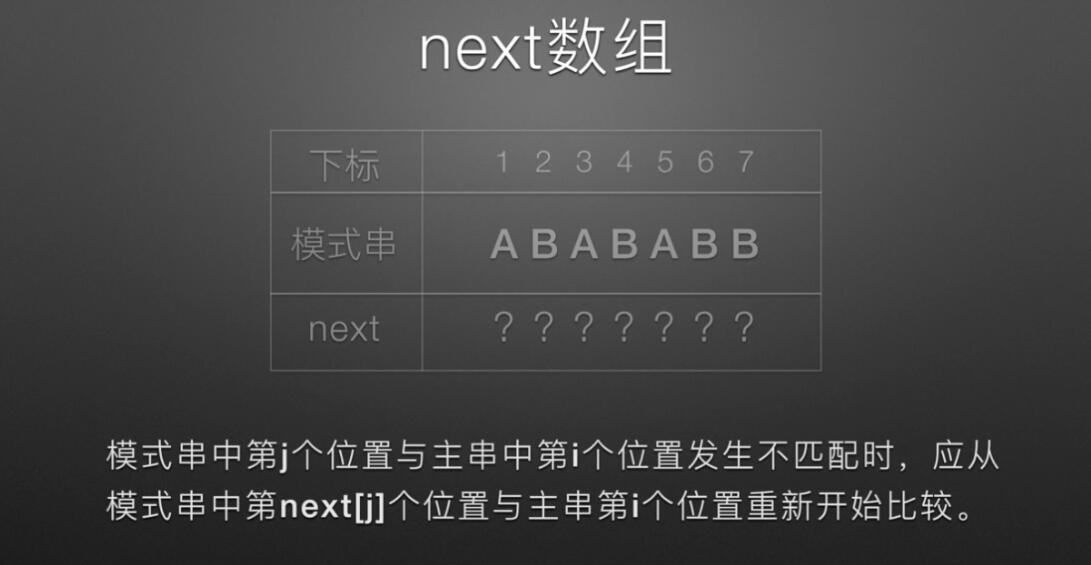












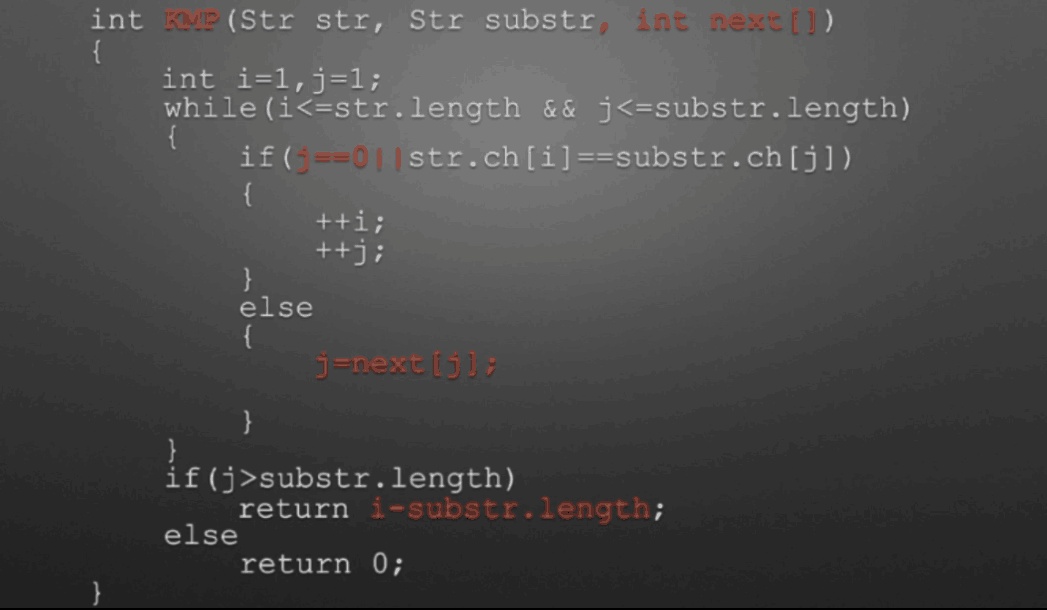




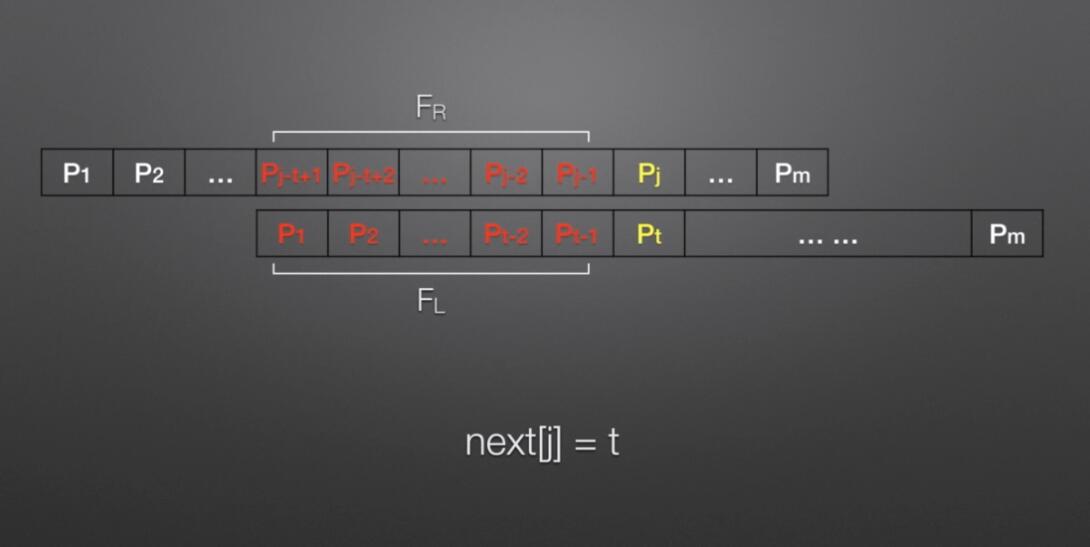




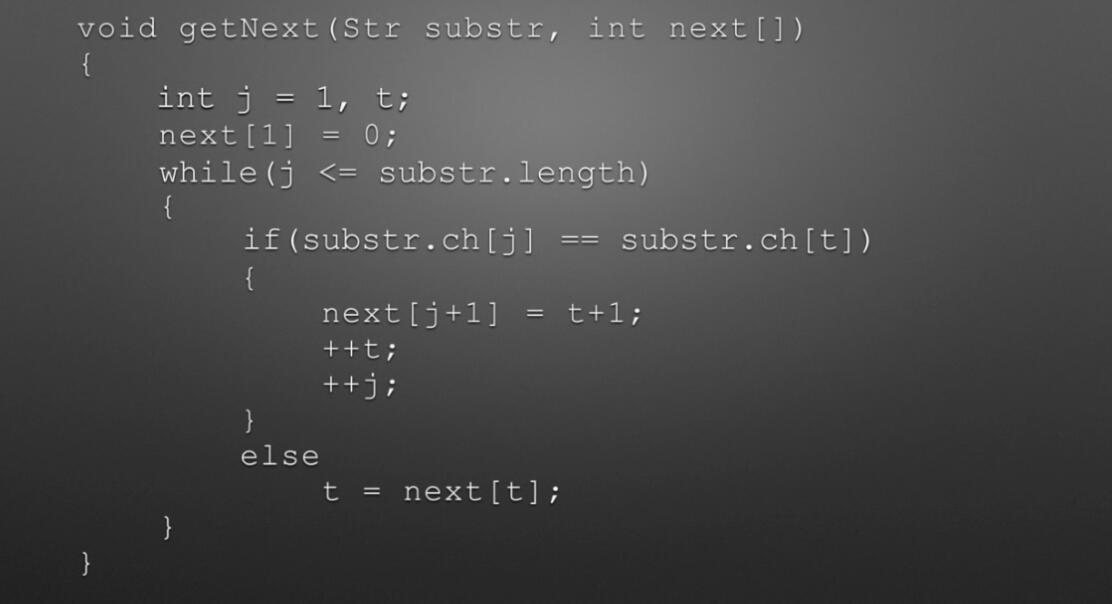

void getNext(Str substr,int next[]) // next数组代码 { int j=1,t=0; next[1]=0; while(j<substr.length) { if(t==0 || substr.ch[j]==substr.ch[t]) { next[j+1]=t+1; ++t; ++j; } else t=next[t]; } } int KMP(Str str,Str substr,int next[]) // KMM主体代码 { int i=1,j=1; while(i<=str.length && j<=substr.length) { if(j==0 || str.ch[i]==substr.ch[j]) //(两字母相等)或(next[j]=0即j=next[j]=0)时继续 { i++; j++; } else { j=next[j]; //把next数组下标赋值给j,即从数组下标位置开始匹配 } } if(j>substr.length) return i-substr.length; //返回的位置为匹配成功的开始位置,i为匹配成功的末尾位置,substr.length为模式串长度 else return 0; }
第一次改进KPM算法:








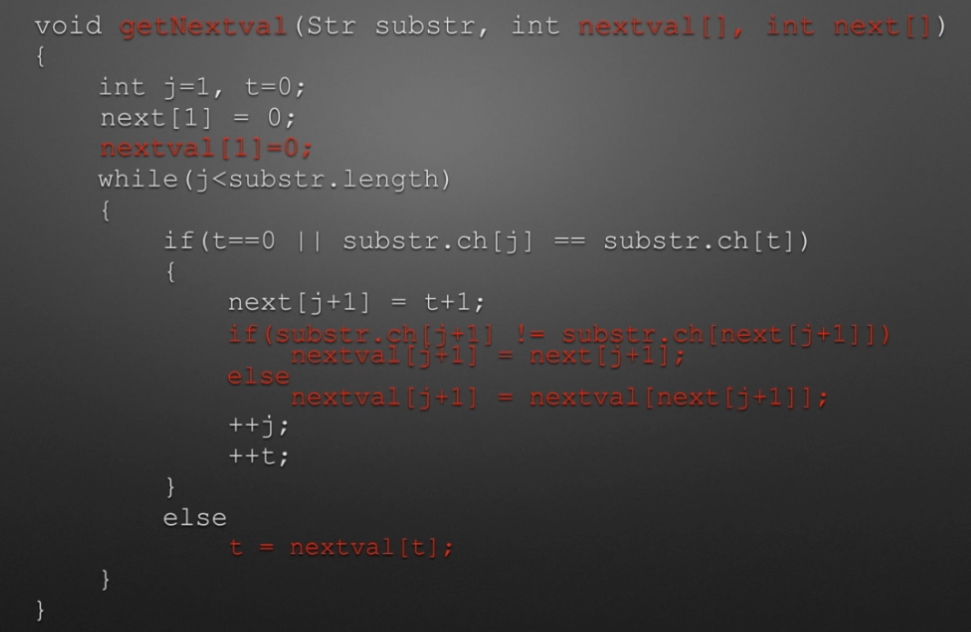
void getnextval(Str substr,int nextval[]) // next数组代码 { int j=1,t=0; nextval[1]=0; while(j<substr.length) { if(t==0 || substr.ch[j]==substr.ch[t]) { //next[j+1]=t+1; ++t; ++j; if(substr.ch[j]!=substr.ch[t]) nextval[i]=t; else nextval[i]=nextval[t]; } else t=nextval[t]; } }
第二次改进KMP算法:
① KMP的不足之处
如果模式串出现在主串靠后的位置甚至不存在的时候,KMP算法实在显得比较低效。
② KMP的改进思想
从主串的首和尾同时进行匹配;当 m >>n,,n>>0的时候(m为主串长度,n为子串长度),并且子串并没有在主串中出现的话,通过剩下的字符数,来判断是否存在足够的字符与子串匹配,如果不足的话,那样就不存在,否则就继续匹配下去。
③ 有哪种方案可以实现从主串末尾向串头开始匹配?
第一个方案:把子串逆转,然后沿用旧的KMP算法中的next函数求出其逆转后的子串的next值,再用以进行匹配;
第二个方案:不需要把子串逆转,而是采用一个新的next函数直接求出其逆转后的next值。
④ 选择哪种方案?
我们选择第二个方案。因为,在 n>>0的时候,明显地,在把子串逆转的时候同时需要多一个字符串来存放,并且,在不同的匹配都需要一个新的字符串,这样就大大地浪费空间了,除此之外,第一个方案至少要做遍历子串两次,而第二个方案只需要遍历子串一次就可以了。
⑤ 实现方案
把末字符看成是首字符,然后,仿照KMP算法中的next函数的实现方式最终实现的。