1.1概述
给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。这就是解释器模式的定义。
对于某些问题,我们可能希望用简单的语言来描述,即希望用简单的语言来实现一些操作,比如用简单语言实现简单的翻译操作,用户输入Teacher drink water,程序输出“老师喝水”。学习使用解释器模式需要用到一些形式语言的知识,和编译原理课程中相关知识点比较接近,个人觉得编译原理中相关理论知识比较晦涩,在此处就不继续往下细究具体原理,有兴趣的同学可以去看一看编译原理的教材。
例如,一个语言一旦有了语句,就可以让程序根据语句进行某种操作。定义一个简单语言,如果使用程序实现该语言时,定义的基本操作是将终结符号的值翻译为汉语,如Teacher翻译为“老师”、Tiger翻译为“老虎”,那么当用户使用该语言输入“Teacher drink water”后,程序输出“老师喝水”。
1.2模式的结构
解释器模式包括以下四种角色:
(1)抽象表达式(AbstractExpression):该角色是一个接口,负责定义抽象的解释操作。
(2)终结符表达式(TerminalExpression):实现AbstractExpression接口的类。该类将接口中的解释操作实现为与文法中的终结符相关联的操作,即文法中每个终结符号需要一个TerminalExpression类。
(3)非终结符表达式(NonterminalExpression):实现AbstractExpression接口的类。文法中的每一条规则都需要一个NonterminalExpression类。NonterminalExpression类为文法中的非终结符号实现解释操作,该解释操作通常使用递归调用表示文法规则中的那些对象的解释操作。
(4)上下文(Context):包含解释器之外的一些全局信息。
解释器模式结构的类图如下图所示:
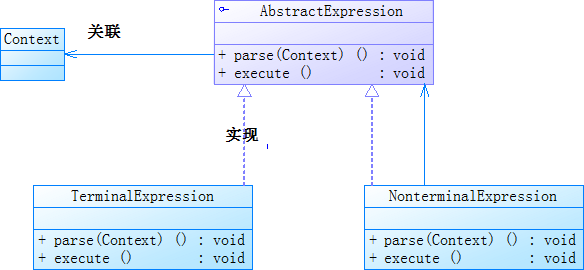
图一:解释器模式的类图(PS:类图画的不标准,此处仅作参考哦)
1.3解释器模式的优点
(1)将每一个语法规则表示成一个类,方便于实现简单的语言。
(2)由于使用类表示语法规则,可以教容易改变或扩展语言的行为。
(3)通过在类结构中加入新的方法,可以在解释的同时增加新的行为。
1.4适合使用解释器模式的情景
(1)当有一个简单的语言需要解释执行,并且可以将该语言的每一个规则表示为一个类时,就可以使用解释器模式。
1.5解释器模式的使用
使用解释器模式实现一个简单的英文翻译器,以下是示例中所要描述的文法:
<Sentence>::=<Subject><Project>
<Predicate>::=<Verb><Object>
<Subject>::=<SubjectPronoun>|<Noun>
<Object>::=<ObjectPronoun>|<Noun>
<SubjectPronoun>::=You|He...|She
<ObjectPronoun>::=Me|You|Him..|Them
<Noun>::=Teacher|gStudent|Tiger...|Water
<Verb>::=Drink|Instruct...|Receive
对于上述定义的简单语言,如果使用程序实现该语言时,定义的基本操作是将终结符号的值翻译为汉语,比如,Teacher翻译为“老师”,Drink翻译为“喝”,Water翻译为“水”。那么当用户使用该语言输入语句“Teacher Drink Water”后,程序将输出“老师喝水”。
首先看一下本实例构建框架具体类和1.2模式的结构中类图的对应关系,如下图所示:
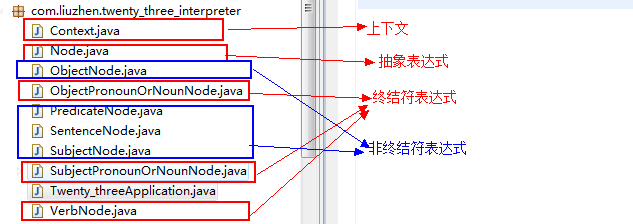
(1)抽象表达式(AbstractExpression)
本问题中,抽象表达式是Node接口,代码如下:
package com.liuzhen.twenty_three_interpreter; public interface Node { public void parse(Context text); public void execute(); }
(2)终结符表达式(TerminalExpression)
文法中共有四个语言单位,分别是<SubjectPronoun>、<ObjectPronoun>、<Noun>和<Verb>。共有四个终结表达式类。由于<Subject>与<SubjectPronoun>和<Noun>之间的关系是“或”关系,因此,针对<SubjectPronoun>和<Noun>语言单位的类是同一个类SubjectPronounOrNounNode。针对<Verb>语言单位的类是VerbNode。各个类的代码如下:
SubjectPronounOrNounNode类:
package com.liuzhen.twenty_three_interpreter; public class SubjectPronounOrNounNode implements Node{ String[] word = {"You","He","Teacher","Student"}; String token; boolean boo; public void parse(Context context){ token = context.nextToken(); int i = 0; for(i = 0;i < word.length;i++){ if(token.equalsIgnoreCase(word[i])){ boo = true; break; } } if(i == word.length) boo = false; } public void execute(){ if(boo){ if(token.equalsIgnoreCase(word[0])) System.out.print("你"); if(token.equalsIgnoreCase(word[1])) System.out.print("他"); if(token.equalsIgnoreCase(word[2])) System.out.print("老师"); if(token.equalsIgnoreCase(word[3])) System.out.print("学生"); } else{ System.out.print(token+"(不是该语言中的语句)"); } } }
ObjectPronounOrNounNode类:
package com.liuzhen.twenty_three_interpreter; public class ObjectPronounOrNounNode implements Node { String[] word = {"Me","Him","Tiger","Apple"}; String token; boolean boo; public void parse(Context context){ token = context.nextToken(); int i = 0; for(i = 0;i < word.length;i++){ if(token.equalsIgnoreCase(word[i])){ boo = true; break; } } if(i == word.length) boo = false; } public void execute() { if(boo){ if(token.equalsIgnoreCase(word[0])) System.out.print("我"); if(token.equalsIgnoreCase(word[1])) System.out.print("他"); if(token.equalsIgnoreCase(word[2])) System.out.print("老虎"); if(token.equalsIgnoreCase(word[3])) System.out.print("苹果"); } else{ System.out.print(token+"(不是该语言中的语句)"); } } }
VerbNode类:
package com.liuzhen.twenty_three_interpreter; public class VerbNode implements Node{ String[] word = {"Drink","Eat","Look","beat"}; String token; boolean boo; public void parse(Context context){ token = context.nextToken(); int i = 0; for(i = 0;i < word.length;i++){ if(token.equalsIgnoreCase(word[i])){ boo = true; break; } } if(i == word.length) boo = false; } public void execute() { if(boo){ if(token.equalsIgnoreCase(word[0])) System.out.print("喝"); if(token.equalsIgnoreCase(word[1])) System.out.print("吃"); if(token.equalsIgnoreCase(word[2])) System.out.print("看"); if(token.equalsIgnoreCase(word[3])) System.out.print("打"); } else{ System.out.print(token+"(不是该语言中的语句)"); } } }
(3)非终结符表达式(NonterminalExpression)
针对给出的文法,共有四个非终结符表达式类。针对<Sentence>语言单位的类是SentenceNode,针对<Subject>语言单位的类是SubjectNode,针对<Predicate>语言单位的类是PredicateNode,针对<Object语言单位的类是ObjectNode。各个类的代码如下:
SentenceNode类:
package com.liuzhen.twenty_three_interpreter; public class SentenceNode implements Node { Node subjectNode,predicateNode; public void parse(Context context){ subjectNode = new SubjectNode(); predicateNode = new PredicateNode(); subjectNode.parse(context); predicateNode.parse(context); } public void execute() { subjectNode.execute(); predicateNode.execute(); } }
SubjectNode类:
package com.liuzhen.twenty_three_interpreter; public class SubjectNode implements Node { Node node; public void parse(Context context){ node = new SubjectPronounOrNounNode(); node.parse(context); } public void execute() { node.execute(); } }
PredicateNode类:
package com.liuzhen.twenty_three_interpreter; public class PredicateNode implements Node { Node verbNode,objectNode; public void parse(Context context){ verbNode = new VerbNode(); objectNode = new ObjectNode(); verbNode.parse(context); objectNode.parse(context); } public void execute() { verbNode.execute(); objectNode.execute(); } }
ObjectNode类:
package com.liuzhen.twenty_three_interpreter; public class ObjectNode implements Node { Node node; public void parse(Context context){ node = new ObjectPronounOrNounNode(); node.parse(context); } public void execute() { node.execute(); } }
(4)上下文(Context)
上下文(Context)角色是Context类,代码如下:
package com.liuzhen.twenty_three_interpreter; import java.util.StringTokenizer; public class Context { StringTokenizer tokenizer; String token; public Context(String text){ setContext(text); } public void setContext(String text){ tokenizer = new StringTokenizer(text); } String nextToken(){ if(tokenizer.hasMoreTokens()) token = tokenizer.nextToken(); else token = ""; return token; } }
(5)具体应用
通过Twenty_threeApplication类来具体实现上述相关类和接口,来实现解释器模式的运用,其代码如下:
package com.liuzhen.twenty_three_interpreter; public class Twenty_threeApplication { public static void main(String[] args){ String text = "He beat tiger"; Context context = new Context(text); Node node = new SentenceNode(); node.parse(context); node.execute(); text = "You eat apple"; context.setContext(text); System.out.println(); node.parse(context); node.execute(); } }
运行结果:
他打老虎
你吃苹果
参考资料:
1.Java设计模式/耿祥义,张跃平著.——北京:清华大学出版社,2009.5