1. wordcount示例开发
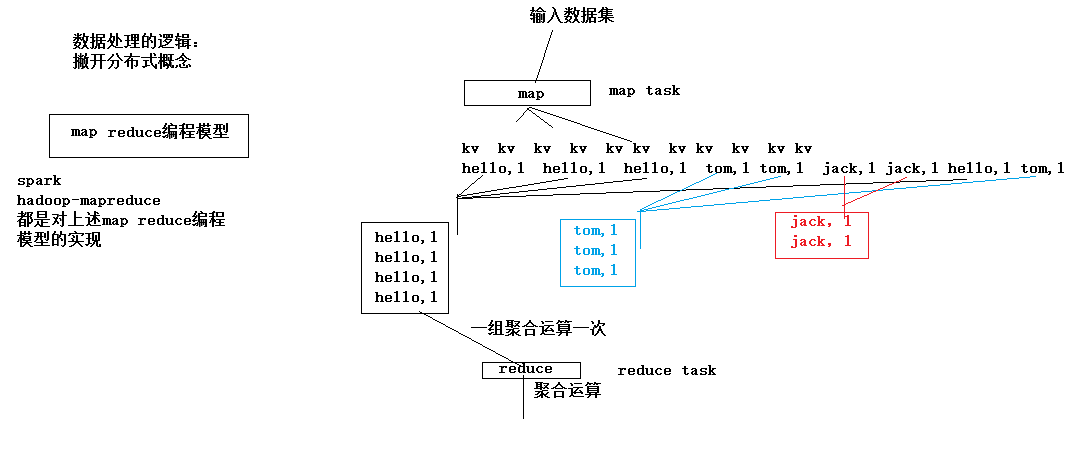
1.1. wordcount程序整体运行流程示意图
map阶段: 将每一行文本数据变成<单词,1>这样的kv数据
reduce阶段:将相同单词的一组kv数据进行聚合:累加所有的v
注意点:mapreduce程序中,
map阶段的进、出数据,
reduce阶段的进、出数据,
类型都应该是实现了HADOOP序列化框架的类型,如:
String对应Text
Integer对应IntWritable
Long对应LongWritable
1.2. 编码实现
WordcountMapper类开发
WordcountReducer类开发
JobSubmitter客户端类开发
《详见代码》
1.3. 运行mr程序
1) 将工程整体打成一个jar包并上传到linux机器上,
2) 准备好要处理的数据文件放到hdfs的指定目录中
3) 用命令启动jar包中的Jobsubmitter,让它去提交jar包给yarn来运行其中的mapreduce程序 : hadoop jar wc.jar cn.edu360.mr.wordcount.JobSubmitter .....
4) 去hdfs的输出目录中查看结果
1.4. mr程序运行模式
mr程序的运行方式:
1、yarn
2、本地(windows linux)
决定以哪种模式运行的
1 package mr.flow; 2 3 import java.io.DataInput; 4 5 6 import java.io.DataOutput; 7 import java.io.IOException; 8 9 import org.apache.hadoop.io.Writable; 10 11 public class FlowBean implements Writable,Comparable<FlowBean> { 12 13 private int upFlow; 14 private int dFlow; 15 private String phone; 16 private int amountFlow; 17 18 public FlowBean(){} 19 20 public FlowBean(String phone, int upFlow, int dFlow) { 21 this.phone = phone; 22 this.upFlow = upFlow; 23 this.dFlow = dFlow; 24 this.amountFlow = upFlow + dFlow; 25 } 26 27 public String getPhone() { 28 return phone; 29 } 30 31 public void setPhone(String phone) { 32 this.phone = phone; 33 } 34 35 public int getUpFlow() { 36 return upFlow; 37 } 38 39 public void setUpFlow(int upFlow) { 40 this.upFlow = upFlow; 41 } 42 43 public int getdFlow() { 44 return dFlow; 45 } 46 47 public void setdFlow(int dFlow) { 48 this.dFlow = dFlow; 49 } 50 51 public int getAmountFlow() { 52 return amountFlow; 53 } 54 55 public void setAmountFlow(int amountFlow) { 56 this.amountFlow = amountFlow; 57 } 58 59 /** 60 * hadoop系统在序列化该类的对象时要调用的方法 61 */ 62 @Override 63 public void write(DataOutput out) throws IOException { 64 65 out.writeInt(upFlow); 66 out.writeUTF(phone); 67 out.writeInt(dFlow); 68 out.writeInt(amountFlow); 69 70 } 71 72 /** 73 * hadoop系统在反序列化该类的对象时要调用的方法 74 */ 75 @Override 76 public void readFields(DataInput in) throws IOException { 77 this.upFlow = in.readInt(); 78 this.phone = in.readUTF(); 79 this.dFlow = in.readInt(); 80 this.amountFlow = in.readInt(); 81 } 82 83 @Override 84 public String toString() { 85 86 return this.phone + ","+this.upFlow +","+ this.dFlow +"," + this.amountFlow; 87 } 88 89 @Override 90 public int compareTo(FlowBean o) { 91 92 return o.amountFlow; 93 } 94 95 } 96 97 // 98 //public class FlowBean implements Writable { 99 // 100 // String phoneNum; 101 // 102 // public String getPhoneNum() { 103 // return phoneNum; 104 // } 105 // 106 // public void setPhoneNum(String phoneNum) { 107 // this.phoneNum = phoneNum; 108 // } 109 // 110 // int upFlow; 111 // int downFlow; 112 // int sunFlow; 113 // 114 // public FlowBean() { 115 // } 116 // 117 // public FlowBean(int up, int down , String num) { 118 // this.upFlow = up; 119 // this.downFlow = down; 120 // this.sunFlow = up+down; 121 // this.phoneNum = num; 122 // } 123 // 124 // public int getUpFlow() { 125 // return upFlow; 126 // } 127 // 128 // public void setUpFlow(int upFlow) { 129 // this.upFlow = upFlow; 130 // } 131 // 132 // public int getDownFlow() { 133 // return downFlow; 134 // } 135 // 136 // public void setDownFlow(int downFlow) { 137 // this.downFlow = downFlow; 138 // } 139 // 140 // public int getSunFlow() { 141 // return sunFlow; 142 // } 143 // 144 // public void setSunFlow(int sunFlow) { 145 // this.sunFlow = sunFlow; 146 // } 147 // 148 // /** 149 // * hadoop系统在序列化该类的对象时要调用的方法 150 // */ 151 // @Override 152 // public void readFields(DataInput input) throws IOException { 153 // this.upFlow = input.readInt(); 154 // this.downFlow = input.readInt(); 155 // this.sunFlow = input.readInt(); 156 // this.phoneNum = input.readUTF(); 157 // } 158 // 159 // /** 160 // * hadoop系统在反序列化该类的对象时要调用的方法 161 // */ 162 // @Override 163 // public void write(DataOutput out) throws IOException { 164 // // TODO Auto-generated method stub 165 // out.writeInt(upFlow); 166 // out.writeInt(downFlow); 167 // out.writeInt(sunFlow); 168 // out.writeUTF(phoneNum); 169 // } 170 // 171 // @Override 172 // public String toString() { 173 // // TODO Auto-generated method stub 174 // return this.upFlow + "," + this.downFlow + "," + this.sunFlow; 175 // } 176 // 177 //}
1 package mr.flow; 2 import java.io.IOException; 3 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Mapper; 7 8 public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{ 9 10 11 @Override 12 protected void map(LongWritable key, Text value, Context context) 13 throws IOException, InterruptedException { 14 15 String line = value.toString(); 16 String[] fields = line.split(" "); 17 18 String phone = fields[1]; 19 20 int upFlow = Integer.parseInt(fields[fields.length-3]); 21 int dFlow = Integer.parseInt(fields[fields.length-2]); 22 23 context.write(new Text(phone), new FlowBean(phone, upFlow, dFlow)); 24 } 25 26 27 } 28 29 // 30 //import java.io.IOException; 31 // 32 //import org.apache.hadoop.io.LongWritable; 33 //import org.apache.hadoop.io.Text; 34 //import org.apache.hadoop.mapreduce.Mapper; 35 // 36 //public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> { 37 // 38 // @Override 39 // protected void map(LongWritable key, Text value, 40 // Mapper<LongWritable, Text, Text, FlowBean>.Context context) 41 // throws IOException, InterruptedException { 42 // String[] values=value.toString().split("/t"); 43 // context.write(new Text(values[1]), new FlowBean(values[1],Integer.parseInt(values[values.length-3]), Integer.parseInt(values[values.length-2]))); 44 // 45 // } 46 // 47 //}
1 package mr.flow; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Reducer; 7 8 public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean>{ 9 10 11 12 /** 13 * key:是某个手机号 14 * values:是这个手机号所产生的所有访问记录中的流量数据 15 * 16 * <135,flowBean1><135,flowBean2><135,flowBean3><135,flowBean4> 17 */ 18 @Override 19 protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) 20 throws IOException, InterruptedException { 21 22 int upSum = 0; 23 int dSum = 0; 24 25 for(FlowBean value:values){ 26 upSum += value.getUpFlow(); 27 dSum += value.getdFlow(); 28 } 29 30 31 context.write(key, new FlowBean(key.toString(), upSum, dSum)); 32 33 } 34 35 36 } 37 38 // 39 //import java.io.IOException; 40 // 41 //import org.apache.hadoop.io.Text; 42 //import org.apache.hadoop.mapreduce.Reducer; 43 // 44 //public class FlowCountReduce extends Reducer<Text, FlowBean, Text, FlowBean> { 45 // 46 // @Override 47 // protected void reduce(Text key, Iterable<FlowBean> value, 48 // Reducer<Text, FlowBean, Text, FlowBean>.Context context) 49 // throws IOException, InterruptedException { 50 // int upSun=0,downSun=0; 51 // 52 // for (FlowBean flowBean : value) { 53 // upSun+=flowBean.getUpFlow(); 54 // downSun+=flowBean.getAmountFlow(); 55 // } 56 // context.write(key, new FlowBean( key.toString(),upSun,downSun)); 57 // } 58 //}


1 package mr.flow; 2 3 import java.io.IOException; 4 import java.net.URI; 5 import java.net.URISyntaxException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Job; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 15 16 public class JobSubmitMain { 17 18 public static final String HADOOP_INPUT_PATH = "hdfs://hadoop1:9000/InputFlow"; 19 public static final String HADOOP_OUTPUT_PATH = "hdfs://hadoop1:9000/OutputFlow"; 20 public static final String HADOOP_ROOT_PATH = "hdfs://hadoop1:9000"; 21 public static void main(String[] args) throws IOException, 22 ClassNotFoundException, InterruptedException, URISyntaxException { 23 Configuration conf = new Configuration(); 24 // 2、设置job提交到哪去运行 25 //conf.set("fs.defaultFS", HADOOP_ROOT_PATH); 26 //conf.set("mapreduce.framework.name", "yarn"); 27 Job job = Job.getInstance(); 28 job.setJarByClass(JobSubmitMain.class); 29 job.setMapperClass(FlowCountMapper.class); 30 job.setReducerClass(FlowCountReducer.class); 31 job.setMapOutputKeyClass(Text.class); 32 job.setMapOutputValueClass(FlowBean.class); 33 job.setOutputKeyClass(Text.class); 34 job.setOutputValueClass(FlowBean.class); 35 Path output = new Path(HADOOP_OUTPUT_PATH); 36 FileSystem fs = FileSystem.get(new URI(HADOOP_ROOT_PATH), conf); 37 if (fs.exists(output)) { 38 fs.delete(output, true); 39 } 40 FileInputFormat.setInputPaths(job, new Path(HADOOP_INPUT_PATH)); 41 FileOutputFormat.setOutputPath(job, output); 42 job.setNumReduceTasks(1); 43 //job.submit(); 44 job.waitForCompletion(true); 45 System.out.println("OK"); 46 } 47 }
WordCount main 类(Windows需要注意)
1 package WordCount; 2 3 import java.io.IOException; 4 import java.net.URI; 5 import java.net.URISyntaxException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.IntWritable; 11 import org.apache.hadoop.io.Text; 12 import org.apache.hadoop.mapreduce.Job; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 16 public class WordCountMain { 17 18 public static final String HADOOP_ROOT_PATH = "hdfs://hadoop1:9000"; 19 public static final String HADOOP_INPUT_PATH = "hdfs://hadoop1:9000/Input"; 20 public static final String HADOOP_OUTPUT_PATH = "hdfs://hadoop1:9000/Output"; 21 22 public static void main(String[] args) throws IOException, 23 URISyntaxException, ClassNotFoundException, InterruptedException { 24 25 Configuration conf = new Configuration(); 26 // 1、设置job运行时要访问的默认文件系统 27 //conf.set("fs.defaultFS", HADOOP_ROOT_PATH); 28 // 2、设置job提交到哪去运行 29 conf.set("mapreduce.framework.name", "yarn"); 30 //conf.set("yarn.resourcemanager.hostname", "hadoop1"); 31 // 3、如果要从windows系统上运行这个job提交客户端程序,则需要加这个跨平台提交的参数 32 //conf.set("mapreduce.app-submission.cross-platform", "true"); 33 34 Job job = Job.getInstance(conf); 35 36 // 1、封装参数:jar包所在的位置 37 job.setJar("/home/hadoop/wordcount.jar"); 38 //job.setJarByClass(WordCountMain.class); 39 40 // 2、封装参数: 本次job所要调用的Mapper实现类、Reducer实现类 41 job.setMapperClass(WordCountMapper.class); 42 job.setReducerClass(WordcountReducer.class); 43 44 // 3、封装参数:本次job的Mapper实现类、Reducer实现类产生的结果数据的key、value类型 45 job.setMapOutputKeyClass(Text.class); 46 job.setMapOutputValueClass(IntWritable.class); 47 job.setOutputKeyClass(Text.class); 48 job.setOutputValueClass(IntWritable.class); 49 50 // 4、封装参数:本次job要处理的输入数据集所在路径、最终结果的输出路径 51 Path output = new Path(HADOOP_OUTPUT_PATH); 52 FileSystem fs = FileSystem.get(new URI(HADOOP_ROOT_PATH), conf); 53 if (fs.exists(output)) { 54 fs.delete(output, true); 55 } 56 FileInputFormat.setInputPaths(job, new Path(HADOOP_INPUT_PATH)); 57 FileOutputFormat.setOutputPath(job, output); // 注意:输出路径必须不存在 58 59 // 5、封装参数:想要启动的reduce task的数量 60 job.setNumReduceTasks(2); 61 62 // 6、提交job给yarn 63 boolean res = job.waitForCompletion(true); 64 System.out.println("OK"); 65 System.exit(res ? 0 : -1); 66 67 } 68 69 }
关键点是:
v 参数 mapreduce.framework.name = yarn | local
同时,如果要运行在yarn上,以下两个参数也需要配置:
参数 yarn.resourcemanager.hostname = ....
参数 fs.defaultFS = ....