2015.08.16zookepper
Zookeeper
是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务(如同小区里面的供水、电的系统)
它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等(在大数据框架后面默默地工作,它可以完成大数据计算框架在它们主要业务外的辅助性业务)
Zookepper的角色
数据同步的工具
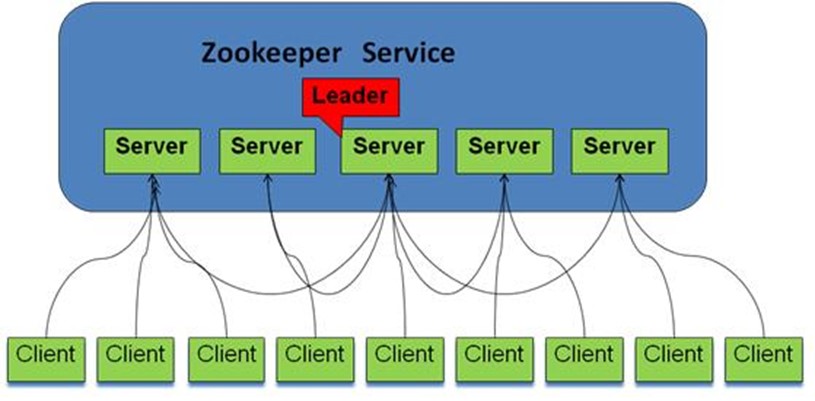
事务性地同步数据
领导者(leader),负责进行投票的发起和决议,更新系统状态
学习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
Observer(知道数据同步的状态,使用它完成编程一些事情)可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
客户端(client),请求发起方
Zookeeper的特性
Zookeeper是简单的
Zookeeper是富有表现力的
Zookeeper具有高可用性(集群结构,leader挂了,会自动选出新的leader)
Zookeeper采用松耦合交互方式
Zookeeper是一个资源库(存储数据)
Zookeeper的数据模型
层次化的目录结构,命名符合常规文件系统规范(树状的文件系统)
每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
节点Znode可以包含数据和子节点(有序性,可分布式排序,永久性节点和临时节点(/TMP),临时节点随着建立节点的连接的消失而消失,可监控这个节点监控这个连接),但是EPHEMERAL类型的节点不能有子节点
Znode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
客户端应用可以在节点上设置监视器
节点不支持部分读写,而是一次性完整读写
文件系统
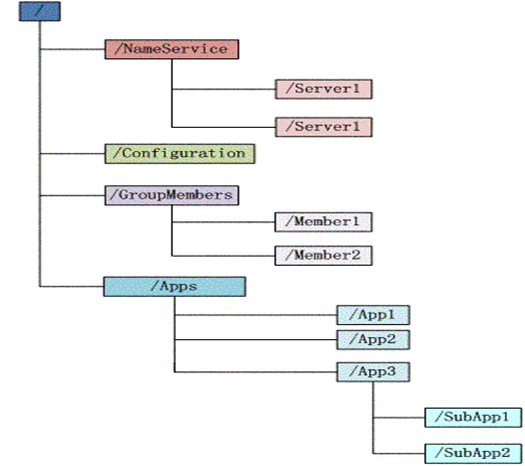
Zookeeper的节点
Znode有两种类型,短暂的(ephemeral)和持久的(persistent)
Znode的类型在创建时确定并且之后不能再修改
短暂znode的客户端会话结束时,zookeeper会将该短暂znode删除,短暂znode不可以有子节点
持久znode不依赖于客户端会话,只有当客户端明确要删除(通过敲代码)该持久znode时才会被删除
Znode有四种形式的目录节点,PERSISTENT、PERSISTENT_SEQUENTIAL(临时有序性)、EPHEMERAL、EPHEMERAL_SEQUENTIAL(持久有序性)
Zookeeper的安装和配置(单机模式)
解压:tar -zxvf zookeeper-3.4.6.tar.gz -C .(stable稳定版,加点是当前路径)
在conf目录下创建一个配置文件zoo.cfg(mv zoo_sample.cfg zoo.cfg)


dataDir=/usr/local/zookeeper-3.4.6/data (新建个data文件zk存放各个节点数据的路径,编辑配置文件将路径配置进去)

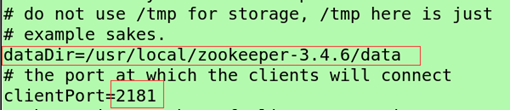
Clientport =2181(端口号)
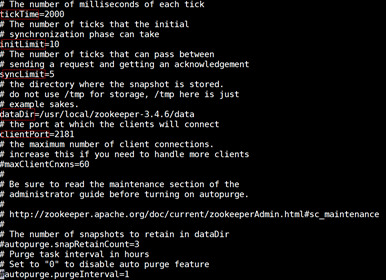
- tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
- dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
- clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
- initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
- syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
- server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
启动ZooKeeper的Server:sh bin/zkServer.sh start
如果想要关闭,输入:zkServer.sh stop
Jps查看到QuorumPeerMain (quorum是法定人数,定额的意思, peer是对等的意思)
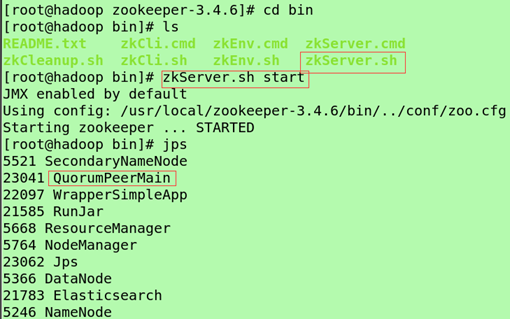
(连接命令行客户端)zkCli.sh,客户端连接zookepper建立了一个session(有状态的,建立关闭可监控,zk对其监控)


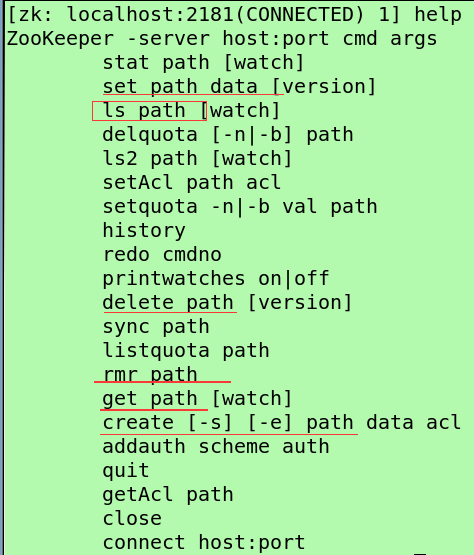
(查看)ls /
(zk是文件系统)ls /zookeeper
ls /zookeeper/quota

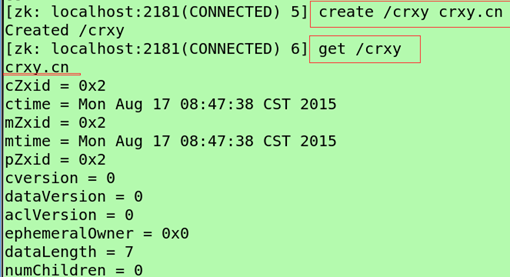
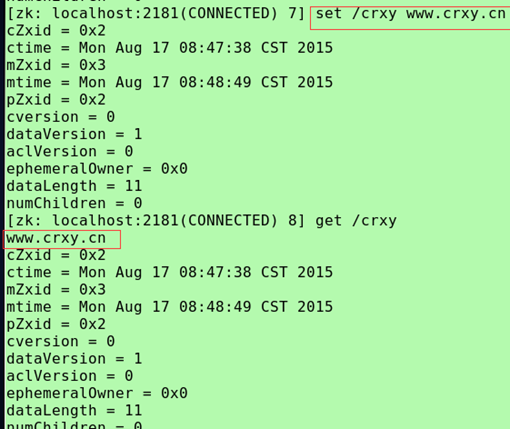
(创建)create /crxy crxy.cn(文件名,文件内容)
(查看内容)get /crxy(信息有内容,创建时间,版本,文件大小)
(修改内容)set /crxy www.crxy.cn
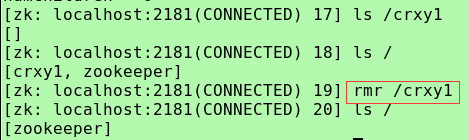
(删除)rmr/delete

Java客户端
(connectingString连接字符串(连接zookepper,选第二个),sessionTimeout会话超时(网络原因会连接不上),watcher监视器,监视节点和其数据的变化,在前面交叉点一下),需要一个实现,newwatcher,它是一个接口,创建了一个匿名类(不是外部类),其里面有个process方法,形参WatchedEvent(监控事件),通过监听的类型体现出来,会抛异常,使用完close
(eclipse操作,光标移到创建的形参里面,第一个是创建本地变量。Shift+home/end选定当前行,Alt+Shift+L 抽取本地变量( 可以直接把一些魔法数字和字符串抽取成一个变量,尤其是多处调用的时候) )
(如果连接不上关物理机和虚拟机的防火墙。关虚拟机)systemctl stop firewalld.service
Zookeeper的安装和配置(集群模式)
创建myid文件,server1机器的内容为:1,server2机器的内容为:2,server3机器的内容为:3
在conf目录下创建一个配置文件zoo.cfg,
dataDir=/usr/local/zk/data server.1=server1:2888:3888 (第一个1表示zk节点,在/data目录下myid文件写入自身的标示(如这里的数字1)3888是选举leader的端口号) server.2=server2:2888:3888 server.3=server3:2888:3888
(在213的机器上scp -rp zookeeper-3.4.6/ crxy212.crxy/usr/local)
(scp -rp zookeeper-3.4.6/ crxy211.crxy/usr/local)
(到212 zk目录下vi /data/myid改为212)
(依次启动zk目录下bin/zkSever.sh start,启动成功会有日志信息,)(查看身份bin/zkServer.sh status)
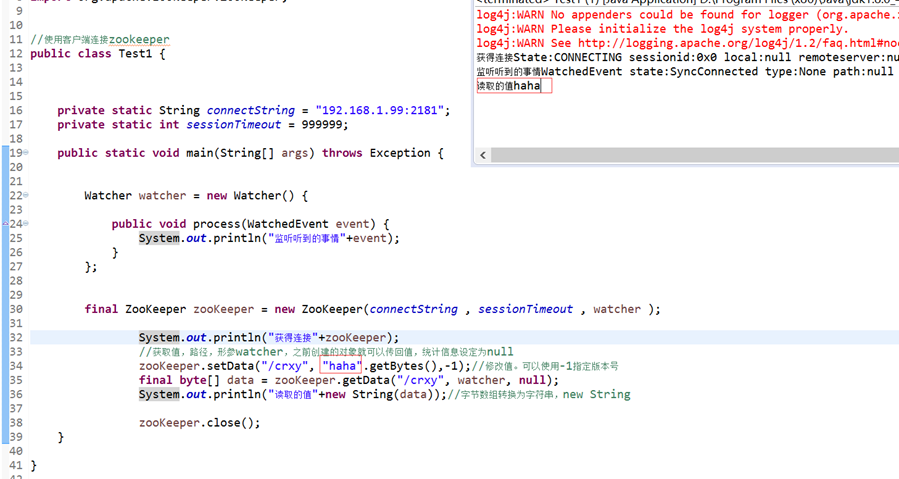
package zookeeper1;
import java.io.IOException;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
//使用客户端连接zookeeper
public class Test1 {
private static String connectString = "192.168.1.99:2181";
private static int sessionTimeout = 999999;
public static void main(String[] args) throws Exception {
Watcher watcher = new Watcher() {
public void process(WatchedEvent event) {
System.out.println("监听听到的事情"+event);
}
};
final ZooKeeper zooKeeper = new ZooKeeper(connectString , sessionTimeout , watcher );
System.out.println("获得连接"+zooKeeper);
//获取值,路径,形参watcher,之前创建的对象就可以传回值,统计信息设定为null
zooKeeper.setData("/crxy", "haha".getBytes(),-1);//修改值。可以使用-1指定版本号
final byte[] data = zooKeeper.getData("/crxy", watcher, null);
System.out.println("读取的值"+new String(data));//字节数组转换为字符串,new String
zooKeeper.close();
}
}
Zookeeper应用场景
分布式队列
FIFO(先进先出)
Barrier(同步队列)
共享锁
集群管理
leader选举
命名服务
分布式应用配置项的管理等
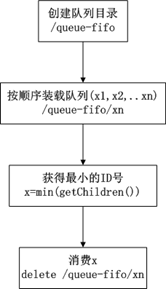
分布式FIFO队列
FIFO设计思路
1.在/queue-fifo的目录下创建 SEQUENTIAL 类型的子目录 /x(i),这样就能保证所有成员加入队列时都是有编号的。
2.出队列时通过 getChildren( ) 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证FIFO
Barrier(同步队列)
当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
例如:远程会议,所有人到齐了,才开始
共享锁
Zookeeper 可以实现跨进程或者在不同 Server 之间的共享锁
(JVM同一个进程实现锁通过synchronized,lock)