视频学习
卷积神经网络
基本应用:图片分类、检索、检测、分割,人脸验证、人脸识别、遗传病识别、人脸表情识别、图像生成、图像风格转化、自动驾驶
深度学习三部曲:1.搭建神经网络 2.找一个合适的损失函数 3.找一个合适的优化函数更新参数
损失函数:用来衡量吻合度,来调整参数,使映射结果与实际类别吻合。
-
常用分类损失:交叉熵损失、hinge loss
-
常用回归损失:均方误差、平均绝对值误差(L1损失)
传统神经网络用于计算机视觉的问题:
参数太多:全连接网络权重矩阵参数太多 → 过拟合
CNN解决方法:局部关联,参数共享
卷积
深度:卷积核个数,feature map厚度
图像N×N,卷积核F×F,输出特征图大小:
(N-F)/stride+1 (未加padding)
(N+padding*2-F)/stride+1
参数量:(卷积核大小5*5+偏置1)×个数
池化
缩放,保留主要特征。可以减少参数量计算量,防止过拟合提高泛化能力。
一般处于卷积层与卷积层之间,全连接层与全连接层之间。
常用:最大值池化(VGG、ResNet)、平均池化
全连接
32×32×3 image → stretch to 3072×1
通常在CNN尾部,参数量最大。
CNN典型结构
AlexNet(8 layers):2012年ImageNet图像分类错误率比上年下降10%。
AlexNet成功原因:
-
ImageNet大数据训练
-
ReLU非线性激活函数
Sigmoid 小于-5大于5时梯度变为0,梯度消失无法更新网络。ReLU在一定程度上解决了梯度消失问题。
ReLU表达式简单,计算速度快。
ReLU收敛速度快,梯度比Sigmoid大。
-
Dropout、Data augmentation防止过拟合
Dropout训练时随机关闭部分神经元,测试时整合所有神经元。
数据增强:随机裁剪、翻转、改变RGB通道强度等。
-
双GPU实现
ZFNet:2013年ImageNet分类冠军。错误率16.4% → 14.8%。
网络结构与AlexNet相同。感受野大小11×11 → 7×7,步长4 → 2。卷积层3 4 5滤波器个数384 384 256 → 512 512 1024。
VGG(16-19):2014年第二。AlexNet上加深深度。未有批归一化,先训练前11层固定参数,再训练后面的层。
GoogLeNet(22):20014年冠军。AlexNet上改变模型结构,加入Inception模块。没有FC层,参数量仅为AlexNet的1/12。有辅助分类器。
Inception模块:通过多个卷积核增加特征多样性。使用padding保证feature map大小一致,对其在深度上进行串联。但进行串联后channel会变大,计算量复杂,pooling改变feature map大小,不改变channel,随着模型加深,channel会一直增大。
Inception V2:增加1×1卷积核进行降维。
Inception V3:进一步对V2的参数数量进行降低。使用两个3×3卷积核替代5×5卷积核,降低了参数量。卷积核增多,非线性激活函数增加,表征能力更强,训练更快。
ResNet(152):2015年三项竞赛冠军。
不存在梯度消失问题,(f‘+1)(g’+1)(h‘+1)。
若F(x)=0,F(x)+x=x,可以根据任务学习一个所需要的深度,调节结构。
批归一化:用来防止过拟合,对隐藏层输出进行归一化,一般加在卷积激活之后。
梯度消失和梯度爆炸:梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。
梯度消失:
- 隐藏层的层数过多
- 采用了不合适的激活函数(更容易产生梯度消失,但是也有可能产生梯度爆炸)
梯度爆炸:
- 隐藏层的层数过多
- 权重的初始化值过大
ResNet实现
CNN可以拟合任何一个函数。
网络深后会出现网络退化问题。
残差学习:拟合H(x),由于网络退化问题难以训练出来,转为训练F(x),F(x)=H(x)-x,F(x)称为残差,然后H(x)=F(x)+x。
虚线连接表示特征图大小发生变化,不再是恒等映射,用虚线表示。
ResNet由5个stage组成,每个stage有若干个block,每个block有若干个convs。可以实现可扩展性的代码。
全局平均池化,可以替代全连接层,参数更少,更少出现过拟合。
50+/50-的ResNet,组成结构有什么不同:
50层以下的每个block由两个layer组成,没有BottleNeck。不降维的话,网络深度增加,参数量过大,高维时channel已经有256维。

↑ 注意细节,第一层直接调用relu,第二层先融合再relu。
ResNetXt 分组卷积
ResNetXt-Attention 注意力机制
ResNetXt WSL 弱监督训练
分组卷积最早出现在AlexNet,为了解决GPU内存较小跑不下的问题。后来发现通过分组卷积可以提高准确度。
代码练习
-
加载数据
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=2) #子进程数
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
- root 为数据集下载到本地后的根目录,包括 training.pt 和 test.pt 文件
- train,如果设置为True,从training.pt创建数据集,否则从test.pt创建。
- download,如果设置为True, 从互联网下载数据并放到root文件夹下
- transform, 一种函数或变换,输入PIL图片,返回变换之后的数据。
- target_transform 一种函数或变换,输入目标,进行变换。
transforms.Compose()
Compose里面的参数实际上就是个列表,而这个列表里面的元素就是想要执行的transform操作。
train_loader = torch.utils.data.DataLoader( datasets.MNIST('./data', train=True, download=True, transform=transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])), batch_size=64, shuffle=True) test_loader = torch.utils.data.DataLoader( datasets.MNIST('./data', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])), batch_size=1000, shuffle=True) -
图片展示
plt.imshow(np.transpose(npimg, (1, 2, 0)))
因为在plt.imshow在实现的时候输入的是(imagesize,imagesize,channels),而def imshow(img)中,参数img的格式为(channels,imagesize,imagesize),这两者的格式不一致,我们需要调用一次np.transpose函数,即np.transpose(npimg,(1,2,0)),将npimg的数据格式由(channels,imagesize,imagesize)转化为(imagesize,imagesize,channels),进行格式的转换后方可进行显示。
def imshow(img): plt.figure(figsize=(8,8)) img = img / 2 + 0.5 # 转换到 [0,1] 之间 npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() -
Net计算
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) #32*32*3 28*28*6 self.pool = nn.MaxPool2d(2, 2) #14*14*6 self.conv2 = nn.Conv2d(6, 16, 5) #10*10*16 #self.pool = nn.MaxPool2d(2, 2) #5*5*16 self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10)
论文学习
Inception V1
-
为什么要多个不同大小的卷积核并行?
不同大小的卷积核有不同的感受野,可以获取多尺度的信息。使用padding保证feature map大小一致。
-
1×1卷积起到降维操作。
-
辅助分类器
层数加深后会难以训练出现梯度消失问题,后面的变化很难反向传播。辅助分类器可能起到一个类似逐层预训练的作用。
辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化。而在实际测试的时候,这两个额外的softmax会被去掉。
Inception V3
-
卷积分解
使用两个3×3卷积核替代5×5卷积核,感受野不变,降低了参数量。卷积核增多,非线性激活函数增加,表征能力更强,训练更快。
任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。在网络的前期使用这种分解效果并不好,在中度大小的特征图上使用效果才会更好(特征图大小建议在12到20之间)。
-
高效的降维
池化并行。先池化再Inception卷积,或者先Inception卷积再作池化。但是先作池化会导致特征缺失,先作卷积是正常的缩小,但计算量很大。为了同时保持特征表示且降低计算量,将网络结构改为使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行通道合并)。
Inception V4
-
加入了残差学习
-
为什么加了残差后可以解决梯度消失问题
拟合H(x),由于网络退化问题难以训练出来。转为训练F(x),F(x)=H(x)-x,F(x)称为残差,然后H(x)=F(x)+x。
学习H(x)和F(x)的差,更容易学习,就像画一个人在有人物轮廓的情况下加细节,会容易些。
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
在某些真实的应用场景,如移动或者嵌入式设备,大而复杂的模型难以被应用。模型过于庞大,面临着内存不足的问题,其次这些场景要求低延迟,响应速度要快,研究小而高效的CNN模型在这些场景至关重要。目标在保持模型性能的前提下降低模型大小,同时提升模型速度。
深度可分离卷积
-
常规卷积操作
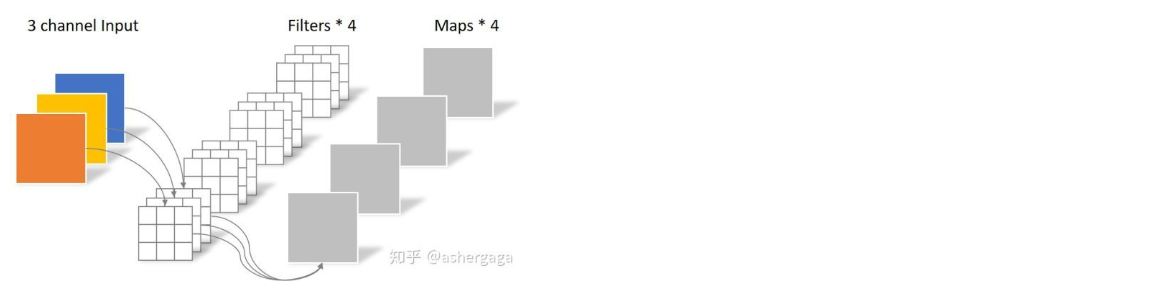
-
深度可分离卷积
-
逐通道卷积(Depthwise Convolution)

DW是做了分组卷积(group convolution),做了一个特征的分组,对feature map进行分组可以显著提高准确率。
-
逐点卷积(Pointwise Convolution)
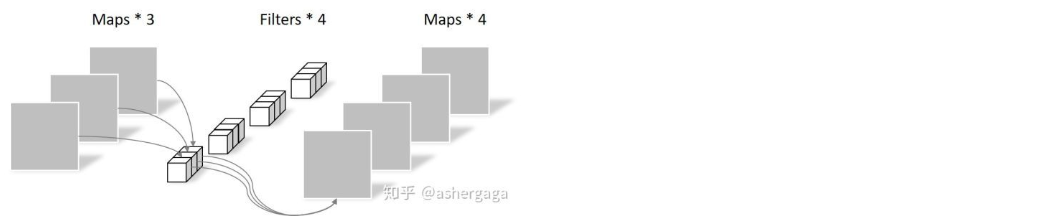
用1×1的卷积进行升维操作。
同样的输入,同样得到4张feature map,参数量显著减少。
-
HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification
-
高光谱图像:由二维空间信息和一维光谱信息组成。
-
二维卷积神经网络的问题:不能充分提取高光谱图像的光谱信息,只能提取三个通道。
三维卷积神经网络的问题:可以提取到光谱信息,但增加了计算复杂度。 -
高光谱图像光谱通道数过多,直接进行计算的话运算缓慢。先进行降维,PCA降维到30/15个通道即可保留到99%以上的信息。
-
结构:三层三维卷积神经网络+一层二维卷积神经网络+三层全连接。三维提取空间信息和光谱信息,二维进一步提取空间信息。
-
二维卷积和三维卷积的区别:二维卷积和特征图大小没有关系,输入100×100或200×200都可以,但要考虑输入的通道数。三维卷积可以无视输入的通道数。
-
思考:用什么方法可以进一步提高网络性能?
考虑把二维卷积替换成mobilenets,至少可以降低计算复杂度。
纹理缺陷检测尝试
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
import cv2
import csv
from google.colab.patches import cv2_imshow
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
image_height = 512
image_width = 512
读取train.csv文件,获取文件中的label,为RLE编码的mask。
file_dir = '/content/drive/My Drive/AIyanxishe80'
with open(file_dir + '/train.csv', 'r') as f:
reader = csv.reader(f)
result = list(reader)
#print(result[1][1])

-
对RLE编码的mask进行解码,解码输出结果为0和255组成的二维数组,图片展示如下。
代码参考:https://blog.csdn.net/appleyuchi/article/details/102938491
def rle_decode(mask_rle: str = '', shape: tuple = (1400, 2100)):
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0] * shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):#进行恢复
img[lo:hi] = 255
return img.reshape(shape, order='F')
array = rle_decode(result[1][1],(image_height,image_width))
cv2_imshow(array)

-
在原始图像上绘制mask的轮廓,使用findContours函数从mask中寻找轮廓,其中mask需为二值图像。contours为函数返回的轮廓,在此contours为一个点集,点的集合组成轮廓。使用boundingRect函数获取了该轮廓外接矩形的参数,x y width height,考虑用该参数作为y进行模型训练。在原始图像上绘制mask及矩形轮廓的结果如下图所示。
def draw_mask_edge_on_image_cv2(image, mask):
image = cv2.cvtColor(image,cv2.COLOR_RGB2GRAY)
contours, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
x, y, w, h = cv2.boundingRect(contours[0])
image = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 255, 255), 1)
#cv2.drawContours(image, contours, -1, (0, 0, 255), 1)
return image, x, y, w, h
array = rle_decode(result[1][1],(image_height,image_width))
image = cv2.imread(file_dir + '/Train/0.png')
image_mask, x, y, w, h = draw_mask_edge_on_image_cv2(image, array)
cv2_imshow(image_mask)

array = rle_decode(result[1][1],(image_height,image_width))
image = cv2.imread(file_dir + '/Train/' + str(0) + '.png')
img_a = torch.from_numpy(image).unsqueeze(0)
image_mask, x, y, w, h = draw_mask_edge_on_image_cv2(image, array)
y_a = torch.tensor([[x,y,w,h]])
for i in range(1886):
array = rle_decode(result[i+2][1],(image_height,image_width))
image = cv2.imread(file_dir + '/Train/' + str(i+1) + '.png')
img_b = torch.from_numpy(image).unsqueeze(0)
img_a = torch.cat((img_a,img_b), 0).type(torch.FloatTensor)
image_mask, x, y, w, h = draw_mask_edge_on_image_cv2(image, array)
y_b = torch.tensor([[x,y,w,h]])
y_a = torch.cat((y_a,y_b), 0).type(torch.FloatTensor)
print("[ %.2f / 100 ]" % ((i+2)*100/1886))
display.clear_output(wait=True)
X = img_a
y = y_a
dataset = Data.TensorDataset(X, y)
只解码了下数据集,经过资料查找目前理解有两种方法进行模型训练。一种是对原图像(512×512)进行截取,获取裁剪为小块(如64×64)的图像作为数据集,当缺陷面积占到2/3时将该数据标记为有缺陷,其他为无缺陷,然后进行分类。个人感觉可以模型训练好后,对测试图像也进行裁剪,将小块图像输入网络进行分类,最后标定的缺陷位置即为几个邻近有缺陷矩形的轮廓,但结果可能精确度较低。
思路参考:基于深度学习识别模型的缺陷检测
第二种方法是定义目标标签y为[x, y, w, h]。本来想尝试这种方法,但是对网络理解太不透彻,平时又多为分类任务,初期尝试失败,后续深入理解了再继续。