一:互联网简介
互联网是由各种计算机设备,通过连接介质相互连接而成的,目的是在不同的计算机之间传输数据,并且在互联网上有大量的数据是免费的。互联网的目的就是微辣方便彼此之间的数据共享,没有互联网,只能用U盘拷贝了。而爬虫就是用于从互联网中获取有价值的数据,从本质上来看,爬虫是一种应用程序,属于客户端的程序。
二:爬虫原理
爬虫是一种应用程序,用于从互联网中获取有价值的数据,从本质上来看,属于client客户端程序。我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。
此时用户获取网络数据的方式为:
浏览器提交请求 ----- 下载网页代码 ----- 解析/渲染成页面
而使用爬虫程序需要做的事情便是:
模拟浏览器发送请求 ----- 下载网页代码 ----- 只提取有用的数据 ----- 存放于数据库或者文件中
爬虫的核心便是只提取网页代码中对我们有用的数据,最终保存得到有价值的数据。
三:爬虫的基本流程
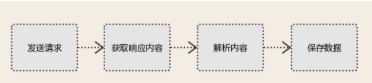
#1、发送请求 发送请求之前还有一个分析请求:分析web页面得到发送请求必备数据。 使用http库向目标站点发起请求,即发送一个Request Request包含:请求头、请求体 #2、获取响应内容 如果服务器能正常响应,则会得到一个Response Resonse包含:html代码,json,图片、视频等 #3、解析内容 解析html数据:正则表达式、第三方解析库如:Beautifulsoup,pyquery等 解析json数据:json模块 解析二进制数据:以二进制模式写进文件 #4、保存数据 保存在数据库、文件等方式。
3.1 HTTP请求分析
首先要明确的是:爬虫的核心原理就是模拟浏览器发送HTTP协议来偶去服务器上的数据,那么要想服务器接受你的请求,则必须将自己的请求伪装的足够像,这就需要HTTP请求分析这一过程。其次,HTTP协议是基于请求响应模型的,客户端发送请求到服务器,服务器接受请求,处理后返回响应数据,需要关注的重点在于请求数据,只有服务器认为合格合法的请求才会得到服务器的响应。
利用Chrome开发者工具来分析请求
Chrome浏览器提供强大的开发者工具,我们可以利用它来查看浏览器与服务器的整个通讯过程。

打开chrome的设置页面搜索cookie就可以找到清空按钮。

请求流程地址分析
1. 请求地址
浏览器发送的请求url地址
2. 请求方法
get中文需要url编码,参数跟在地址后面
post参数放在body中
3. 请求头

cookie:需要登录成功才能访问的页面就需要传递cookie,否则不需要cookie
user-agent:用户代理,验证客户端类型
referer: 引用页面,判断是从哪个页面点击过来的
4. 请求体

只在post请求时需要关注,通常post请求参数都放在请求体中,例如登录时的用用户名和密码
5. 响应头

location:重定向的目标地址,仅在状态码为3xx的时候出现,需要考虑重定向时的方法、参数等,浏览器会自动重定向,request模块也会有。
set-cookie:服务器返回的cookie信息,在访问一些隐私页面是需要带上cookie的
6. 响应体
服务器返回的数据,可能以下几种类型:
HTML格式的静态页面,需要解析获取需要的数据
json格式的结构化数据,直接就是纯粹的数据
二进制数据(图片视频等),通过文件操作直接写入文件
四:总结(价值)
爬虫就是想网站发送请求,获取资源后分析并且提取有用的数据的应用程序。互联网中最宝贵的就是数据了,例如淘宝的商品数据,链家的房源信息,拉钩的招聘信息等等,这些数据就像一座矿山,爬虫就像是挖矿的工具,掌握了爬虫技术,你就成了矿山老板,各网站都在为你免费提供数据。