一:利用生成器单线程实现并发
1.GIL锁将导致Cpython无法利用多核优势,只能单核并发的执行。对于计算密集型任务,没有办法能够提高计算密集型任务的效率,除非拿掉GIL锁,让多核CPU并行执行。但是对于IO密集型任务,一旦线程遇到了IO操作CPu就会立马切换到其他线程,就会导致效率降低,为了提高效率,我们可以利用生成器来实现并发。
并发:指的是多个任务同时发生,看起来好像同时都在并行。
并行:指的是多个任务真正的同时进行
2.如何实现并发?
并发=切换任务+保存状态,可以利用生成器,其中有yield,每次调用next都会执行回到生成器函数中执行代码,也就是说任务之间可以来回切换,并且是基于上一次运行的结果,这意味着生成器会自动保存执行状态。


# 利用生成器实现并发执行 def task1(): while True: yield print('task1 run') def task2(): g=task1() while True: next(g) print('task2 run') task2()
#两个计算任务采用生成器切换并发执行 import time def task1(): a = 0 for i in range(10000000): a += i yield def task2(): g = task1() b = 0 for i in range(10000000): b += 1 next(g) s = time.time() task2() print("并发执行时间",time.time()-s) ==================================== 两个计算任务在单线程下串行执行 def task1(): a = 0 for i in range(10000000): a += i def task2(): b = 0 for i in range(10000000): b += 1 s = time.time() task1() task2() print("串行执行时间",time.time()-s) ========================================== 执行结果: 并发执行时间 3.7448408603668213 串行执行时间 1.7079405784606934
对于纯计算任务,单线程并发反而使执行效率下降了一半左右,生成器实现的并发是利用yield来切换,但是这样会使代码结构非常混乱,并且yield不能坚持IO。
二:协程
单线程下,不可避免会出现IO操作,但是如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到IO阻塞就切换去执行另一个任务,这样就保证了该线程能够最大限度的处于就绪态,也就是随时可以被CPU执行的状态,相当于我们在用户程序级别将自己的IO操作最大程度的隐藏起来,从而可以迷惑操作系统:该线程好像一直在计算,IO较少,从而更多的将CPU执行权限分配给我们的线程。
协程就是单线程下的并发,又称微线程。协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
需要强调的是: 1.python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到IO或执行时间过长就会被迫交出cpu执行权限,切换其他进程运行) 2.单线程内开启线程,一旦遇到IO,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非IO操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换:
优点:1.协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因此更加轻量级
2.单线程内就可以实现并发的效果,最大限度利用CPU
缺点:1.协程的本质是单线程下,无法利用多核,可以是一个程序开启多个线程,每个进程内开启多个线程,每个线程内开启协程
2.协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
协程特点:1.必须在只有一个单线程里实现并发
2.修改共享数据不需要加锁
3.用户程序里自己保存多个控制流的上下线
4.附加:一个协程遇到IO操作自动切换到其他协程
三:Greenlet模块
由于采用yield生成器方式过于麻烦(许哟啊先得到初始化以此的生成器,然后调用send...),于是有人对yield进行封装,便有了greenlet模块。
from greenlet import greenlet def eat(name): print('%s eat 1' %name) g2.switch('Grace') #切换至任务2 print('%s eat 2' %name) g2.switch() #切换至任务2 def play(name): print('%s play 1' %name) g1.switch() #切换至任务1 print('%s play 2' %name) g1=greenlet(eat) g2=greenlet(play) g1.switch('Grace')#可以在第一次switch时传入参数,以后都不需要
greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到IO,那就原地阻塞,仍然是没有解决遇到IO自动切换来提高效率问题。于是有了Gevent模块。
四:Gevent模块
Gevent是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet,它是以C扩展模块形式接入Python的轻量级协程。Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
使用Gevent模块来实现协程,能在多个任务间进行切换,而且能够自己检测IO
from gevent import monkey monkey.patch_all() import gevent import time def task1(): print("task1 run") time.sleep(10) print("task1 run") def task2(): print("task2 run") print("task2 run") g1 = gevent.spawn(task1) g2 = gevent.spawn(task2) # g1.join() # g2.join() # 等待所有任务结束 注意:如果开启了一个会产生的io的任务 并且你没有执行join, # 那么一旦发生io 这个任务就立马结束了 gevent.joinall([g2,g1])
需要注意的是:
1.协程执行时要想使任务执行则必须对协程对象调用join函数
2.有多个任务时,随便调用哪一个的join都会并发的执行所有任务,但是需要注意如果一个存在IO的任务没有被join,该任务将无法正常执行完毕
3.monkey补丁的原理是吧原始的阻塞模块替换为修改后的非阻塞模块,即偷梁换柱,来实现IO自定义切换,所以打补丁的位置一定要放到导入阻塞模块之前。
五:Event
同进程的一样。线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。
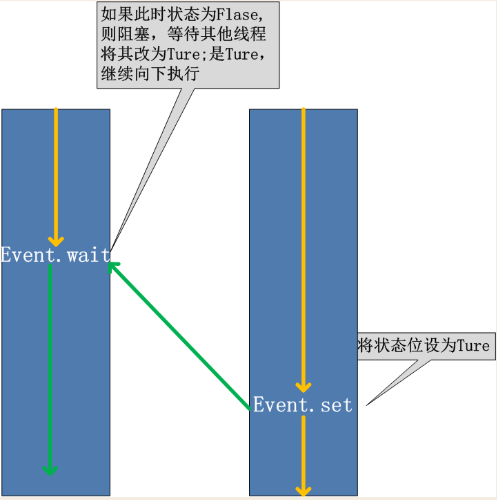
在初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
六:线程Queue
线程队列:与进程队列的区别,进程队列可以被多进程共享,而线程中的队列就是一个普通的容器不能进程共享。
1.先进先出class queue.Queue(maxsize=0)
from queue import Queue,LifoQueue,PriorityQueue q = Queue(1) q.put("a") q.put("b",timeout=1) print(q.get()) print(q.get(timeout=2))
2.后进先出(堆栈)(last in fisrt out):class queue.LifoQueue(maxsize=0)
from queue import Queue,LifoQueue,PriorityQueue lq = LifoQueue() lq.put("a") lq.put("b") lq.put("c") # print(lq.get()) print(lq.get()) print(lq.get())
3.优先级队列(取出顺序是从小到大,优先级可以使数字或字符,只要能够比较大小即可)
pq = PriorityQueue() # pq.put((2,"b")) # pq.put((3,"c")) # pq.put((1,"a")) # # print(pq.get()) # print(pq.get()) # print(pq.get()) pq.put((["a"],"bdslkfjdsfjd")) pq.put((["b"],"csdlkjfksdjkfds")) pq.put((["c"],"asd;kjfksdjfkdsf")) print(pq.get()) print(pq.get()) print(pq.get())
七:异步回调
1.什么是回调(函数)?
在发起一个异步任务的同时指定一个函数,在异步任务完成时会自动的调用result函数或是shutdown函数,而他们都是阻塞的,会等到任务执行完毕后才能继续执行,这样一来在这个等待过程中就无法继续执行其他任务,降低了效率,所以需要一种方案,既保证解析结果的线程不用等待,有能保证数据能够及时被解析,这个方案就是异步回调。(a交给b一个任务,b在执行完成后回过头调用了a的一个函数)
2.为什么需要回调函数?
需要获取异步任务的结果,但是又不应该阻塞(降低效率),高效的获取任务结果。
3.通常异步任务都会和回调函数一起使用
使用方式:使用add_done_callback函数()给Future对象绑定一个回调函数
# 线程池中使用异步回调 def get_data(url): print("%s 正在请求%s" % (current_thread().name, url)) response = requests.get(url) print("%s 请求%s成功" % (current_thread().name, url)) return response def parser(obj): res = obj.result() htm = res.content.decode("utf-8") ls = re.findall("href=.*?com", htm) print("%s解析完成! 共%s个连接" % (current_thread().name,len(ls))) if __name__ == '__main__': urls = ["https://www.baidu.com", "https://www.tmall.com", "https://www.taobao.com", "https://www.jd.com", "https://www.python.org", "https://www.apple.com"] pool = ThreadPoolExecutor(3) for i in urls: obj = pool.submit(get_data, i) # res = obj.result() # 会把任务变成串行 # parser(res) obj.add_done_callback(parser)
异步任务使用场景:
爬虫:1.从目标站点下载网页数据,本质就是HTML格式化字符串
2.用re从字符串中提取出需要的数据
import requests,re,os,random,time from concurrent.futures import ProcessPoolExecutor def get_data(url): print("%s 正在请求%s" % (os.getpid(),url)) time.sleep(random.randint(1,2)) response = requests.get(url) print(os.getpid(),"请求成功 数据长度",len(response.content)) #parser(response) # 3.直接调用解析方法 哪个进程请求完成就那个进程解析数据 强行使两个操作耦合到一起了 return response def parser(obj): data = obj.result() htm = data.content.decode("utf-8") ls = re.findall("href=.*?com",htm) print(os.getpid(),"解析成功",len(ls),"个链接") if __name__ == '__main__': pool = ProcessPoolExecutor(3) urls = ["https://www.baidu.com", "https://www.sina.com", "https://www.python.org", "https://www.tmall.com", "https://www.mysql.com", "https://www.apple.com.cn"] # objs = [] for url in urls: # res = pool.submit(get_data,url).result() # 1.同步的方式获取结果 将导致所有请求任务不能并发 # parser(res) obj = pool.submit(get_data,url) # obj.add_done_callback(parser) # 4.使用异步回调,保证了数据可以被及时处理,并且请求和解析解开了耦合 # objs.append(obj) # pool.shutdown() # 2.等待所有任务执行结束在统一的解析 # for obj in objs: # res = obj.result() # parser(res) # 1.请求任务可以并发 但是结果不能被及时解析 必须等所有请求完成才能解析 # 2.解析任务变成了串行,
总结:异步回调使用方法就是在提交任务后得到一个Futures对象,调用对象的add_done_callback来指定一个回调函数。
比喻:如果把任务比喻为烧水,没有回调时就只能守着水壶等待水开,有了回调相当于换了一个会响的水壶,烧水期间可做其他事情,等待水开了水壶会自动发出声音,这时候再来处理。水壶自动发出声音就是回调。
注意:
1.使用进程池时,回调函数都是主进程中执行
2.使用线程池时,回调函数的执行线程是不确定的,哪个线程空闲就交给哪个线程
3.回调函数默认接收一个参数就是这个任务对象自己,再通过对象的result函数来获取任务的处理结果