一:什么是GIL?
GIL是Global Interpreter Lock的缩写,全局解释器锁,是加在解释器上的互斥锁。
''' 定义: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.) ''' 释义: 在CPython中,这个全局解释器锁,也称为GIL,是一个互斥锁,防止多个线程在同一时间执行Python字节码,这个锁是非常重要的,因为CPython的内存管理非线程安全的,很多其他的特性依赖于GIL,所以即使它影响了程序效率也无法将其直接去除
结论:在Cpython解释器中,同一个进程中下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。
需要申明一点的是GIL并不是Python的特性,它是在实现Python解释器(Cpython)时引入的概念。python中一段代码可以通过Cpython,PyPy,Psyco等不同的Python执行环境来执行。然而因为Cpython是大部分环境下默认的Python执行环境。所以在很多人的概念里Cpython就是Python。所以需要明确的一点是,GIL仅存在于Cpython中,这不是Python这门语言的缺陷,而是Cpython解释器的问题。
二:GIL介绍及为什么需要GIL
GIL本质就是一把互斥锁,所有互斥锁的本质都是一样的,都是将并发变成并行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据的安全。
可以肯定的一点是:保护不同的数据安全,就应该加不同的锁。
首先明确执行一个py文件,分为三个步骤:
1.从硬盘加载python解释器到内存
2.从硬盘加载py文件到内存
3.解释器解析py文件内容,交给CPU执行
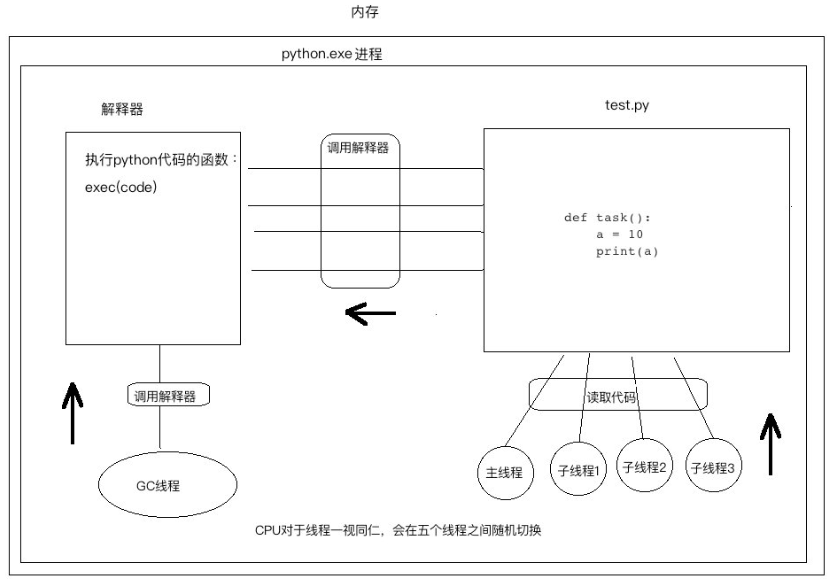
每当执行一个py文件,就会立即启动一个Python解释器,产生一个独立的进程。
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内,毫无疑问: #1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码) 例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。 #2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
也就是说:如果多个线程的target=work,执行流程如下:
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码。
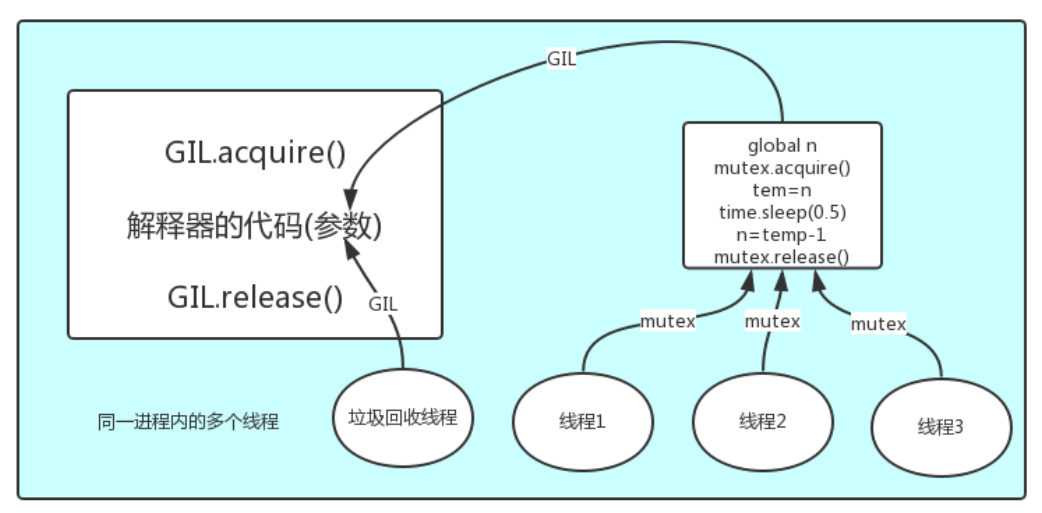
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理,如图:

Python中内存管理使用的是引用计数,每个数会被加上一个整型的计数器,表示这个数据被引用的次数,当这个整数变为0时则表示该数据已经没有人使用,成了垃圾数据。当内存占用达到某个阈值时,GC(内存管理机制)会将其他线程挂起,然后执行垃圾清理操作,垃圾清理也是一串代码,也就需要一条线程来执行。


from threading import Thread def task(): a = 10 print(a) # 开启三个子线程执行task函数 Thread(target=task).start() Thread(target=task).start() Thread(target=task).start() GC与其他线程都在竞争解释器的执行权,而CPU何时切换,以及切换到哪个线程都是无法预支的,这样一来就造成了竞争问题,假设线程1正在定义变量a=10,而定义变量第一步会先到到内存中申请空间把10存进去,第二步将10的内存地址与变量名a进行绑定,如果在执行完第一步后,CPU切换到了GC线程,GC线程发现10的地址引用计数为0则将其当成垃圾进行了清理,等CPU再次切换到线程1时,刚刚保存的数据10已经被清理掉了,导致无法正常定义变量。
为了避免GC与其他线程竞争带来的问题,Cpython给解释器加了锁。

由于互斥锁的特性,程序串行,保证数据的安全,降低执行效率,GIL将使得程序整体效率降低。
示例二:当进程中只有一条线程时,GIL锁不会有任何的影响,但是如果进程中有多个线程时,GIL锁就开始发挥作用。(代码要执行则必须交由解释器,即多个线程之间就需要共享解释器,为了避免共享带来的数据竞争问题,就要给解释器加互斥锁)
三:GIL加锁与解锁时机
加锁:在调用解释器时立即加锁
解锁:1.当前线程遇到了IO时释放
2.当前线程执行时间超过设定值时释放,解释器会检测线程的执行时间,一旦到达某个阈值,就会通知线程保存状态切换线程,一次来保存数据安全。
四:关于GIL的性能讨论
GIL优点:保证了Cpython中的内存管理是安全的
GIL缺点:互斥锁的特性使得多线程无法并行
但是,在单核处理器下,多线程之间本来就无法真正的并行执行。在多核处理下,运算效率的确比单核处理器高,但是在现代应用程序多数是基于网络的(QQ,微信,爬虫等),CPU的运行效率是无法决定网络速度的,而网络速度远远比不上处理器的运算速度,则意味着每次处理器在执行运算前都需要等待网络IO,这样一来多核优势也就没有那么明显了。
1. 任务1 从网络上下载一个网页,等待网络IO的时间为1分钟,解析网页数据花费,1秒钟 任务2 将用户输入数据并将其转换为大写,等待用户输入时间为1分钟,转换为大写花费,1秒钟 **单核CPU下:**1.开启第一个任务后进入等待。2.切换到第二个任务也进入了等待。一分钟后解析网页数据花费1秒解析完成切换到第二个任务,转换为大写花费1秒,那么总耗时为:1分+1秒+1秒 = 1分钟2秒 **多核CPU下:**1.CPU1处理第一个任务等待1分钟,解析花费1秒钟。1.CPU2处理第二个任务等待1分钟,转换大写花费1秒钟。由于两个任务是并行执行的所以总的执行时间为1分钟+1秒钟 = 1分钟1秒 可以发现,多核CPU对于总的执行时间提升只有1秒,但是这边的1秒实际上是夸张了,转换大写操作不可能需要1秒,时间非常短! 上面的两个任务都是需要大量IO时间的,这样的任务称之为IO密集型,与之对应的是计算密集型即没有IO操作全都是计算任务。 对于计算密集型任务,Python多线程的确比不上其他语言!为了解决这个弊端,Python推出了多进程技术,可以良好的利用多核处理器来完成计算密集任务。
总结:1.单核下无论是IO密集还是计算密集GIL都不会产生任何影响
2.多核下对于IO密集任务,GIL对它的影响可以忽略、
3.Cpython中IO密集任务采用多线程,计算密集任务采用多进程
另外:之所以大量采用Cpython解释器,就是因为大量的应用程序都是IO密集型的,还有另一个很重要的原因是Cpython可以无缝对接各种C语言实现的库,这对于一些数学相关的应用程序而言就可以直接使用现成的算法。
from multiprocessing import Process from threading import Thread import time def task(): for i in range(10000000): i += 1 if __name__ == '__main__': start_time = time.time() # 多进程 # p1 = Process(target=task) # p2 = Process(target=task) # p3 = Process(target=task) # p4 = Process(target=task) # 多线程 p1 = Thread(target=task) p2 = Thread(target=task) p3 = Thread(target=task) p4 = Thread(target=task) p1.start() p2.start() p3.start() p4.start() p1.join() p2.join() p3.join() p4.join() print(time.time()-start_time) =========================================== 多进程测试结果: 1.8134608268737793 多线程测试结果: 2.144787311553955
from multiprocessing import Process from threading import Thread import time def task(): with open("test.txt",encoding="utf-8") as f: f.read() if __name__ == '__main__': start_time = time.time() # 多进程 # p1 = Process(target=task) # p2 = Process(target=task) # p3 = Process(target=task) # p4 = Process(target=task) # 多线程 p1 = Thread(target=task) p2 = Thread(target=task) p3 = Thread(target=task) p4 = Thread(target=task) p1.start() p2.start() p3.start() p4.start() p1.join() p2.join() p3.join() p4.join() print(time.time()-start_time) ============================================ 多线程测试结果: 0.0010006427764892578 多进程测试结果: 0.3288099765777588
五:自定义的线程锁与GIL的区别
GIL保护的是解释器级别的数据安全,比如对象的引用计数,垃圾分代数据等等,具体参考垃圾回收机制。而对于程序中自己定义的数据则没有任何的保护效果,所以当程序中出现了共享自定义的数据时就要自己加锁。
未加锁之前:
from threading import Thread,Lock import time a = 0 def task(): global a temp = a time.sleep(0.01) a = temp + 1 t1 = Thread(target=task) t2 = Thread(target=task) t1.start() t2.start() t1.join() t2.join() print(a)
过程分析:
1.线程1获得CPU执行权,并获取GIL锁执行代码 ,得到a的值为0后进入睡眠,释放CPU并释放GIL
2.线程2获得CPU执行权,并获取GIL锁执行代码 ,得到a的值为0后进入睡眠,释放CPU并释放GIL
3.线程1睡醒后获得CPU执行权,并获取GIL执行代码 ,将temp的值0+1后赋给a,执行完毕释放CPU并释放GIL
之所以出现问题是因为两个线程子啊并发的执行同一段代码,解决方案就是加锁。
from threading import Thread,Lock import time lock = Lock() a = 0 def task(): global a lock.acquire() temp = a time.sleep(0.01) a = temp + 1 lock.release() t1 = Thread(target=task) t2 = Thread(target=task) t1.start() t2.start() t1.join() t2.join() print(a)
加锁后分析:
2.线程2获得CPU执行权,并获取GIL锁,尝试获取lock失败,无法执行,释放CPU并释放GIL
3.线程1睡醒后获得CPU执行权,并获取GIL继续执行代码 ,将temp的值0+1后赋给a,执行完毕释放CPU释放GIL,释放lock,此时a的值为1
4.线程2获得CPU执行权,获取GIL锁,尝试获取lock成功,执行代码,得到a的值为1后进入睡眠,释放CPU并释放GIL,不释放lock
5.线程2睡醒后获得CPU执行权,获取GIL继续执行代码 ,将temp的值1+1后赋给a,执行完毕释放CPU释放GIL,释放lock,此时a的值为2
六:进程池与线程池
本质上就是一个存储进程或线程的列表。如果是IO密集型任务使用线程池,计算密集型任务则使用进程池。
在很多情况下需要控制进程或者线程的数量在一个合理的范围,例如CPU程序中,一个客户端对于一个线程,虽然线程开销小,但是不能无限开,否则会耗尽系统资源,所以要控制线程数量。进程池/线程池不仅帮我们控制进程/线程的数量,还可以帮我们完成进程/线程的创建,销毁,以及任务的分配。(TCP是IO密集型,一个使用线程池)
from concurrent.futures import ThreadPoolExecutor from threading import active_count,current_thread import os,time # 创建线程池 指定最大线程数为3 如果不指定 默认为CPU核心数 * 5 pool = ThreadPoolExecutor(3)# 不会立即开启子线程 print(active_count()) def task(): print("%s running.." % current_thread().name) time.sleep(1) #提交任务到线程池 for i in range(10): pool.submit(task)
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor from threading import active_count,current_thread import os,time # 创建进程池 最大进程数为3 默认为cpu个数 pool = ProcessPoolExecutor(3)# 不会立即开启子进程 # time.sleep(10) def task(): print("%s running.." % os.getpid()) time.sleep(1) if __name__ == '__main__': # #提交任务到进程池 for i in range(10): pool.submit(task) # 第一次提交任务时会创建进程 ,后续再提交任务,直接交给以及存在的进程来完成,如果没有空闲进程就等待
七:同步异步与阻塞非阻塞
阻塞:当程序执行过程中遇到了IO操作,在执行IO操作时,程序无法继续执行其他代码。
非阻塞:程序正常运行没有遇到IO操作,或者通过某种方式是程序即使遇到了也不会停在原地,还可以执行其他操作,以提高CPU占用率
阻塞与非阻塞指的是程序的运行状态。
同步指调用:发起任务后必须在原地等待任务执行完成,才能继续执行
异步指调用:发起任务后不用等待任务执行,可以立即执行其他操作
同步会有等待的效果但是这和阻塞完全不同,阻塞时程序会被剥夺CPU执行权,而异步调用则不会。异步效率高于同步,到那时并不是所有任务都可以异步执行,判断一个任务是否可以异步的条件是,任务发起方是否立即需要执行结果。
from concurrent.futures import ThreadPoolExecutor from threading import current_thread import time pool = ThreadPoolExecutor(3) def task(i): time.sleep(0.01) print(current_thread().name,"working..") return i ** i if __name__ == '__main__': objs = [] for i in range(3): res_obj = pool.submit(task,i) # 异步方式提交任务# 会返回一个对象用于表示任务结果 objs.append(res_obj) # 该函数默认是阻塞的 会等待池子中所有任务执行结束后执行 pool.shutdown(wait=True) # 从结果对象中取出执行结果 for res_obj in objs: print(res_obj.result()) print("over")
from concurrent.futures import ThreadPoolExecutor from threading import current_thread import time pool = ThreadPoolExecutor(3) def task(i): time.sleep(0.01) print(current_thread().name,"working..") return i ** i if __name__ == '__main__': objs = [] for i in range(3): res_obj = pool.submit(task,i) # 会返回一个对象用于表示任务结果 print(res_obj.result()) #result是同步的一旦调用就必须等待 任务执行完成拿到结果 print("over")