看到很多人解析歌词文件时写了一大片的字符处理代码,而且看得不是很明白,所以自己研究了一下,
首先来了解下Lrc文件
时间格式:
1、标准格式: [分钟:秒.毫秒] 歌词
注释:括号、冒号、点号全都要求英文输入状态;
2、其他格式①:[分钟:秒] 歌词;
3、其他格式②:[分钟:秒:毫秒] 歌词,与标准格式相比,秒后边的点号被改成了冒号。
标准格式:
其格式为"[标识名:值]"。大小写等价。以下是预定义的标签。
[ar:艺人名]
[ti:曲名]
[al:专辑名]
[by:编者(指编辑LRC歌词的人)]
[offset:时间补偿值] 其单位是毫秒,正值表示整体提前,负值相反。这是用于总体调整显示快慢的。
标准好啊,我就按照标准来做了
public class Lrc { /// <summary> /// 歌曲 /// </summary> public string Title { get; set; } /// <summary> /// 艺术家 /// </summary> public string Artist { get; set; } /// <summary> /// 专辑 /// </summary> public string Album { get; set; } /// <summary> /// 歌词作者 /// </summary> public string LrcBy { get; set; } /// <summary> /// 偏移量 /// </summary> public string Offset { get; set; } /// <summary> /// 歌词 /// </summary> public Dictionary<double, string> LrcWord = new Dictionary<double, string>(); /// <summary> /// 获得歌词信息 /// </summary> /// <param name="LrcPath">歌词路径</param> /// <returns>返回歌词信息(Lrc实例)</returns> public static Lrc InitLrc(string LrcPath) { Lrc lrc = new Lrc(); using (FileStream fs = new FileStream(LrcPath, FileMode.Open, FileAccess.Read, FileShare.Read)) { string line; using (StreamReader sr = new StreamReader(fs, Encoding.Default)) { while ((line = sr.ReadLine()) != null) { if (line.StartsWith("[ti:")) { lrc.Title = SplitInfo(line); } else if (line.StartsWith("[ar:")) { lrc.Artist = SplitInfo(line); } else if (line.StartsWith("[al:")) { lrc.Album = SplitInfo(line); } else if (line.StartsWith("[by:")) { lrc.LrcBy = SplitInfo(line); } else if (line.StartsWith("[offset:")) { lrc.Offset = SplitInfo(line); } else { Regex regex = new Regex(@"[([0-9.:]*)]+(.*)", RegexOptions.Compiled); MatchCollection mc = regex.Matches(line); double time = TimeSpan.Parse("00:" + mc[0].Groups[1].Value).TotalSeconds; string word = mc[0].Groups[2].Value; lrc.LrcWord.Add(time, word); } } } } return lrc; } /// <summary> /// 处理信息(私有方法) /// </summary> /// <param name="line"></param> /// <returns>返回基础信息</returns> static string SplitInfo(string line) { return line.Substring(line.IndexOf(":") + 1).TrimEnd(']'); } } 一行代码:Lrc lrc= Lrc.InitLrc("test.lrc");
我将分离好的歌词放入了Dictionary<double, string>里,当然也可以直接用数组存,格式就要看实际的用途了,把这些都交给TimeSpan来做吧。
测试:


很久以前有人提出了这个问题:一行歌词里面有多个时间会报错,这么久了也没见人把好的方案提供出来,今天我花了点时间,修改了下,下面是获取歌词方法
/// <summary> /// 获得歌词信息 /// </summary> /// <param name="LrcPath">歌词路径</param> /// <returns>返回歌词信息(Lrc实例)</returns> public static Lrc InitLrc(string LrcPath) { Lrc lrc = new Lrc(); Dictionary<double, string> dicword = new Dictionary<double, string>(); using (FileStream fs = new FileStream(LrcPath, FileMode.Open, FileAccess.Read, FileShare.Read)) { string line; using (StreamReader sr = new StreamReader(fs, Encoding.Default)) { while ((line = sr.ReadLine()) != null) { if (line.StartsWith("[ti:")) { lrc.Title = SplitInfo(line); } else if (line.StartsWith("[ar:")) { lrc.Artist = SplitInfo(line); } else if (line.StartsWith("[al:")) { lrc.Album = SplitInfo(line); } else if (line.StartsWith("[by:")) { lrc.LrcBy = SplitInfo(line); } else if (line.StartsWith("[offset:")) { lrc.Offset = SplitInfo(line); } else { try { Regex regexword = new Regex(@".*](.*)"); Match mcw = regexword.Match(line); string word = mcw.Groups[1].Value; Regex regextime = new Regex(@"[([0-9.:]*)]", RegexOptions.Compiled); MatchCollection mct = regextime.Matches(line); foreach (Match item in mct) { double time = TimeSpan.Parse("00:" + item.Groups[1].Value).TotalSeconds; dicword.Add(time, word); } } catch { continue; } } } } } lrc.LrcWord = dicword.OrderBy(t => t.Key).ToDictionary(t => t.Key, p => p.Value); return lrc; }

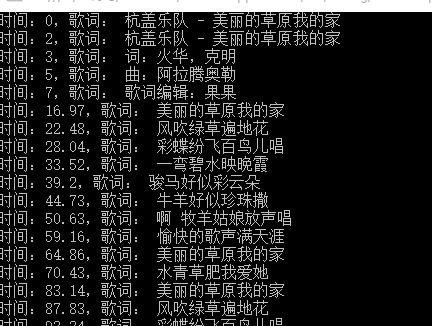
人还是原来的人,词找不到了