最近比赛数据进入到特征组合的阶段,在进行特征组合前,要分箱处理,等深等距之类的方法太没有道理了,加上测试集的深度广度也不同。
所以尝试了一种woe编码分箱的方法
import woe.feature_process as fp import woe.eval as eval dataset_train=pd.read_csv('E:/比赛/公积金逾期预测-数据/train.csv') dataset_test=pd.read_csv('E:/比赛/公积金逾期预测-数据/test.csv') #省略其他处理过程 #woe分箱 dataset_train.rename(columns={'label':'target'},inplace=True)#数据中必须有一列名为‘target’的列,在这里改了一下列名 civ_list=[] civ = fp.proc_woe_discrete(dataset_train, 'DWJJLX', 2757, 37243, 0.05*len(dataset_train), alpha=0.5)#对离散特征进行分箱 civ_list.append(civ) civ_df = eval.eval_feature_detail(civ_list) civ_df#输出分箱结果
dataset_train['DWJJLX'] = fp.woe_trans(dataset_train['DWJJLX'], civ)#woe赋值
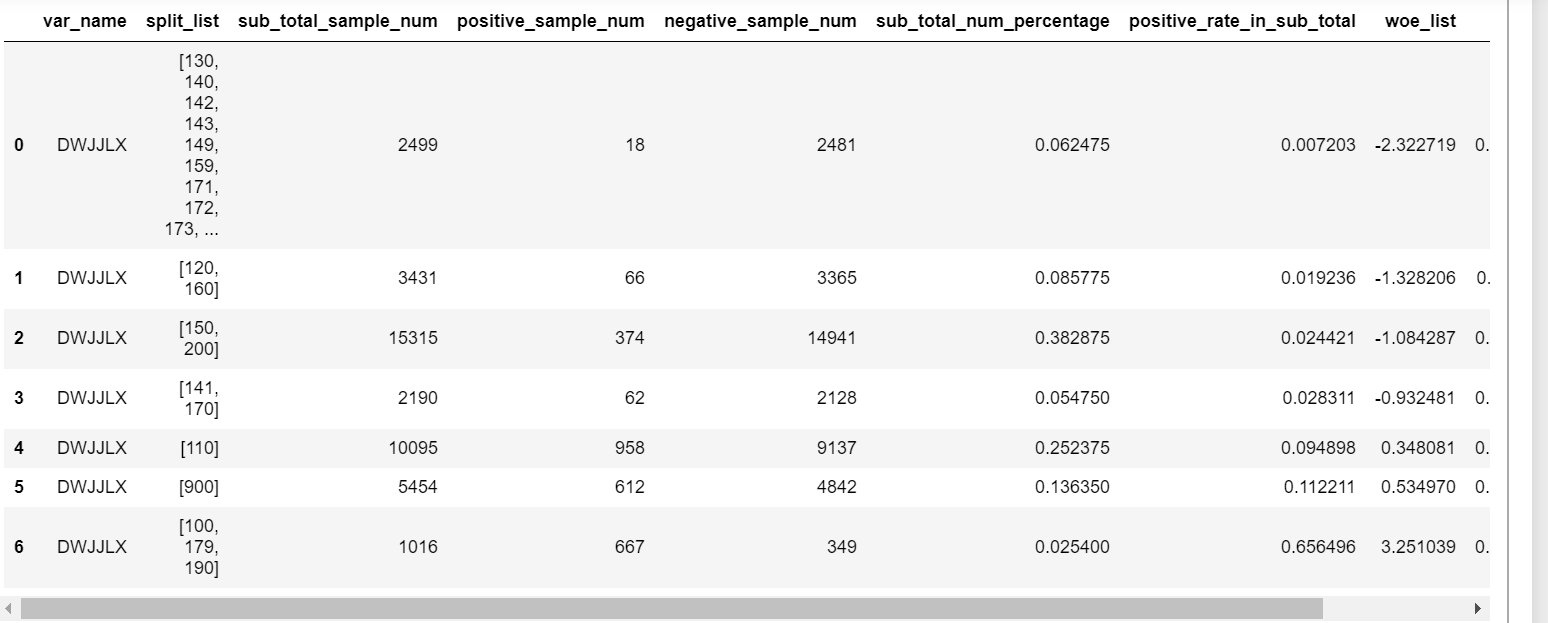
输出结果上表所示
分箱过程
核心函数主要是freature_process.proc_woe_discrete()与freature_process.proc_woe_continuous(),分别用于计算连续变量与离散变量的woe。它们的输入形式相同:
proc_woe_discrete(df,var,global_bt,global_gt,min_sample,alpha=0.01)
proc_woe_continuous(df,var,global_bt,global_gt,min_sample,alpha=0.01)
输入:
df: DataFrame,要计算woe的数据,必须包含'target'变量,且变量取值为{0,1}
var:要计算woe的变量名
global_bt:全局变量bad total。df的正样本数量
global_gt:全局变量good total。df的负样本数量
min_sample:指定每个bin中最小样本量,一般设为样本总量的5%。
alpha:用于自动计算分箱时的一个标准,默认0.01.如果iv_划分>iv_不划分*(1+alpha)则划分。
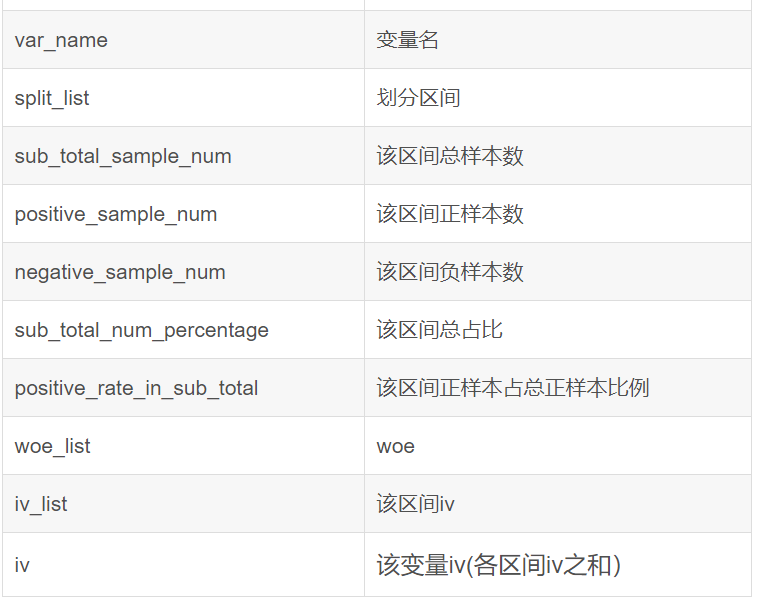
输出:一个自定义的InfoValue类的object,包含了分箱的一切结果信息。
打印分箱结果:
eval.eval_feature_detail(Info_Value_list,out_path=False)
输入:
Info_Value_list:存储各变量分箱结果(proc_woe_continuous/discrete的返回值)的List.
out_path:指定的分箱结果存储路径,输出为csv文件
特征转换:
得到分箱及woe,iv结果后,对原数据进行woe转换,其实就是用woe值去替换原来的。主要用以下函数
woe_trans(dvar,civ): replace the var value with the given woe value
输入:
dvar: 要转换的变量,Series
civ: proc_woe_discrete或proc_woe_discrete输出的分箱woe结果,自定义的InfoValue类
输出:
var: woe转换后的变量,Series