参考:https://www.cnblogs.com/robert-dlut/p/9824346.html
Embeddings from Language Model
一、引入
ELMO不同于glove,word2vec,后者们的思想是对于一个词语,用一个预训练好的模型,把一个词语变成一个固定不变的词向量表示,固定不变的意思就是,一旦我确定好了我的模型,确定好了我的语料库,那么这个词即将变成哪一个词向量表示就确定了。然而ELMO不是这样的,对于‘apple’一词,ELMO认为当它是指苹果公司的时候是一种词向量表示,但当它是指吃的水果的时候又是另一种词向量表示,ELMO可以解决一词多义的问题,因为它是基于long context的,要考虑的是全文的语境,而不是像word2vec之类的基于窗口来训练的。

可以看见,要知道ELMO,就要先去了解一下LSTM,而LSTM又相当于一个比较高级的RNN,解决了一些RNN的一些缺点(long term dependency之类的)。接下来先看一下RNN是在干什么,以及LSTM是怎么解决RNN的问题的。讲完了这些之后,再回头讲ELMO
二、RNN和LSTM
RNN- Recurrent Neural Network循环神经网络
因为神经网络来学习这种序列问题,比如翻译,语音识别等问题,结果并不好,因为首先你不清楚你输入的句子有多长,毕竟训练出来的模型是要可以用在其他句子上的;其次标准的神经网络不能够共享从文本的不同位置学习到的特征,比如说当我们一开始知道了“小明”是个人名,希望随后“小明”再次出现时依然记得它是人名,标准神经网络就做不到共享特征。于是就可以采用循环神经网络RNN来解决这个问题。
比如一句话是“小明和小蓝一起去上学”。对于这个句子,我们知道翻译结果“Xiaoming and Xiaolan go to school ”。RNN如果用作翻译,它是这么处理这个句子的:
首先我们有个初始化的向量,称为$a^{0}$,现在我们开始从左往右开始读原句子,读到“小明”(这就是RNN第一个单元的输入$x^{1}$),然后我们就用“小明”和$a^{0}$一块计算出该单元的隐藏层状态$a^{1}$,这是第一个单元,所以是$a^{1}$,然后这个也可以说是激活值,因为是通过激活函数计算出来的,如下图所示,是RNN中一个单元的计算过程。我们拿到了这个激活值/隐藏层状态$a^{1}$后,有两个作用:
- 输给softmax,计算输出值,也就是通过这个单元,我们希望输出翻译结果“Xiaoming”,在下图中就是$y^{1}$,当然经过softmax输出的应该是概率,那么这里就是“Xiaoming”的概率最大;
- 输给RNN的下一个单元,也就是我们希望输出结果为“and”的这个单元。在这个单元里我们又要做相同的事情了,就是把上一个单元的隐藏状态/激活值$a^{1}$和该单元的输入$x^{2}$即“和”,一起计算出来$a^{2}$,这个$a^{2}$我们又拿来做两件事情:1.预测当前输出值$y^{2}$,2.和输给RNN的下一个单元再次计算$a^{3}$。

RNN存在梯度消失的问题,也就是说RNN的单元太多太长的时候,反向传播时,最前面的参数可能会得到很少甚至几乎没有的更新,这是不科学的,因为这些最前面的单元参数不可以倚老卖老,不能因为你先出现了,你就不做任何改变,你出现得早,不代表你就没有任何错误,即便是最早出现的日心说最后不还是被地心说推翻了,虽然这个过程很悲惨,就是有些人认为老祖宗的就是正确的;然后LSTM就是可以用来解决RNN的梯度消失问题所提出来的一个比较高级比较复杂的的RNN而已。这是二者的关系,先做一个感性的认识,接下来会讲一下LSTM具体是什么样一种机制。
在RNN中可以看到,我们就是对上一个单元的激活值和当前单元的输入值做了一个激活函数,然后输出计算y以及输给下一个单元计算下一个单元的激活值。RNN不太擅长捕捉长期依赖关系,然而在句子中又经常有这种要求,比如:The cat ,which belongs to xiangming, is so lovely.RNN就很难捕捉到is还是are,因为这里的is或are主要取决于The cat 是单数,RNN可能会忘记前面的cat是单数。也就是说IS这个位置依赖于cat这个位置的单词,然而RNN却会忘记,假如中间的定语从句,状语从句更多一些,RNN就更加难做到了。
为什么RNN会出现这个问题,主要是因为太深的神经网络会出现梯度消失或梯度爆炸,梯度爆炸容易被发现和修改,然而梯度消失却不好修正,这个会在深度学习部分再说。
LSTM-long short term memory长短期记忆机制
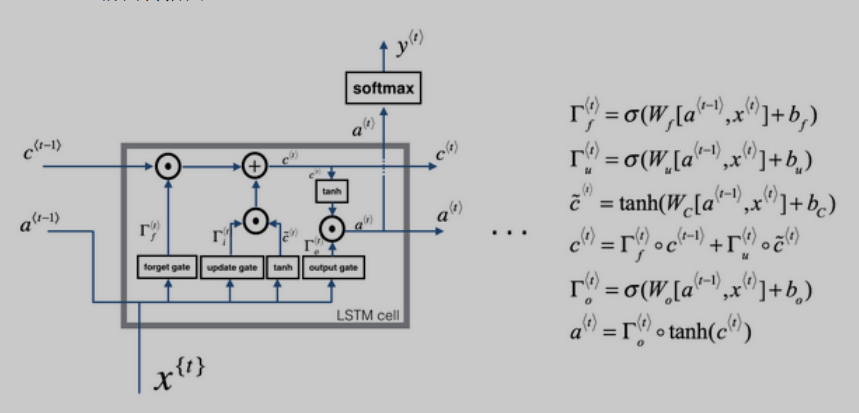
LSTM主要的想法就是增加了一个cell,就是下图的c,现在每个单元除了接受上一个单元的$a^{t-1}$,还要接受$c^{t-1}$,输出给下一单元的除了$a^{t}$,还有$c^{t}$,然而$a^{t}$生成的作用依然是取softmax和给下一个单元,这和RNN一样。大体如此之后,LSTM多了门控机制,有遗忘门,更新门和输出门。首先可以看到门的计算公式,三个门都是用$a^{t-1}$和$x^{t}$的加权和再加上一个激活函数算出来的激活值,只是权重矩阵不同。
遗忘门f和更新门u:这两个门算出来的激活值,可以看到用来计算$c^{t}$,表示我要记住多少过去的东西$c^{t-1}$,以及当前的东西$widetilde{c}$。
输出门o:用来计算$a^{t}$,计算$a^{t}$的时候,刚好需要用到遗忘门和更新门算出来的$c^{t}$
这里要注意一下$c^{t}$和$widetilde{c}$的区别,$widetilde{c}$只是当前层新增的“记忆”,而$c^{t-1}$是过去一段时间积累的记忆,$c^{t}$是算上当前层新增的$widetilde{c}$的所有记忆。现在我们只看c的流动这条线,我们可以发现,只要你正确的设置更新门和遗忘门,那么$c^{0}$可以传播到后面很远很远的地方。这就是为什么LSTM可以解决长期依赖问题的原因。
三、ELMO
大概了解了LSTM后,才可以着手学习ELMO,学完ELMO后,又可以将LSTM换成transformer,就可以得到BERT。这是以后会写到的东西。
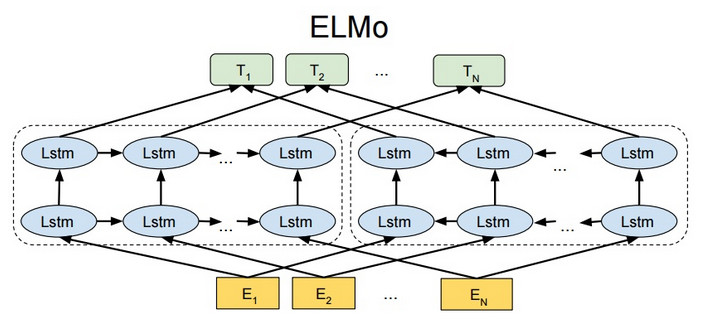
基本上这一张图就可以讲明白ELMO在干什么,首先我们看一下左右两个虚线框,可以发现LSTM的箭头方向是不一样的,左边的叫做前向,右边的叫做后向,前向是通过前面的句子来预测下一个单词;而后向是通过后面的句子来预测前一个句子。这里用的双层LSTM,也叫BiLstm。
下面是前向和后向的数学式子说明:
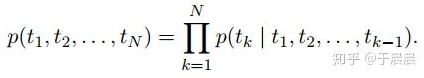
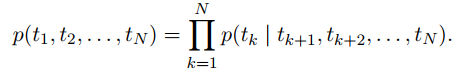
为什么用条件概率来表示,主要是涉及到最初学NLP的时候提到的模型输出的句子可以看做条件概率最大的句子,还提到了n元模型,这里就不展开了。
然后目标函数就取这两个概率乘积的最大似然就可以计算出参数了:
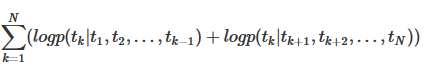
在预训练好这个语言模型之后,ELMo就是根据公式来用作词表示,其实就是把这个双向语言模型的每一中间层进行一个求和。最简单的也可以使用最高层的表示来作为ELMo。然后在进行有监督的NLP任务时,可以将ELMo直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上。