1、acm中1s --> 1e8
2、acm中1e6的字符串题目不能用nlogn
3、nginx管方说并发 5w/s,实际可能2w/s,然后1w个keep-alive仅需要消耗2.5MB内存
4、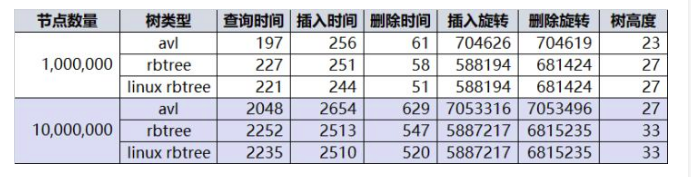 单位ms
单位ms
5、关于为什么需要struct的字节对齐 因为:(可以用预编译命令#pragma pack(n)指定对齐方式)
关乎于CPU的字长是4字节的,也有可能是8字节的,如果你的数据放置在00001111 11110000这样两块之间,如果一次读取的是8字节,就需要两次的读取。
由于CPU的速度比内存快很多,所以读取两次肯定很浪费资源。如果CPU的字长是4,就肯定都是读取两次,没关系。但是世界上的CPU设计不一样,当数据去到
某个字长是8的CPU上面时,就会产生损耗。
6、new和malloc的区别:new是面向对象的产物
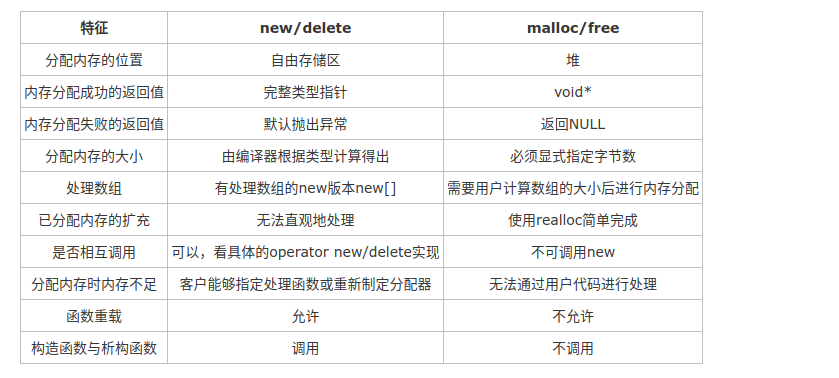
7、计算机加载程序包括哪几个区?
一个由C/C++编译的程序占用的内存分为以下几个部分:
(1)栈区(stack):—由编译器自动分配释放,存放函数的参数值,局部变量的值等。可静态也可动态分配。其操作方式类似于数据结构中的栈。
(2)堆区(heap):一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。动态分配。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
(3)全局区(静态区):—程序结束后由系统释放,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域;未初始化的全局变量和静态变量在相邻的另一块区域(BSS,Block Started by Symbol),在程序执行之前BSS段会自动清0。
(4)文字常量区:—程序结束后由系统释放,常量字符串就是放在这里的。
(5)程序代码区:—存放函数体的二进制代码
没有初始化的全局变量 = 0,因为他放在与静态变量的相邻一个区域,BSS段,而BSS段一开始就设置为0
8、实现strcpy有什么要注意的地方:
①、源地址要用const修饰,不能被修改了
②、检查是否NULL
③、看看是否有内存重叠,就是 000111 111000这样重叠起来,这样就会修改了源地址
9、斐波那契数列 f[n] = f[n - 1] + f[n - 2]
优化推一下发现以下的也成立:
f(2n) = f(n) * f(n - 1) + f(n) * f(n + 1)
f(2n+1) = f(n) * f(n) + f(n + 1)*f(n + 1)
这样算复杂度是logn然后执行的大数乘法次数也少,所以速度比矩阵快速幂快
10、linux内核namespace是怎么实现的。(大概就是把PID,NET,IPC, USER, UTS, MNT都虚拟出来)
11、为什么需要四次挥手?因为客户端发送一个FIN给服务端,仅仅表示客户端没有数据要发送了,不代表服务器发送的数据都传送完成了。所以服务器还是要挥手
12、go语言有什么有点?
②、强制统一的代码风格。
③、静态编译,可以放去某一个同类系统使用。
④、多值函数放回,defer机制 ---> 代替了传统的try...cache
⑤、自带main_test.go文件,可以开发者自己写单元测试用例
①、G++和GCC都可以编译.c文件,但是G++编译.c文件的时候,是会调用gcc编译的。
②、GCC不一定可以编译.cpp文件,GCC是可以像G++一样生成.i文件的,但是继续gcc编译.i文件的时候并不能产生可执行文件,因为提示找不到cout函数,所以gcc无法和cpp的库函数连接。生成了.o文件还是不行,也是原来的问题,没有找到cpp的库函数
①、写扩散:自己每发布一条信息,就会去忘自己的follower里面的inbox(收件箱)表插入一条信息。然后本人只需要读取信息就好了
②、读扩散:写在自己的outbox里面,这样每个人去读取他关注的人的outbox就可以了。
总结:所以如果自己的follower有点大,那么推送去所有follower显然不实际,所以就直接用读扩散,让follower过来读取。也就是混合模式
15、假如一个cache机器,key是8byte,value是16byte,那么一个就是需要24byte,那么1GB可以存下500w的key


class LRUCache { int cap; unordered_map<int, list<pair<int, int>>::iterator> m_map; list<pair<int, int>> m_list; public: LRUCache(int capacity) : cap(capacity) { } int get(int key) { auto res = m_map.find(key); if (res != m_map.end()) { int ans = res->second->second; m_list.splice(m_list.begin(), m_list, res->second); return ans; } else { return -1; } } void put(int key, int value) { auto res = m_map.find(key); if (res != m_map.end()) { res->second->second = value; m_list.splice(m_list.begin(), m_list, res->second); } else { if (m_list.size() == cap) { int k = m_list.back().first; m_map.erase(k); m_list.pop_back(); } m_list.emplace_front(key, value); m_map[key] = m_list.begin(); } } }; /** * Your LRUCache object will be instantiated and called as such: * LRUCache obj = new LRUCache(capacity); * int param_1 = obj.get(key); * obj.put(key,value); */
17、随机生成等概率数字,抽奖算法,RAND_MAX去掉尾数算法
不能确保一定能生成1:2:3:4,模拟生成。
#include <bits/stdc++.h> #include <sys/time.h> using namespace std; class AD { private: vector<int> p; public: AD(const vector<int> &_p) { p = _p; srand(time(NULL)); } int rand_zero2n(int n) { // 生成[0, n)随机数 int limit = RAND_MAX - (RAND_MAX % n); // 除去尾数 int t = rand(); while (t > limit) t = rand(); return t % n; } int get_one() { int sum_p = 0; for (int i = 0; i < (int)p.size(); ++i) { sum_p += p[i]; } for (int i = 0; i < (int)p.size(); ++i) { int result = rand_zero2n(sum_p); if (result < p[i]) { return i + 1; } else { sum_p -= p[i]; } } } }; int c[222]; void work() { int _p[] = {1, 2, 3, 4}; AD *test = new AD(vector<int>(_p, _p + 4)); for (int i = 0; i < 10000000; ++i) { c[test->get_one()]++; } for (int i = 1; i <= 4; ++i) { printf("%d : 出现 %d 次 ", i, c[i]); } /** * n = 10000 * g++ main.cpp -o main && ./main 1 : 出现 988 次 2 : 出现 1918 次 3 : 出现 3039 次 4 : 出现 4055 次 */ /** * n = 10000000 * g++ main.cpp -o main && ./main 1 : 出现 999337 次 2 : 出现 1999830 次 3 : 出现 3000122 次 4 : 出现 4000711 次 */ } int main() { work(); return 0; }
18、回文矩阵中输出某个矩阵,规律可寻,外层数字有4n-4个,第二层有4n-12个,第三层有4n-20个..........一直下去。
#include <bits/stdc++.h> using namespace std; typedef unsigned long long int ULL; class Square { private: long long int n; long long int x, y; int m; public: Square(const long long int _n, const long long int _x, const long long int _y, const int _m) : n(_n), x(_x), y(_y), m(_m) { } long long int get_cir(long long int x, long long int y) { long long t1 = min(x, y); long long t2 = n - max(x, y) + 1; return min(t1, t2); } long long get_val(long long int x, long long int y) { long long int cir = get_cir(x, y); long long int begin = (cir - 1) * 4 * n - 4 * (cir - 1) * (cir - 1) + 1; long long d = n - 2 * cir + 1; if (x == cir) { return begin + y - cir; } else if (y == n - cir + 1) { return begin + d + x - cir; } else if (x == n - cir + 1) { return begin + d + d + (n - cir + 1) - y; } else { return begin + d + d + d + (n - cir + 1) - x; } } void print() { for (long long i = x; i <= x + m - 1; ++i) { for (long long j = y; j <= y + m - 1; ++j) { printf("%5lld", get_val(i, j)); } printf(" "); } } }; void work() { long long int n = 5; long long x = 2, y = 2; int m = 2; Square *test = new Square(n, x, y, m); test->print(); /** * output: * 17 18 * 24 25 */ } int main() { work(); return 0; }
19、数据库中的ACID和实现(原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。)
1、为了实现一致性,需要写日志,可以对于容灾进行及时的undo和redo
2、为了实现不是因为容灾而导致的数据不一致,比如高并发拿数据问题,实现了隔离性,需要对操作进行枷锁。乐观锁 | 悲观锁,然后可能有死锁的情况,所以就需要死锁检测和二阶段锁协议。
3、
20、如何实现一个锁?
1、把中断过程打断。(就是不会转移到其他地方操作),这种太慢拉,,,,,
2、使用test and set
但是这样可以解决的是单核问题,多核问题,test and set还是不行的。。因为他会并行处理test and set。。解决方法是采用:锁内存总线的机制
21、乐观锁、悲观锁
乐观锁:每次都认为乐观,不会有其他人去打扰。所以数据库表加一个version,代码层面上每次也把version取出来,然后+1,准备插进去的时候,又拿版本出来,如果这个时候的版本是上一次的版本一样,则认为没修改,可以update。
也可以基于timestamp的,这种适合于读多写少的
悲观锁:每次都锁一下。
22、联合索引
单列索引:用a建立,b建立,c建立,查询 a and b是不会走索引的,查询a or b是会走索引的。
联合索引:用abc三个一起建立。
查询:
①、a and b 可以走索引
②、b and c 不可以走索引
③、a or c 不可以走索引
④、a and c 可以走索引
最后注意索引不能多开,一是增加磁盘消耗,二是更新会变慢
23、redis中清除key的策略,
业界中有三种:
1、注册回调函数。
2、加入一个timestamp,查询的时候如果超时了,则删除。
3、在2的基础上,加上一个全局回调函数,用来定时清除过期的key
23、进程和线程的区别
25、引用的内部实现:1、别名机制。2、变成:int &*p <====> int * const p,表明指针指向的东西不能变。
他就是一个指针常量,这个指针不能指向其他地方,但是同时又可以改它指向的东西
26、1145 --> 49k
27、进程线程切换:3--5us,协成100ns 30倍。线程需要的栈 ulimit -a可以看 stack size,8M,协成2KB. go生成协成的时候就需要400ns.