一、集群环境准备工作
1、修改主机名
在root 账户下 vi /etc/sysconfig/network 或者 sudo vi /etc/sysconfig/network
2、设置系统默认启动级别
在 root 账号下输入 vi /etc/inittab 将默认的5改为3即可
3、配置hadoop用户 sudoer权限
在 root 账号下,命令终端输入: vi /etc/sudoers
添加一行 hadoop ALL=(ALL) ALL
4、配置IP
5、关闭防火墙
查看防火墙状态: service iptables status
关闭防火墙: service iptables stop
开启防火墙: service iptables start
重启防火墙: service iptables restart
关闭防火墙开机启动: chkconfig iptables off
开启防火墙开机启动: chkconfig iptables on
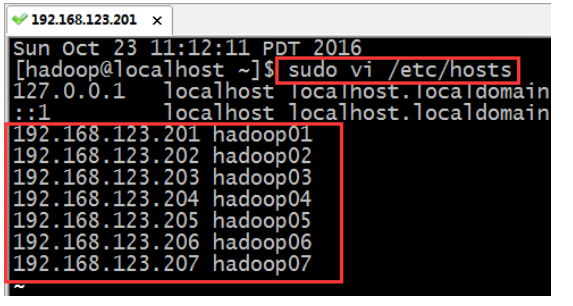
6、添加内网域名映射
vi /etc/hosts
7、安装JDK

做完以上步骤就开始克隆虚拟机了
二、hadoop集群安装
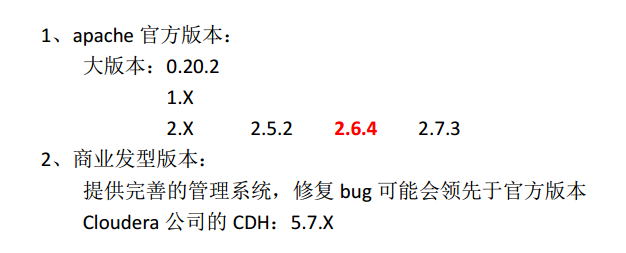
1、hadoop版本选择
2、同步服务器时间 设置crontab
ntpdate 202.120.2.101
3、配置免密登录
4、hadoop分布式集群安装(伪分布式)
4、hadoop分布式集群安装
总共三个datanode,设置副本数为2,是为了观察数据块分布方便
集群规划:
HDFS YARN
hadoop01 NameNode+DataNode NodeManager
hadoop02 DataNode+SecondaryNameNode NodeManager
hadoop03 DataNode NodeManager+ResourceManager
hadoop01是HDFS的主节点(namenode进程)、hadoop03是Yarn的主节点(ResourceManager进程)
具体安装步骤:




三、集群初步使用
1、hadoop集群启动
DFS 集群启动: sbin/start-dfs.sh
DFS 集群关闭: sbin/stop-dfs.sh
YARN 集群启动: sbin/start-yarn.sh
YARN 集群启动: sbin/stop-yarn.sh
2、HDFS初步使用
查看集群文件: hadoop fs –ls /
上传文件: hadoop fs –put filepath destpath
下载文件: hadoop fs –get destpath
创建文件夹: hadoop fs –mkdir /hadoopdata
查看文件内容: hadoop fs –cat /hadoopdata/mysecret.txt
3、mapreduce 初步使用

四、hadoop集群安装高级知识
1、为什么会有hadoop HA机制呢
HA: High Available,高可用
在 Hadoop 2.0 之前,在 HDFS 集群中 NameNode 存在单点故障 (SPOF:A single point of failure)。 对于只有一个 NameNode 的集群,如果 NameNode 机器出现故障(比如宕机或是软件、硬件 升级),那么整个集群将无法使用,直到 NameNode 重新启动
那如何解决呢?
HDFS 的 HA 功能通过配置 Active/Standby 两个 NameNodes 实现在集群中对 NameNode 的 热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方 式将 NameNode 很快的切换到另外一台机器。
在一个典型的 HDFS(HA) 集群中,使用两台单独的机器配置为 NameNodes 。在任何时间点, 确保 NameNodes 中只有一个处于 Active 状态,其他的处在 Standby 状态。其中 ActiveNameNode 负责集群中的所有客户端操作, StandbyNameNode 仅仅充当备机,保证一
旦 ActiveNameNode 出现问题能够快速切换。
为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog),需提 供一个共享存储系统,可以是 NFS、 QJM( Quorum Journal Manager)或者 Zookeeper, Active Namenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写入,则
读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持基本一致,如此这般,在紧急情况下 standby 便可快速切为 active namenode。为了实现快速切换, Standby 节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标, DataNode 需要配置
NameNodes 的位置,并同时给他们发送文件块信息以及心跳检测。 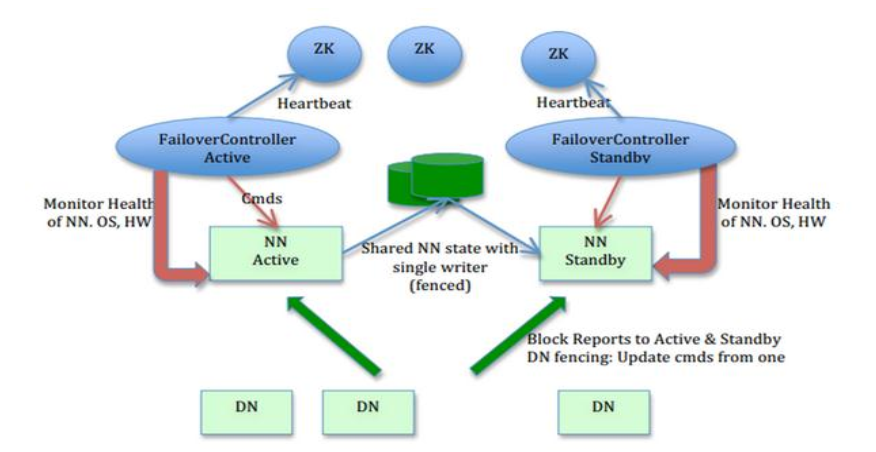
2、思考问题:secondarynamenode 和standbynamenode的区别?
Secondary NameNode不是NameNode的备份。它的作用是:定期合并fsimage与edits文件,并推送给NameNode,以及辅助恢复NameNode。
standbynamenode仅仅充当active的备机,保证一 旦 ActiveNameNode 出现问题能够快速切换,并且Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog)是同步的
3、hadoop配置机架感知
Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。这样如果本地数据损坏,节点可以从同一机架内的相邻节点拿到数据,速度肯定比从跨机架节点上拿数据要快;
同时,如果整个机架的网络出现异常,也能保证在其它机架的节点上找到数据。为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,
那么客户端也将首先读本地数据中心的副本。那么Hadoop是如何确定任意两个节点是位于同一机架,还是跨机架的呢?答案就是机架感知。
默认情况下,Hadoop的机架感知是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,
此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,
成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务
如何配置:http://blog.csdn.net/l1028386804/article/details/51935169
4、hadoop Fedaration
(1)为什么要有Fedaration机制呢
在 Hadoop 2.0 之前, HDFS 的单 NameNode 设计带来很多问题,包括单点故障、内存受限, 制约集群扩展性和缺乏隔离机制(不同业务使用同一个 NameNode 导致业务相互影响)等。为了解决这些问题,除了用基于共享存储的 HA 解决方案,我们还可以用 HDFS 的 Federation
机制来解决这个问题。
(2)什么是Fedaration机制?
HDFS Federation 是指 HDFS 集群可同时存在多个 NameNode。这些 NameNode 分别管理一部 分数据,且共享所有 DataNode 的存储资源。
这种设计可解决单 NameNode 存在的以下几个问题:
1、 HDFS 集群扩展性。多个 NameNode 分管一部分目录,使得一个集群可以扩展到更多节 点,不再像 1.0 中那样由于内存的限制制约文件存储数目。
2、 性能更高效。多个 NameNode 管理不同的数据,且同时对外提供服务,将为用户提供 更高的读写吞吐率。
3、 良好的隔离性。用户可根据需要将不同业务数据交由不同 NameNode 管理,这样不同 业务之间影响很小。
注意问题: HDFS Federation 并不能解决单点故障问题,也就是说,每个 NameNode 都存在 在单点故障问题,你需要为每个 namenode 部署一个 backup namenode 以应对 NameNode 挂掉对业务产生的影响。
补充:
1、数据丢失 hadoop会处于安全模式
强制退出安全模式命令 bin/hadoop dfsadmin -safemode leave