一 . mysql 多表查询
之前我们有接触到的mysql单表查询,现在遇见的就是mysql的单表查询方式,首先说一下,我们写项目一般都会建一个数据库那数据库里面是不是存了好多张表呢,不可能把所有的数据都放到一张表里面多部队,肯定是要来分表存储数据的,这样节省空间,数据的组织结构更清晰,解耦和程序更高,这些表本质上面是不是一个整体呢。
首先,我们打开mysql,我们得先创建一个表,然后才能查询,create table XXX (输入你想加入的表格内容);然后再创建一个表
create table XXX (输入你想加入的表格内容);给两个表都插入一些数据insert into XXX values(想要插入的内容); insert into XXX values(想要插入的内容); # 注意输入的文件名不要重复,最好也是简单点的,便于输入输出, 输入好了之后我们要查看表结构和数据:desc XXX;desc XXX; # 养成良好的习惯,减少错误的产生 select * from XXX:查看当前表的结构及所有数据。
二 . 多表连接查询
结构:select 字段列表 from 表1 inner | left | right 表2 on 表1.字段 = 表2.字段,基本的结构差不多就是这样
笛卡儿积现象解释图:
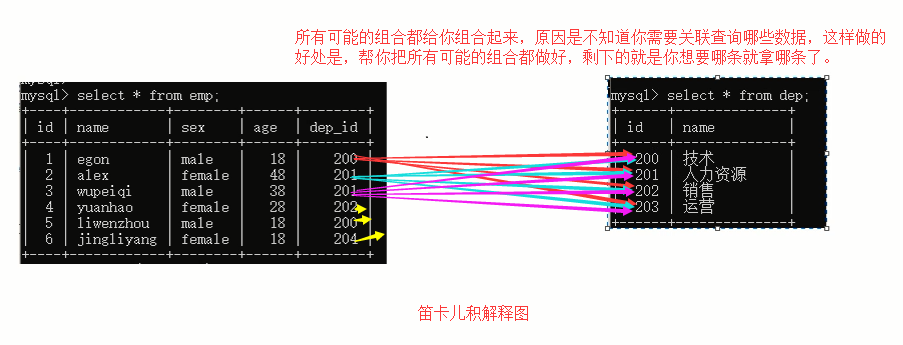
咱们为了更好的管理数据,为了节省空间,为了数据组织结构更清晰,将数据拆分到了不同表里面,但是本质上是不是还是一份数据,一份重复内容很多的很大的数据,所以我们即便是分表了,但是咱们是不是还需要找到一个方案把两个本来分开的表能够合并到一起来进行查询,那你是不是就可以根据部门找员工,根据员工找部门了,对不对,但是我们合并两个表的时候,如何合并,根据什么来合并,通过笛卡儿积这种合并有没有浪费,我们其实想做的是不是说我们的员工表中dep_id这个字段中的数据和部门表里面的id能够对应上就可以了,因为我们知道我们设计表的时候,是通过这两个字段来给两个表建立关系的,对不对,看下图:

外连接之左连接:select XXX1.id ,XXX1 name ,XXX2.name as 表中的名称栏 from XXX1 left join XXX2 on XXX1.dep_id = XXX2.id;
外连接之右连接:select XXX1.id ,XXX1.nama ,XXX2.name as 表中的名称栏 from XXX1 left join XXX2 on XXX1.dep_id =XXX2.id;
# 别看两个连接的长度不一样,但是结构是一模一样的,只是把左改成了右,将右变成了左,其本质就是在内连接的基础上增加左边有右边没有的结果或者在内连接的基础上增加右边有左边没有的结果。
全外连接:本质就是使用union来将外连接的左连接和右连接合并起来,显示左右两个表全部记录
select XXX1.id ,XXX1 name ,XXX2.name as 表中的名称栏 from XXX1 left join XXX2 on XXX1.dep_id = XXX2.id,
union
select XXX1.id ,XXX1.nama ,XXX2.name as 表中的名称栏 from XXX1 left join XXX2 on XXX1.dep_id =XXX2.id;
# 注意 union 与 union all 的区别:union会去掉相同的内容,因为union会去掉相同的记录,因为union all 是将左
表和右表进行合并,所以右重复的记录,通过union 就可以将重复的记录去重了。
符合条件连接查询
以内连接的方式查询XXX1和XXX2表,并且建立条件:比如age>25,那么就拿到了大于25岁所在部门的所有员工。
子查询:子查询其实就是将你的一个查询结果用括号括起来,这个结果也是一张表,就可以将它交给另外一个sql 语句,作为它的一个查询一句来进行操作。
select * from XXX1 inner join department on XXX1.内容项1 = department.项1
# 然后根据连表的结果进行where 过滤,将select * 改成 select XXX1.内容项2
# 1.子查询是将一个查询语句潜逃在另一个查询与剧中。
# 2. 内层查询语句的查询结果,而可以为外层查询语句提供查询条件。
# 3. 子查询中可以包含:in ,not in , any , all, exists 和 not exists 等关键字。
# 4. 还可以包含比较运算符:= ,!= ,> , < 等
三 . 子查询
1.带IN关键字的子查询:IN关键字,顾名思义,带关键字的查询,子查询的思路和解决问题一样,先解决一个然后拿着这个的结果再去解决另外一个问题,连接表的思路是将两个表关联在一起,然后在进行group by ,having等操作,两者的思路是不一样的。
2.比较运算符:=、!=、>、>=、<、<=、<>,比较运算符子查询
#查询大于所有人平均年龄的员工名与年龄
mysql> select name,age from emp where age > (select avg(age) from emp);
+---------+------+
| name | age |
+---------+------+
| alex | 48 |
| wupeiqi | 38 |
+---------+------+
2 rows in set (0.00 sec)
#查询大于部门内平均年龄的员工名、年龄
select t1.name,t1.age from emp t1
inner join
(select dep_id,avg(age) avg_age from emp group by dep_id) t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age;
3.带 exists 关键字的子查询
exists关键字表示存在,在使用 exists关键字时,内层查询语句不返回查询的记录。而是返回一个假值,True或 False,当返回 True,外层查询语句将进行查询;当返回值为 False时, 外层查询语句不进行查询。还可以写 not exists, 和 exists 的效果是反的。
#department表中存在dept_id=203,Ture
mysql> select * from employee
-> where exists
-> (select id from department where id=200);
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
#department表中存在dept_id=205,False
mysql> select * from employee
-> where exists
-> (select id from department where id=204);
Empty set (0.00 sec)