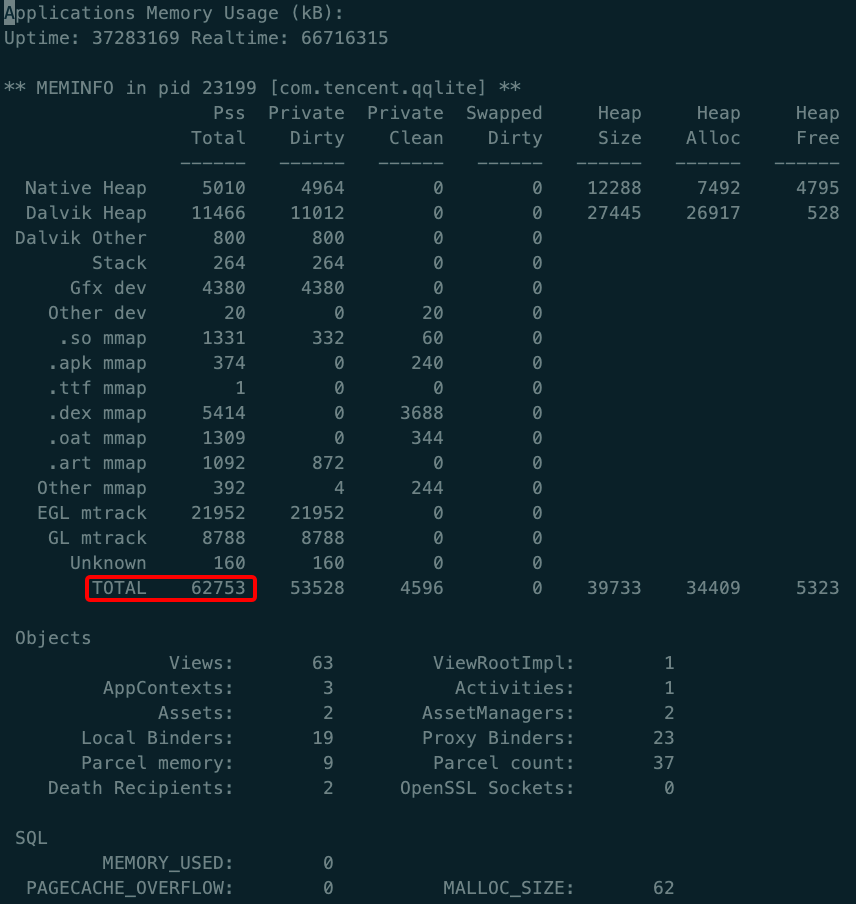
性能测试中,内存是一个不可或缺的方面。比如说在跑 Monkey 的过程中,如何准确持续的获取到内存数据就显得尤为重要。
今天分享一个脚本,可以在给定时间内持续监控内存,最后输出成一份 CSV 文件,通过 Excel 的插入图表功能可以形成一副内存走势图。
脚本中最关键的两个步骤如下,其余看代码吧(注释很详细):
- 通过 adb 命令获取内存文件
- 通过 Python 脚本解析内存文件,取出其中的 "TOTAL" 值
run.sh
#!/usr/bin/env bash
# Description: 获取内存TOTAL值
# How to use: sh +x run.sh <package_name> <time>
# 新建输出文件夹
function init_data() {
if [[ ! -d ${OUTPUT} ]];then
mkdir -p ${OUTPUT}
fi
touch ${MEMINFO_FILE}
}
# 将日期追加入MEMINFO_FILE
# 将内存信息追加入MEMINFO_FILE
function dump_memory_info() {
echo "TIME FLAG:" `date "+%Y-%m-%d %H:%M:%S"` >> ${1}
adb shell dumpsys meminfo ${2} >> ${1}
}
# 每隔一分钟拉取一次内存信息
function start_monitor() {
for((i=1;i<=${1};i++));
do
dump_memory_info ${2} ${3}
sleep 60
done
}
# 处理"TOTAL:"格式的内存文件
# 调用report脚本,传入参数MEMINFO_FILE
# 将logs/csv/t_u.csv文件拷贝并重命名为MEMINFO_CSV_FILE
# 删除"logs"文件夹,减少硬盘空间占用
function report_with_colon() {
sh +x report.sh ${1}
cp -p logs/csv/t_u.csv ${2}
rm -r logs
}
# 处理"TOTAL"格式的内存文件
function report_without_colon() {
sh +x report_no_colon.sh ${1}
cp -p logs/csv/t_u.csv ${2}
rm -r logs
}
# 调用report脚本,输出csv文件
function report_memory_info() {
TOTAL_TIME=$(cat ${1} | grep "TOTAL:" -c)
if [[ ${TOTAL_TIME} != 0 ]]; then
report_with_colon ${1} ${2}
else
report_without_colon ${1} ${2}
fi
}
# 运行脚本时传入的第一个参数:包名
PACKAGE_NAME=$1
# 第二个参数:运行时间(分钟)
TIME=$2
# 绝对路径
WORKSPACE=`pwd`
# 输出文件夹
OUTPUT=${WORKSPACE}/output_memory
# 内存文件
MEMINFO_FILE=${OUTPUT}/meminfo.txt
MEMINFO_CSV_FILE=${OUTPUT}/meminfo.csv
# 删除"output_memory",避免数据混淆
if [[ -d "output_memory" ]]; then
rm -r output_memory
fi
# 开始调用方法
init_data
start_monitor ${TIME} ${MEMINFO_FILE} ${PACKAGE_NAME}
report_memory_info ${MEMINFO_FILE} ${MEMINFO_CSV_FILE}
report.sh
#!/usr/bin/env bash
# Description: 提取meminfo.txt中的TOTAl值并输出到CSV文件(适用于'TOTAL:'格式的内存文件)
# 根据dumpsys meminfo后的文件中不同的标签, 设定文件名
# 因为标签诸如'.ttf mmap'等, 中间有空格, 不适合直接做文件名
getMemFileName()
{
local tag=$1
case ${tag} in
"Native")
fileName="native_meminfo.txt"
;;
"Dalvik")
fileName="dalvik_meminfo.txt"
;;
"Cursor")
fileName="cursor_meminfo.txt"
;;
"Other dev")
fileName="otherdev_meminfo.txt"
;;
"Ashmem")
fileName="ashmem_meminfo.txt"
;;
".so mmap")
fileName="so_meminfo.txt"
;;
".jar mmap")
fileName="jar_meminfo.txt"
;;
".apk mmap")
fileName="apk_meminfo.txt"
;;
".ttf mmap")
fileName="ttf_meminfo.txt"
;;
".dex mmap")
fileName="dex_meminfo.txt"
;;
"Other mmap")
fileName="other_meminfo.txt"
;;
"Unknown")
fileName="unknown_meminfo.txt"
;;
"TOTAL:")
fileName="total_meminfo.txt"
;;
*)
;;
esac
echo ${fileName}
}
# 解析MonkeyTest完成后的meminfo.txt
# 按列读取, 1, 2, 3, 4, 5列分别对应:Pss, SharedDirty, PrivateDirty, HeapSize, HeapFree
splitMeminfo()
{
local fileName=$1
# 删除VALUE字符串中以分隔符“.”匹配的右边字符,保留左边字符。${VALUE%.*}
local folderName=${fileName%.*}
mkdir logs/${folderName}
awk '{print $1}' logs/${fileName} > logs/${folderName}/Pss
awk '{print $2}' logs/${fileName} > logs/${folderName}/SharedDirty
awk '{print $3}' logs/${fileName} > logs/${folderName}/PrivateDirty
awk '{print $4}' logs/${fileName} > logs/${folderName}/HeapSize
awk '{print $5}' logs/${fileName} > logs/${folderName}/HeapFree
}
# 将MonkeyTest完成后的meminfo.txt中的tag去掉
# 如: PSS 234 222 333 555 0 -> 234 222 333 555 0
# 原因:统一成5列数据, 方便'splitMeminfo'按列读取数据
removeTag()
{
local fileName=$1
local tag=$2
case ${tag} in
"Native")
# 删除第一列,然后输出到logs/native.txt
awk '{$1="";print}' ${fileName} > logs/native.txt
splitMeminfo native.txt
;;
"Dalvik")
awk '{$1="";print}' ${fileName} > logs/dalvik.txt
splitMeminfo dalvik.txt
;;
"Cursor")
awk '{$1="";print}' ${fileName} > logs/cursor.txt
splitMeminfo cursor.txt
;;
"Other dev")
awk '{$1=""; $2="";print}' ${fileName} > logs/otherdev.txt
splitMeminfo otherdev.txt
;;
"Ashmem")
awk '{$1="";print}' ${fileName} > logs/ashmem.txt
splitMeminfo ashmem.txt
;;
".so mmap")
awk '{$1=""; $2="";print}' ${fileName} > logs/sommap.txt
splitMeminfo sommap.txt
;;
".jar mmap")
awk '{$1=""; $2="";print}' ${fileName} > logs/jarmmap.txt
splitMeminfo jarmmap.txt
;;
".apk mmap")
awk '{$1=""; $2="";print}' ${fileName} > logs/apkmmap.txt
splitMeminfo apkmmap.txt
;;
".ttf mmap")
awk '{$1=""; $2="";print}' ${fileName} > logs/ttfmmap.txt
splitMeminfo ttfmmap.txt
;;
".dex mmap")
awk '{$1="";$2="";print}' ${fileName} > logs/dexmmap.txt
splitMeminfo dexmmap.txt
;;
"Other mmap")
awk '{$1="";$2="";print}' ${fileName} > logs/othermmap.txt
splitMeminfo othermmap.txt
;;
"Unknown")
awk '{$1="";print}' ${fileName} > logs/unknown.txt
splitMeminfo unknown.txt
;;
"TOTAL:")
awk '{$1="";print}' ${fileName} > logs/total.txt
splitMeminfo total.txt
;;
*)
;;
esac
}
# 生成.csv文件, 方便网页中用js读取, 并传值給HighCharts
# 将splitMeminfo中生成的多个文件, 列转行
# 格式:Pss, 234,333,444,556,444......
getCSVFile()
{
mkdir logs/csv
local meminfo_Files=("Pss" "SharedDirty" "PrivateDirty" "HeapSize" "HeapFree")
# 数组长度
local count=${#meminfo_Files[@]}
for((i=0;i<$count;i++))
do
local item=${meminfo_Files[$i]}
echo "Categories" >> logs/csv/${item}.csv
for data in `find ./ -name "${item}"`
do
# 删除VALUE字符串中以分隔符“.”匹配的右边字符,保留左边字符。${VALUE%.*}
seriesName=${data%/*}
# 删除VALUE字符串中以分隔符“.”匹配的左边字符,保留右边字符。${VALUE##*.}
seriesName=${seriesName##*/}
csvline=${seriesName}
for line in `cat ${data}`
do
csvline=${csvline},${line}
done
echo ${csvline} >> logs/csv/${item}.csv
sed -i '' "s/,//g" logs/csv/${item}.csv
done
done
}
# 第一列的所有参数
MEMINFO_ARGS=("Native" "Dalvik" "Cursor" "Other dev" "Ashmem" ".so mmap" ".jar mmap" ".apk mmap" ".ttf mmap" ".dex mmap" "Other mmap" "Unknown" "TOTAL:")
# 从run.sh传入的参数
MEMINFO_File=${1}
# MEMINFO_ARGS的长度(length)
count=${#MEMINFO_ARGS[@]}
# 创建logs/, 用以存放日志
mkdir logs
# 解析日志
for((i=0;i<$count;i++));
do
# 调用getMemFileName方法,传入参数MEMINFO_ARGS,返回文件名
fileName=`getMemFileName "${MEMINFO_ARGS[$i]}"`
# 输出包含${MEMINFO_ARGS[$i]}的行
awk /"${MEMINFO_ARGS[$i]}"/'{print}' ${MEMINFO_File} > logs/${fileName}
removeTag logs/${fileName} "${MEMINFO_ARGS[$i]}"
done
# 将分析过的日志转换成csv文件
getCSVFile
# 将时间取出来放到logs/time文件中
grep 'TIME FLAG:' ${MEMINFO_File} > logs/logtime
cat logs/logtime | while read line
do
echo ${line#*:} >> logs/time
done
# 处理完所有行,输出行数
line_count=`awk 'END{print NR}' logs/total/Pss`
# 提取时间和TOTAL值,输出到t_u.csv文件
echo "Time,TOTAL" > logs/csv/t_u.csv
for ((j=1;j<=${line_count};j++));
do
total_mem=`tail -n ${j} logs/total/Pss | head -n 1`
time_mem=`tail -n ${j} logs/time | head -n 1`
echo "${time_mem},${total_mem}" >> logs/csv/t_u_bk.csv
done
line_count=`awk 'END{print NR}' logs/csv/t_u_bk.csv`
for ((k=1;k<=${line_count};k++));
do
total_line=`tail -n ${k} logs/csv/t_u_bk.csv | head -n 1`
echo "$total_line" >> logs/csv/t_u.csv
done
注意:
部分手机获取到的内存文件会同时包含 "TOTAL" 和 "TOTAL:" 字段,通过替换 report.sh 脚本中的 "TOTAL" 进行区分即可
欢迎关注微信公众号"测试开发Stack"