主要知识
1、document数据格式
json
2、电商网站商品管理案例:背景介绍
3、简单的集群管理
(1) GET /_cat/health?v
(2) 为什么现在会处于一个yellow状态?
(3) GET /_cat/indices?v
(4) 创建索引:PUT /test_index?pretty
(5) 删除索引:DELETE /test_index?pretty
4、商品的CRUD操作(document CRUD操作)
(1) PUT /index/type/id
{
"json数据"
}
(2) GET /index/type/id
(3) PUT /index/type/id
(4) POST /index/type/id/_update
(5) DELETE /index/type/id
1、document数据格式
面向文档的搜索分析引擎
(1)应用系统的数据结构都是面向对象的,复杂的
(2)对象数据存储到数据库中,只能拆解开来,变为扁平的多张表,每次查询的时候还得还原回对象格式,相当麻烦
(3)ES是面向文档的,文档中存储的数据结构,与面向对象的数据结构是一样的,基于这种文档数据结构,es可以提供复杂的索引,全文检索,分析聚合等功能
(4)es的document用json数据格式来表达
假入有如下两个类,
class Employee(object): def __init__(self,email,first_name,last_name,info,join_date): self.email=email self.first_name=first_name self.last_name=last_name self.emplyee_info=info # EmployeInfo类的实例 self.join_date=join_date
class EmployeeInfo(object): def __init__(self,bio,age,interests): self.bio=bio #性格 self.age=age self.interests=interests #爱好 zhang_san_info = EmployeeInfo("curious and modest",30,[ "bike", "climb" ]) zhang_san =Employee("zhangsan@sina.com","san","zhang",zhang_san_info,"2017/01/01")
employee对象:里面包含了Employee类自己的属性,还有一个EmployeeInfo对象,要把这两个类的数据存入数据库,如果用关系型数据库,就必须用到两张表:employee表,employee_info表,将employee对象的数据重新拆开来,变成Employee数据和EmployeeInfo数据
employee表:email,first_name,last_name,join_date,4个字段
employee_info表:bio,age,interests,3个字段;此外还有一个外键字段,比如employee_id,关联着employee表.这样存取储很不方便.
如果是用ES的话,数据就是如下格式:
{
"email": "zhangsan@sina.com",
"first_name": "san",
"last_name": "zhang",
"info": {
"bio": "curious and modest",
"age": 30,
"interests": [ "bike", "climb" ]
},
"join_date": "2017/01/01"
}
到此,我们就明白了es的document数据格式和数据库的关系型数据格式的区别
2、电商网站商品管理案例背景介绍
有一个电商网站,需要为其基于ES构建一个后台系统,提供以下功能:
(1)对商品信息进行CRUD(增删改查)操作
(2)执行简单的结构化查询
(3)可以执行简单的全文检索,以及复杂的phrase(短语)检索
(4)对于全文检索的结果,可以进行高亮显示
(5)对数据进行简单的聚合分析
3、简单的集群管理
(1)快速检查集群的健康状况
es提供了一套api,叫做cat api,可以查看es中各种各样的数据
语法:
GET /_cat/health?v
加上?v的目的是为了显示表头信息
启动一个节点的情况
|
epoch |
timestamp |
cluster |
status |
node.total |
node.data |
shards |
pri |
relo |
init |
unassign |
pending_tasks |
max_task_wait_time |
active_shards_percent |
|
1488006741 |
15:12:21 |
elasticsearch |
yellow |
1 |
1 |
1 |
1 |
0 |
0 |
1 |
0 |
- |
50.00% |
启动两个节点的情况
|
epoch |
timestamp |
cluster |
status |
node.total |
node.data |
shards |
pri |
relo |
init |
unassign |
pending_tasks |
max_task_wait_time |
active_shards_percent |
|
1.49E+09 |
15:18:33 |
elasticsearch |
green |
2 |
2 |
2 |
1 |
0 |
0 |
0 |
0 |
- |
100.00% |
如何快速了解集群的健康状况?green、yellow、red?
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
(2)为什么现在会处于一个yellow状态?
我们现在就一个笔记本电脑,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配5个primary shard和5个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana(在5601端口监听)自己建立的index是1个primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动。
做一个小实验:此时只要启动第二个es进程,就会在es集群中有2个node,然后那1个replica shard就会自动分配过去(自动加入集群),然后cluster status就会变成green状态(课程中并不需要启动两个节点)。
(3)快速查看集群中有哪些索引
语法:
GET /_cat/indices?v
结果:
|
health |
status |
index |
uuid |
pri |
rep |
docs.count |
docs.deleted |
store.size |
pri.store.size |
|
yellow |
open |
lagou |
WLGG7wBdQcyVcHq5ekoh4A |
5 |
1 |
8 |
0 |
28kb |
28kb |
|
yellow |
open |
test_index |
OsVa8bUARDCuSysT_Wkxbw |
5 |
1 |
0 |
0 |
650b |
650b |
|
yellow |
open |
.kibana |
5WyPl6qSQKa_6R5ZnRI7Dw |
1 |
1 |
1 |
0 |
3.1kb |
3.1kb |
(4)简单的索引操作
创建索引:PUT /test_index?pretty
返回结果:

删除索引:DELETE /test_index?pretty
返回结果:
4、商品的CRUD操作
(1)新增商品:新增文档,建立索引
语法:
PUT /index/type/id
{
"json数据"
}
实例:
PUT /ecommerce/product/1
{
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
结果如下:
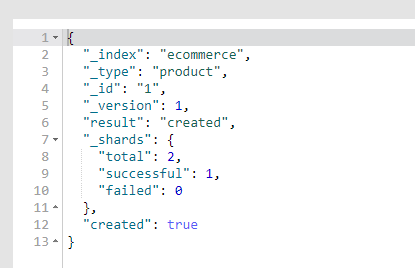
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1, # 版本号,涉及乐观锁
"result": "created", #结果(是否成功)
"_shards": {
"total": 2, #至少要写入primary shard,每个primary shard都是至少要写入一个replica shard中,但是我们这里只有一个节点,所以successful 结果为1,failed的结果为0
"successful": 1,
"failed": 0
},
"created": true # 是否成功创建,
}
es会自动建立index和type,不需要提前创建,而且es默认会对document每个field都建立倒排索引,让其可以被搜索
(2)查询商品:检索文档
语法:
GET /index/type/id
实例:
GET /ecommerce/product/1
结果是:

(3)修改商品:替换文档
语法:
PUT /index/type/id
{要替换的数据}
注意的是,这里的替换后,数据库中只存你所替换的数据,原数据全部丢失,所以,你只能把全部数据都带上,相当于覆盖.
实例
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
结果是:

和新增比较的话,_version,"created"改变了,其他都一样
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao"
}
然后: GET /ecommerce/product/1
结果如下,可 以看到,只剩下一个字段了.

如果是这样的话,id=1,就只有name这一个数据,再没有其他数据.可以看出,替换方式有一个不好,即使必须带上所有的field,才能去进行信息的修改
(4)修改商品:更新文档
语法:
POST /index/type/id/_update
实例:
POST /ecommerce/product/1/_update
{
"doc": {
"name": "jiaqiangban gaolujie yagao" # 这一句不能加逗号,因为是最后一个条件语句
}
}
结果是:

注意的是,这个的语句和SQL语句一样,最后一条语句时不能用","号(逗号)
(5)删除文档
语法:
DELETE /index/type/id
实例
DELETE /ecommerce/product/1
结果如下:

然后执行 GET /ecommerce/product/1 可以看到数据已经没有了
