一,Mutilindex多层索引的取值
1. 通过get_list自定义函数创建二维表格数据
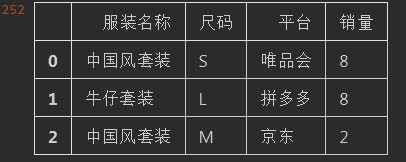
import pandas as pd import numpy as np np.random.seed(123) def get_list(items,lens = 300): return pd.Series(items).sample(n=lens,replace=True).to_list() df = pd.DataFrame({ "服装名称": get_list(["T恤","牛仔套装","中国风套装","西装"]), "尺码": get_list(["S","M","L"]), "平台": get_list(["唯品会","拼多多","淘宝","京东"]), "销量": get_list([2,5,8]) }) df.head(3)
2. 通过pivot_table透视表函数统计销量数据。并按照服装名称,平台,尺码指定行跟列的index
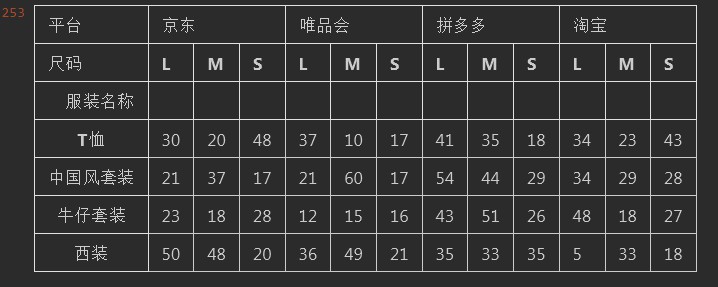
#%% df = pd.pivot_table( df, index= ["服装名称"], columns= ["平台","尺码"], values= "销量",#注意这里统计的只有一个销量,一定不要用列表。 aggfunc= sum #对销量做统计 ) df
3. 查看DataFrame的index行索引及columns列索引
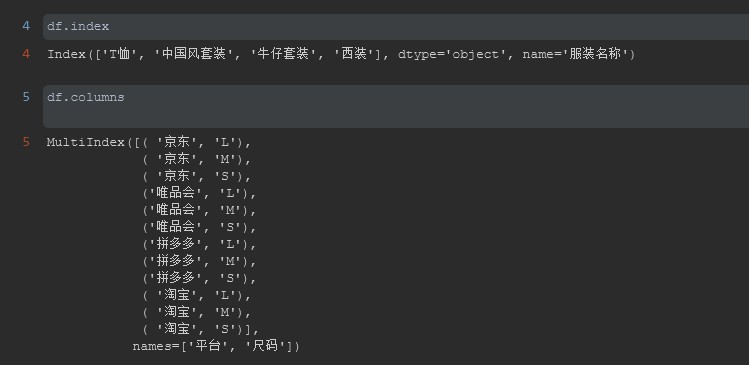
#%% df.index #%% df.columns
4. 对指定列名范围的取值
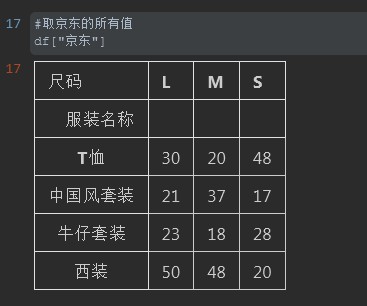
注释:这里我们直接把京东这一列包含的所有内容取出来。注意京东这列其实相当于Excel表中的单元格合并。那么下方包含"S","M","L"尺码的三列数据。如果df["京东"]的话会把这三列的值一并取出。
#%% #取京东的所有值 df["京东"] #%%
5. 通过掩码条件判断取出数据
#%% #取唯品会L型号销量大于30的所有值 df[df["唯品会"]["L"]>30] #%%

6. 每一个columns其实都是一个元组。我们可以通过元组来取出一组或者多组想要的数据
#%% #选择单个列数据 df[('京东', 'S')] #%% #选择多列数据(京东平台S码及唯品会平台L码的值) df[[('京东', 'S'),('唯品会', 'L')]] #%%

7. 通过swaplevel函数指定参数实现列名互换从而实现对数据的筛选
#%% #选出所有平台中所有L码的销量值 df.swaplevel(axis=1)["L"] #swplevel代表交换的意思。axis=1代表0列跟1列互换 #%%

8. 通过切片实现指定行索引及列索引的数据
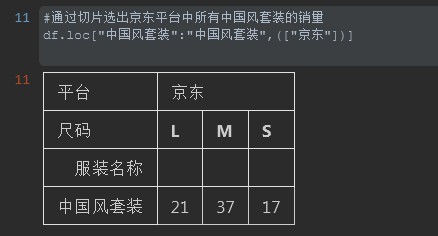
#%% #通过切片选出京东平台中所有中国风套装的销量 df.loc["中国风套装":"中国风套装",(["京东"])] #%%
9. 通过切片对指定行索引及列索引部分数据的切片操作。
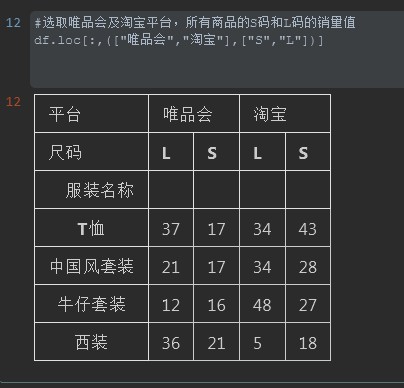
#%% #选取唯品会及淘宝平台,所有商品的S码和L码的销量值 df.loc[:,(["唯品会","淘宝"],["S","L"])] #%%
10. 通过slice类对列索引进行切片操作
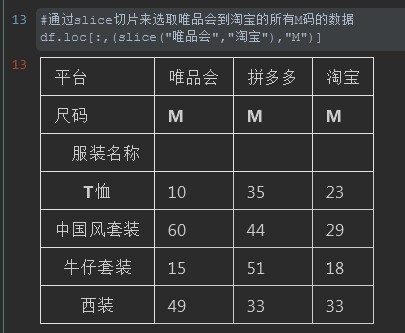
注释:slice()中双引号的元素间虽然写的时逗号,但是代表从第一个元素切片到第二个元素的意思。如果中间还包含其他元素,那么也会一并被切片进去。第二个逗号代表第二层指定的值。
#%% #通过slice切片来选取唯品会到淘宝的所有M码的数据 df.loc[:,(slice("唯品会","淘宝"),"M")] #%%
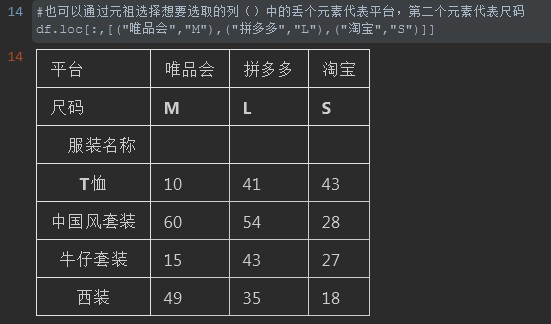
11. 通过多层元组的指定对列索引进行数据选取。
#%% #也可以通过元祖选择想要选取的列()中的丢个元素代表平台,第二个元素代表尺码 df.loc[:,[("唯品会","M"),("拼多多","L"),("淘宝","S")]] #%%
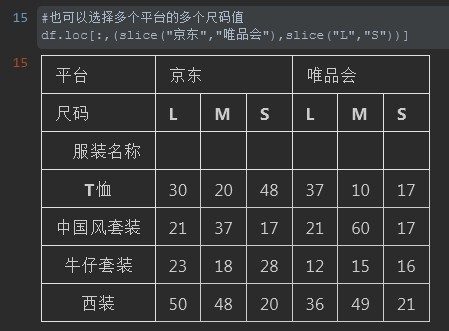
12. slice函数的使用不光可以对列名,也可以对第二层数据范围中值的指定也同样生效
#%% #也可以选择多个平台的多个尺码值 df.loc[:,(slice("京东","唯品会"),slice("L","S"))] #%%
13. 也可以直接对多个列名,类似于列表的方式指定筛选出指定列名下包含的所有数据
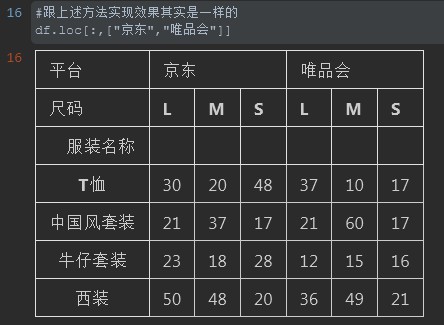
注释:以下方法同上述 df.loc[:,(slice("京东","唯品会"),slice("L","S"))] 其实效果是一样的
#跟上述方法实现效果其实是一样的 df.loc[:,["京东","唯品会"]] #%%