一、注解的使用:
1.元注解:
@Document : Javadoc工具会将此注解标记元素的注解信息包含在javadoc中,默认是不包含在里面的
@Target
@Retention
@Inherited : 可以继承
2.butterknife的原理:butterknife使用的是java的注解处理技术,也就是在代码编译的时候,编译成字节码的时候,在编译期间就已经处理好了各个view的初始化和相应的点击事件,
通过APT可以生成生成Java代码,生成Java代码是调用javapoet库生成的,而不是在运行期间去做的,并不是通过反射实现,整个注解是运行在CLSSS阶段的,所以性能优势是非常高的
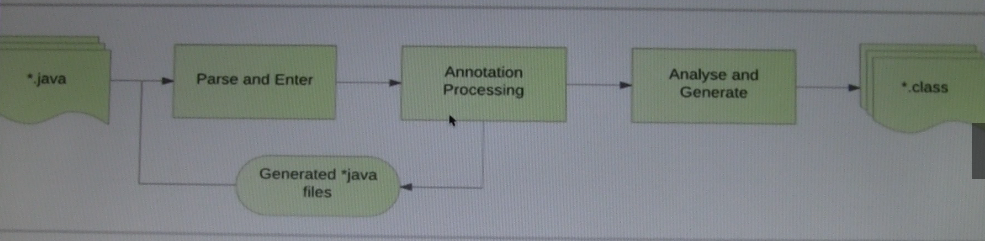
3处理注解的流程:
a.首先声明注解的生命周期为CLASS
b.ButterKnifeProcessor继承AbstractProcess类
c.再调用AbstractProcessor的process的方法
4.绑定view的时候,为什么不能private和static。
答:因为性能问题,如图我们我们把这个view设置成private,那么这个框架他就不能通过注解的方式来获取了,只能通过反射来获取,
此时不管你的性能有多快,都会影响性能。这是必须注意并且避免的。这也就是和其他注解方式不通的一点
5.ButterKnife.bind(this)必须在setContentView()之后调用,否则会绑定失效的
6.注解是如何实现的
1.process方法里面它会先调用findAndParseTargets(),这个方法里面创建了一个LinkHaspMap作为存储ID和view的,同时调用getElementsAnnotatedWith(),它主要是遍历所有的BindView的所有注解对象,得到相应注解以后调用parseBindView将他们转化,
这个转换过程中就包含ElementType可以获取view的对象,通过BindVIew.getAnnotation.value来获取ID的数值,把获取的ID数值和view保存在LinkedHashMap里面,这样view和ID就可以绑定到一起
然后里面有个方法来判断定义private或者static、或者包名以Android或者Java作为开头都会报出错误
7.findViewById是如何实现的:
process在生成java file文件之前会createBindingConstructor(),它在编译阶段可以把我们注解转换成findViewById、
onClick、onItemClick这些不同事件判断处理,处理完之后就通过addViewBing这个方法来最后完成findViewById、事件的点击等的实现。
@BindView(R.id.textview)
@OnClick
@OnItemClick
@ButterKnife.bind(this)
8.LinkHashMap和HashMap的区别
LinkHashMap : 是HashMap的一个子类,它存储是有序的。
HashMap : 它的存储是无序的。
LinkHashMap和HashMap处理速度:LinkHashMap遍历速度受实际数量影响,而HashMap遍历速度受容量的影响
9.守护线程: 主线程结束后,如果没有用户线程,守护进程也会自动结束,它比用户线程优先级低
用户线程:主线程结束后,守护线程也还会一直存活的。
----------------------------------------------------------------------------------------------------------------------------------------------------
二、OkHttp的全面用法:
1. Get的请求: 例子 请求百度
OkHttpClient client = new OkHttpClient();
HttpUrl httpUrl = HttpUrl.parse("www/baidu.com").newBuilder()
.addQueryParameter("city","beijing")
.build();
Request request = new Request.Builder()
.url(httpUrl)
.build();
Response response = client.newCall(request).execute();
2. 异步POST请求 FormBody
OkHttpClient client = new OkHttpClient();
FormBody body = new FormBody.Builder()
.add("name","xiaoming")
.add("age","18")
.build();
Request request = new Request.Builder()
.url("www/baidu.com")
.post(body)
.build();
Response response = client.newCall(request).execute();
3. 异步上传文件 MultipartBody
MediaType MEDIA_TYPE = MediaType.parse("text/x-markdown; charset=utf-8");
String path = Environment.getExternalStorageDirectory().getAbsolutePath() + "/nihao.txt";
File file = new File(path);
RequestBody requestBody = RequestBody.create(file,MEDIA_TYPE);
MultipartBody body = new MultipartBody.Builder()
----->上传字符时候需要加上setType特殊类型,否则无法上传成功
.addFormDataPart("filename", "filename", requestBody)
.build();
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder()
.url("www.baidu.com")
.post(body)
.build();
4.异步下载文件
String url = "https://img-my.csdn.net/uploads/201603/26/1458988468_5804.jpg";
final Request request = new Request.Builder().url(url).build();
Call call = mOkHttpClient.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
Log.d(TAG, "onFailure: 失败");
}
@Override
public void onResponse(Call call, Response response) throws IOException {
InputStream is = response.body().byteStream();
String path = Environment.getExternalStorageDirectory().getAbsolutePath()+"/shu.jpg";
File file = new File(path);
FileOutputStream fos = new FileOutputStream(file);
try{
byte[] buffer = new byte[1024];
int len = 0;
while((len = is.read(buffer)) != -1) {
fos.write(buffer,0,len);
}
fos.flush(); //文件的读写,这个需要多看看和学习
}catch (Exception e){
e.printStackTrace();
}
Log.d(TAG, "onResponse: --->下载完成");
}
});
二、同步和异步的区别
里面有个Dispatcher这个类来实现,它主要作用是维护请求的状态(同步和异步),并且维护一个线程池,用于执行请求
同步请求
同步请求发送请求之后,就会进入阻塞状态,Dispatcher(分发器)主要做两个事情:保存同步请求、移除同步请求,直到收到响应。
异步请求
异步请求放到线程池里面,Dispatcher类主要做三件事情:正在执行异步队列、等待执行异步队列、维护一个还有一个线程池
里面之所以有两个异步请求队列:当前运行的异步队列小于64时候,它就会被放入到正在运行的异步队列(runningAsyncCalls)中,然后去运行线程池,否则就是加入就绪缓冲队列(readyAsyncCalls)当中作为等待
三、缓存的原理以及实现
1.缓存原理:

2.缓存相关的字段
Expirse : 缓存失效的时间
Cactce-Contral : 控制缓存 缓存类型
private : 客户端可以去缓存
public : 客户端和代理服务器都可以缓存
max-age : 表示多少秒后失效(在服务端用的较多)
· no-cache : 通过服务验证码(304)是否能使用缓存
no-store : 代理和本地都不可以使用缓存,只能从服务器去拿数据
Last-Modified : 最后一次修改时间(比如只是添加一个空格,时间就不一样,所以就出现ETag这个关键字段)
ETag : 通过返回的Response返回数据比较里面两个内容是否一直
If-Modified-Since : 与Last-Modified成对存在的
If-None-Match : 与ETag成对存在的
3.缓存的机制
int maxSize = 10 * 1024 * 1024;
Cache cache = new Cache(new File("sd"), maxSize);
OkHttpClient client = new OkHttpClient.Builder().cache(cache).build();
Request request = new Request.Builder()
.url("http://www.qq.com")
.build();
Response response = client.newCall(request).execute();
String string = response.body().toString(); --------->如果你不去读取返回的Response的请求体,
下次在请求也还是网络请求,并不是缓存请求
if(response.isSuccessful()){
Log.i(TAG, "run: = " + response.networkResponse().toString());
Log.i(TAG, "run: = " + response.cacheResponse().toString());
Log.i(TAG, "run-------------------------------");
Response response1 = client.newCall(request).execute();
String string = response1.body().toString(); ------>这次再次请求就是缓存请求
if(response1.isSuccessful()){
Log.i(TAG, "run: = " + response1.networkResponse().toString());
Log.i(TAG, "run: = " + response1.cacheResponse().toString());
4. 缓存实现
CacheInterceptor : 缓存拦截器
CasheStrategy : 缓存策略(是用本地缓存还是网络缓存),networkResponse为空的时候执行cacheResponse,否则需要取网络请求
Cache : 缓存目录,这里面就有put get remove等方法进行对缓存的操控
四、多线程下载功能
1.关键的字段
Transer-Encoding : chunked : 无法拿到整个文件的长度
content-length : 访问文件的总长度的大小
Range : 可以访问服务器某一个字段的长度大小
2. 下载文件遇到的问题
文件存储的路径 : 检查是否有SD卡的路径
文件是否受损 : 通过拿到服务器的文件的MD5,然后去和你本地的MD5做对比观察是否相等,如果不相等说明文件已经受损
文件空间的大小 : 下载文件是否比剩余空间小,做一个判断
进度条的更新 :
数据的保存 :
五、Https使用
1.https加密的常见知识
对称加密: 秘钥是相同
非对称加密: 一个是公钥,一个是私钥,公钥只能用私钥去解,私钥只能用公钥去解
数字证书:
2.SSL/TLS的运行机制 :
a.客户端会告诉服务端证书(公钥)、数据加密算法、以及生成一个随机数
b.服务端接受之后对证书进行私钥解密,验证是否可信,如果成功,服务端会确认是使用加密算法、以及生成一个随机数给客户端
c.客户端再对服务端返回数据进行验证,验证通过之后就发送对称加密对数据进行加密处理,发送给服务端
d.服务端就会对称加密进行解析拿到数据
证书采用的是非对称加密,而数据传输采用的是对称加密
3.DNS讲解 : 域名解析
比如我去直接访问IP地址,它会抛出校验抛出的异常,connect请求连接时候添加HostnameVerifier这个接口里面的verify,直接返回为true,就可以跳过校验
class MyHostVerify implements HostnameVerifier() {
@Override
public boolean verify(){
手动可以去写校验方法
return true;
}
}
六、自定义拦截器
1.重写Interceptor这个类
public interface Interceptor {
Response intercept(Chain chain) throws IOException;
interface Chain {
Request request();
Response proceed(Request request) throws IOException;
Connection connection();
}
}
/**
* 重试拦截器
*/
public class RetryIntercepter implements Interceptor {
public int maxRetry;//最大重试次数
private int retryNum = 0;//假如设置为3次重试的话,则最大可能请求4次(默认1次+3次重试)
public RetryIntercepter(int maxRetry) {
this.maxRetry = maxRetry;
}
@Override
public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
System.out.println("retryNum=" + retryNum);
Response response = chain.proceed(request);
while (!response.isSuccessful() && retryNum < maxRetry) {
retryNum++;
System.out.println("retryNum=" + retryNum);
response = chain.proceed(request);
}
return response;
}
}
2.添加自定义拦截器
mClient=new OkHttpClient.Builder()
.addInterceptor(new RetryIntercepter(3))//重试
.addInterceptor(logging)//网络日志
.addInterceptor(new TestInterceptor())//模拟网络请求
.build();
3.addInterceptor(添加应用拦截器)和addNetworkInterceptor()的区别
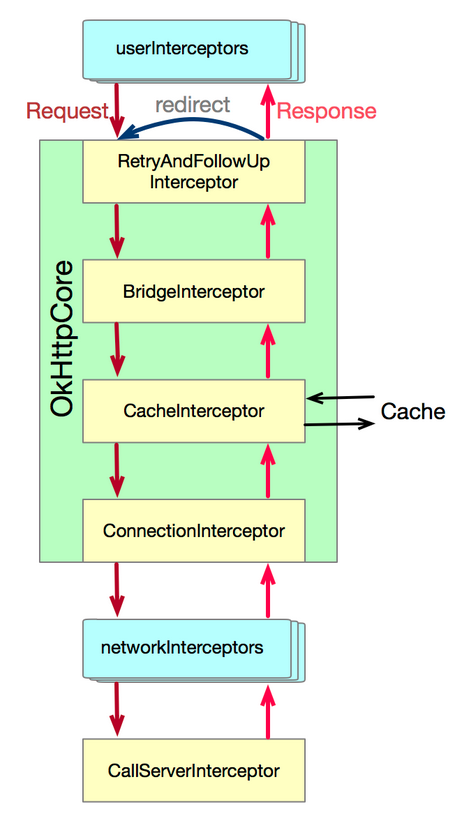
addInterceptor : 总是只调用一次,即使HTTP响应是从缓存中获取,不是从网络获取的
addNetworkInterceptor : 能够操作中间过程的响应,可以观察网络上传的数据
-------------------------------------------------------------------------------------------------------------------------------------------
一、StingUtils
二、Glide
三、ButterKnife
四、Indicator
五、MasterDesign使用
六、OkHttp
// okhttp,sniffer packet--->适用于测试人员抓包
debugCompile 'com.readystatesoftware.chuck:library:1.1.0'
releaseCompile 'com.readystatesoftware.chuck:library-no-op:1.1.0'
//okhttp,chrome sniffer packet---->适用于开发人员抓包
implementation 'com.facebook.stetho:stetho:1.5.0'
implementation 'com.facebook.stetho:stetho-okhttp3:1.5.0'
七、DrawerLayout的学习
八、BaseTitleActivity学习以及XML文件学习
九、EventBus的使用
十、AppBarLayout -----> app:layout_scrollFlags="scroll"
MagicIndicator indicator MagicIndicator
十一、Palette
十二、 这两个区别
//这里一定要调用childFragmentManager
adapter = new MusicUIAdapter(getActivity(), getFragmentManager());
adapter = new MusicUIAdapter(getActivity(), getChildFragmentManager());
十三、CardView框架
十四、 RecommentFragment
adapterWrapper = new LRecyclerViewAdapter(adapter);
adapterWrapper.setSpanSizeLookup(new LRecyclerViewAdapter.SpanSizeLookup() {
@Override
public int getSpanSize(GridLayoutManager gridLayoutManager, int position) {
// 先获取ItemType
int itemViewType = adapterWrapper.getItemViewType(position);
if (position<adapterWrapper.getHeaderViewsCount() || position>(adapterWrapper.getHeaderViewsCount()+adapter.getItemCount())) {
// f当前位置的Item是header,占用列数spanCount一样
return ((GridLayoutManager) layoutManager).getSpanCount();
}
return adapter.setSpanSizeLookup(position);
}
});
getSupportActionBar().setDisplayHomeAsUpEnabled(true);
RequestOptions需要学习